

新智元报道
新智元报道
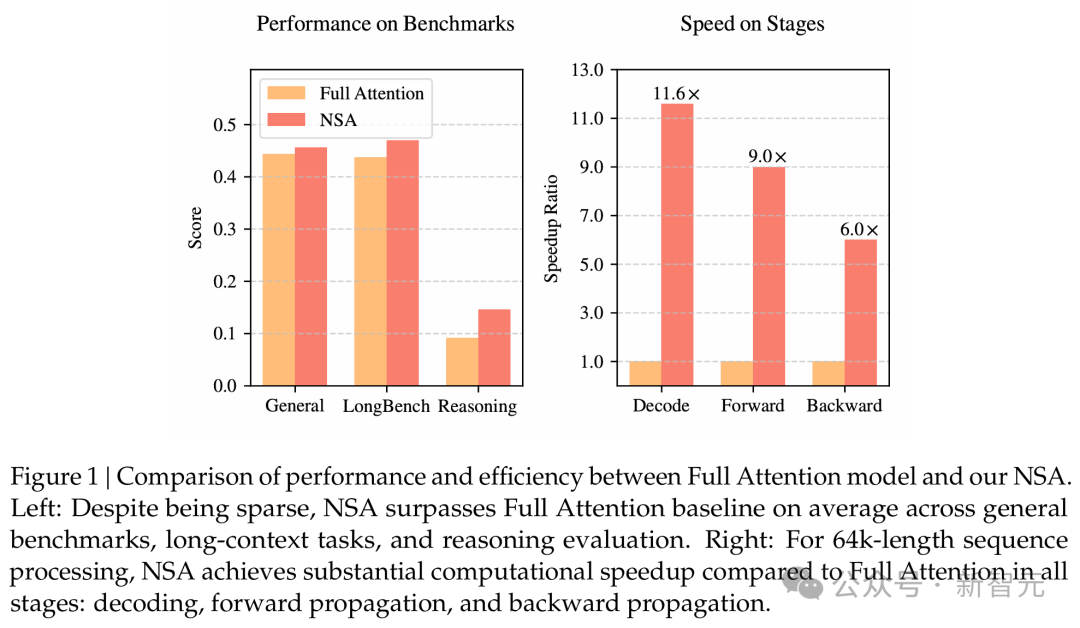
【新智元导读】DeepSeek联手两大机构祭出神作,再次惊艳全世界。创始人亲自率队,提出了革命性注意力机制NSA,在通用、长文本、思维链推理基准测试中,刷新SOTA碾压全注意力,很有可能,NSA是对Transformer注意力机制的重大优化。

