


刚刚,马斯克发布了“地球最聪明的AI”——Grok3。
从测评数据上看,这个模型很强,几乎所有领域都大幅领先其他模型,就连Grok-3-mini的表现都已经超过了其他的大模型。
国外知名大模型排行榜ChatBot Arena也宣布Grok 3登顶了,为这个成绩背书。
但也有不少人,对Grok3很失望。
因为Grok 3这次走得仍然是“大力出奇迹“路子,马斯克堆了20万张卡,用了比DeepSeek多几十倍的模型计算量,但与现有模型的性能没有拉开质的差距。
这似乎也从侧面印证了Ilya说的预训练到头的结论。
/ 01 /
AI大佬亲测:Grok3思考能力与o1-pro相当,
强于DeepSeek-R1
在这次发布会上,马斯克发布了两套模型:Grok-3和Grok-3 Reasoning(推理模型)。
根据此前介绍,Grok-3其由一个包含约 20 万个 GPU 的数据中心训练,计算能力是上一代模型Grok 2的“10倍”,且使用了扩大的训练数据集。
正如马斯克所说,Grok3是“地球最聪明的AI”。在测试成绩上,Grok-3的表现好于OpenA、DeepSeek发布的同类模型。
在Math(数学)、Science(专业知识)和Coding(编程)任务上的测评结果,Grok基座模型分别领先DeepSeek-v3 Geminit和GPT4o。
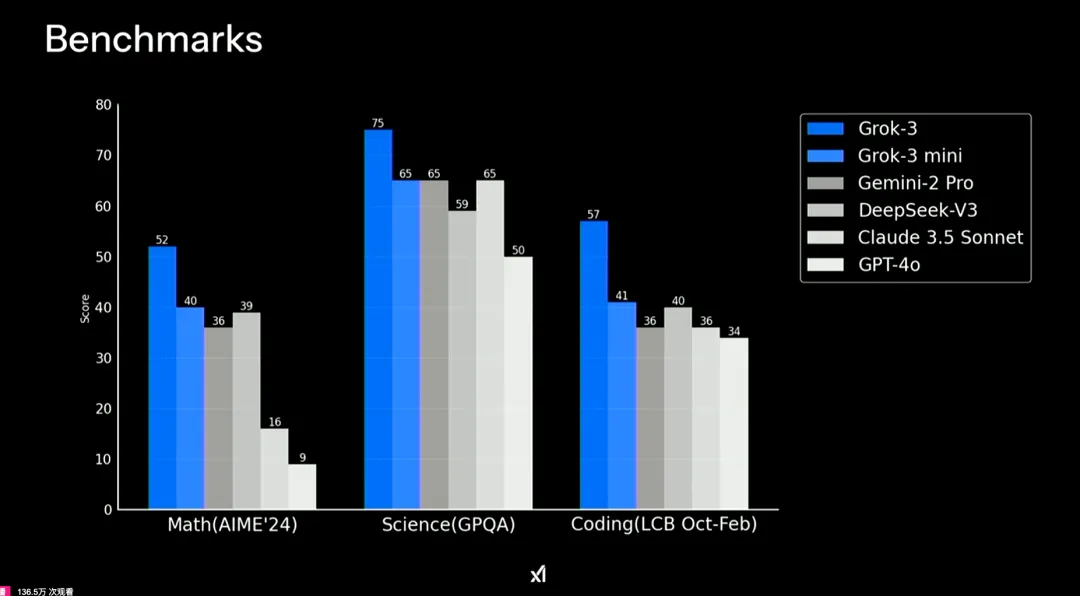
其中,在AIME’24数学能力测试中,Grok-3取得了52分,明显高于DeepSeek-V3的39分。而在GPQA科学知识评估中,Grok-3以75分的优异成绩领先DeepSeek-V3的65分。
在推理模型上,Grok-3 Reasoning在benchmark 上得分也高于OpenAl+的o1/o3系列和deepseek-R1模型。