-
动态分层稀疏策略 -
粗粒度的token压缩 -
细粒度的token选择


部署高效稀疏注意力机制的关键挑战
-
硬件对齐系统:优化块级稀疏注意力,使其充分利用Tensor Core并优化内存访问,从而实现平衡的算术强度。 -
训练感知设计:通过高效算法和反向传播运算符实现稳定的端到端训练,使NSA能够同时支持高效推理与完整训练流程。
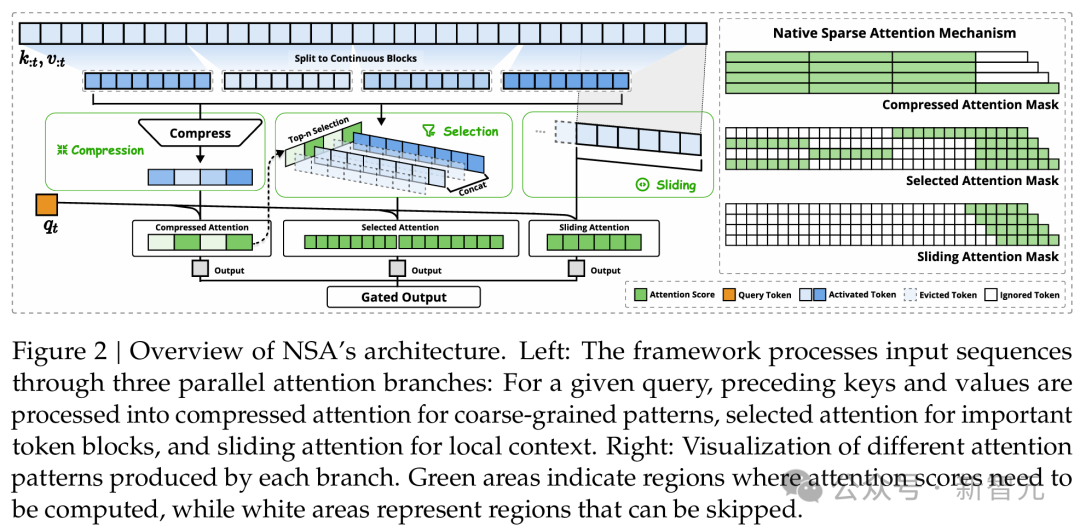
上图左:该框架通过三个并行的注意力分支处理输入序列。对于给定的查询,前面的键和值被处理成压缩注意力以用于粗粒度模式、选择注意力以用于重要token块,以及滑动注意力以用于局部上下文。 上图右:可视化每个分支产生的不同注意力模式。绿色区域表示需要计算注意力分数的区域,而白色区域表示可以跳过的区域。
方法概述
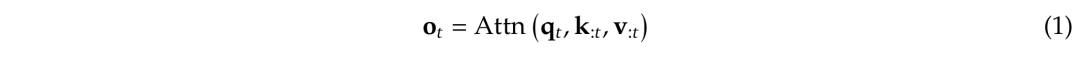
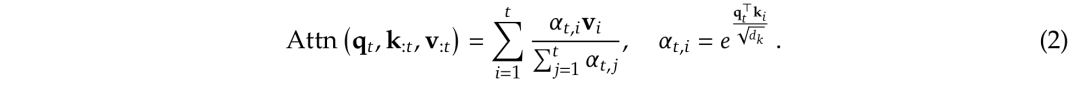
NSA的整体框架
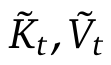 ,来替换方程1中的原始键值对k_:𝑡,v_:𝑡,并根据每个查询q_𝑡进行优化。
,来替换方程1中的原始键值对k_:𝑡,v_:𝑡,并根据每个查询q_𝑡进行优化。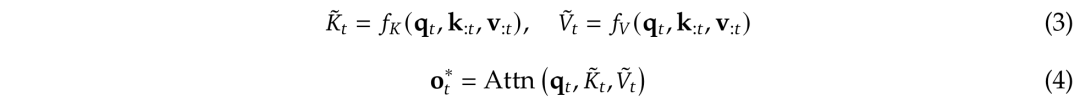 是基于当前查询q_𝑡和上下文记忆k_:𝑡,v_:𝑡动态构建的。,并将它们组合如下:
是基于当前查询q_𝑡和上下文记忆k_:𝑡,v_:𝑡动态构建的。,并将它们组合如下:
 是与策略c对应的门控得分(gate score),通过MLP和sigmoid激活函数从输入特征中学习得到。
是与策略c对应的门控得分(gate score),通过MLP和sigmoid激活函数从输入特征中学习得到。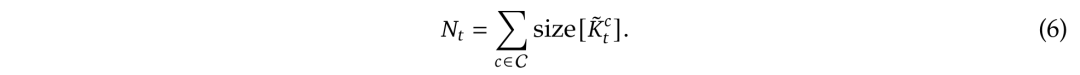
关键算法组件
-
token压缩:将连续的键或值块聚合为块级表示,得到压缩后的键和值。压缩表示能够捕获较粗粒度的高级语义信息,并减少注意力机制的计算负担。 -
token选择:用于识别并保留最相关的token,同时减少计算开销。其中,按块选择在空间连续的块中处理键和值序列:首先将键值序列划分为选择块;为每个块分配重要性分数,识别出最重要的块以用于注意力计算。而Top-𝑛块选择在获得选择块重要性得分后,按块重要性得分排序,选择top-𝑛稀疏区块中的token,被选中的键和值会参与注意力计算。 -
滑动窗口:专门的滑动窗口分支,明确处理局部上下文,使得其他分支(压缩和选择)可以专注于学习各自的特征,而不会被局部模式所干扰。
硬件优化的内核设计
-
查询加载(Grid Loop):内核按GQA(Grid Query Attention)组加载查询。每个GQA组包含共享相同稀疏键值块的查询头。这种方法减少了冗余的键值传输,提高了内存访问效率。
-
键值获取(Inner Loop):在每个查询加载后,内核获取相应的稀疏键值块。这些键值块存储在高带宽内存(HBM)中。内核将这些键值块传输到片上静态随机存取存储器(SRAM)中,以进行注意力计算。
-
注意力计算:内核在SRAM中执行注意力计算。绿色块表示存储在SRAM中的数据,蓝色块表示存储在HBM中的数据。这种内存层次结构优化了数据传输和计算效率。

-
以组为中心的数据加载:对于每个内部循环,在位置𝑡加载该组中所有头部的查询𝑄 ∈ R[ℎ, 𝑑_𝑘],以及它们共享的稀疏键值块索引I。 -
共享KV获取:在内部循环中,按顺序加载由I𝑡索引的连续键值块到SRAM中,作为𝐾 ∈ R[𝐵_𝑘, 𝑑_𝑘]和𝑉 ∈ R[𝐵_𝑘, 𝑑_𝑣],以最小化内存加载,其中𝐵𝑘是满足𝐵_𝑘 | 𝑙′的内核块大小。 -
网格外部循环:由于内部循环的长度(与选择的块数𝑛成比例)对于不同的查询块几乎相同,我们将查询/输出循环放入Triton的网格调度器中,以简化和优化内核。
革命性NSA,碾压全注意力
-
通用基准性能 -
长文本基准性能 -
思维链推理性能

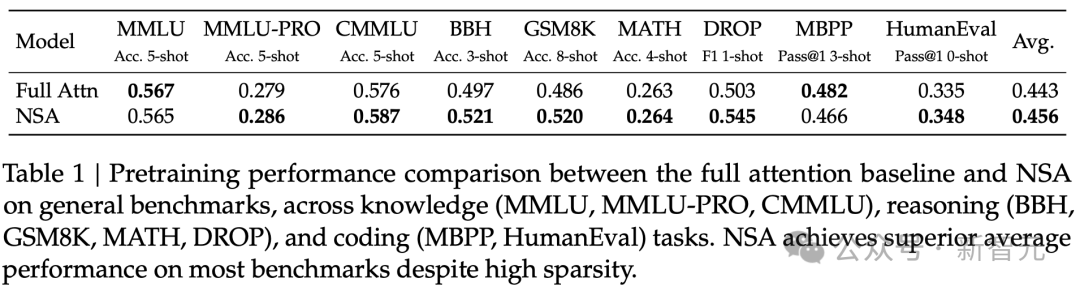
通用基准评估
长文本评估


思维链推理评估

-
预训练的稀疏注意力模式,能够有效捕获复杂数学推导中至关重要的长程逻辑依赖关系;
-
架构采用硬件对齐设计,在增加推理深度的同时保持足够的上下文密度,避免了灾难性遗忘。

64k上下文,前向传播9倍速飙升
训练速度

解码速度

讨论
替代token选择策略
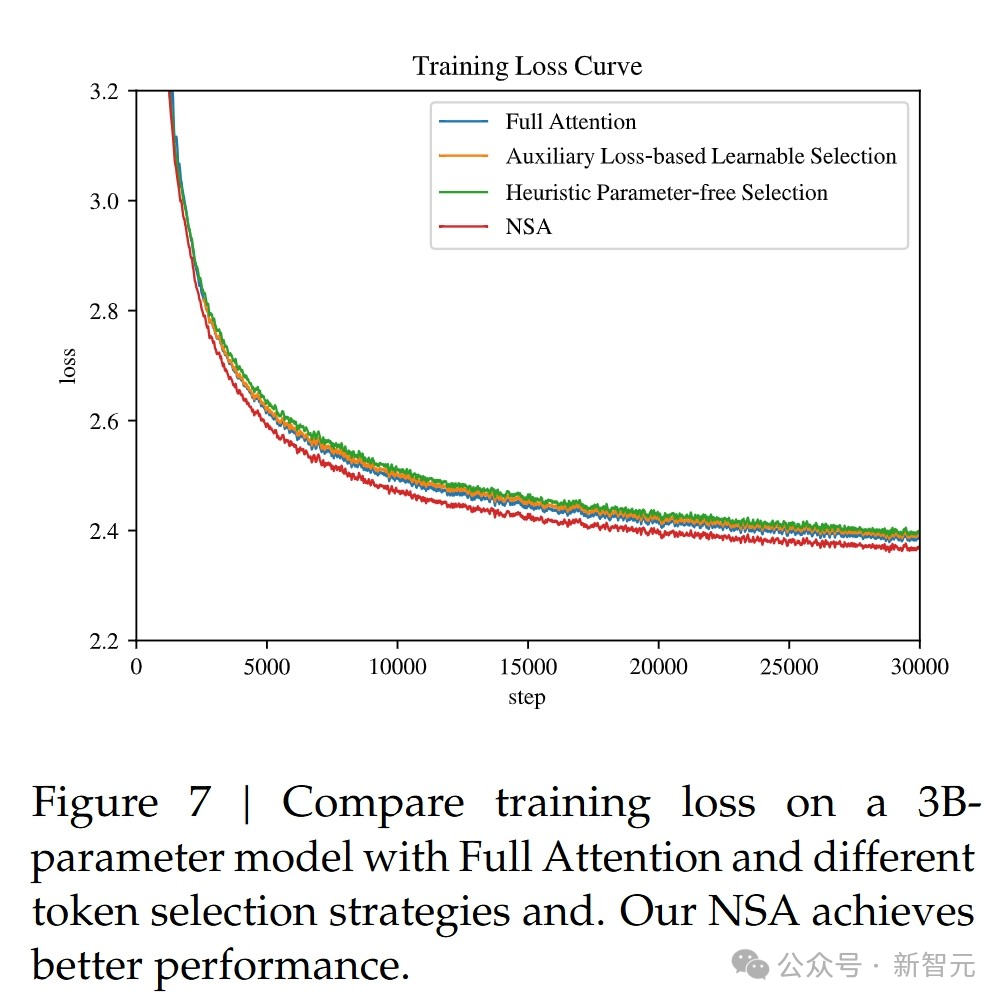
可视化

结论
(文:新智元)