发布后,Grok 3就迅速登上了在Chatbot Arena LLM排行榜上的榜首,而且全类型都是第一。
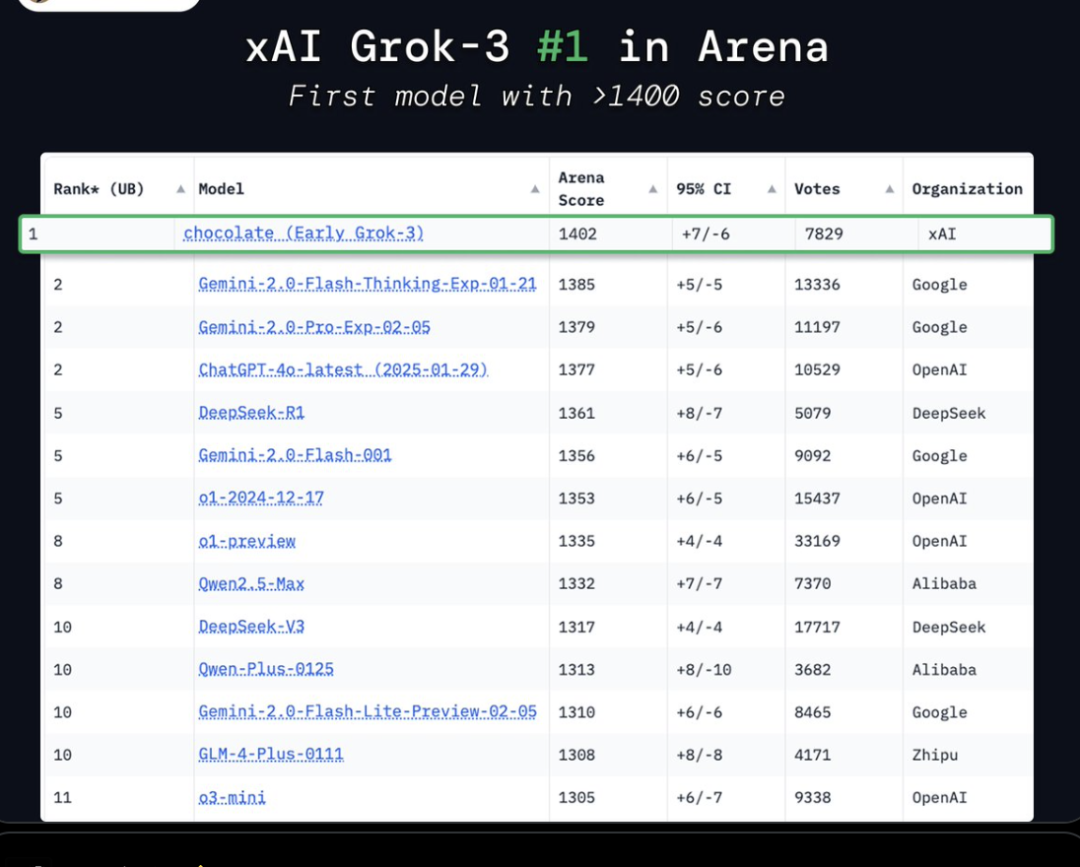

此前,Grok 2排在20名左右,落后于OpenAI、DeepSeek、谷歌、阿里Qwen、智谱、阶跃星辰等一众国内外AI公司的模型。
在发布会结束后,AI大神Andrej Karpathy发布了一则推文称,其提前测试了Grok3,Grok3的思考能力大约处于o1-pro的水平,略优于DeepSeek-R1和Gemini 2.0 Flash Thinking。
第二,除了模型性能的领先,思维链是Grok 3的另一大亮点。
Grok3升级的地方是思维链,其意义在于实现了从“执行指令”到“主动思考”的质变。通过1.8万亿参数的混合专家模型(MoE),它能够像人类专家一样拆解复杂问题。
比如,当Grok 3被问及”如何设计火星移民基地的能源系统”时,AI没有直接给出方案,而是逐步拆解问题:先分析火星日照强度,再计算光伏板铺设面积,接着评估核能备用方案,最后整合建筑布局与储能需求。
不过,Grok3会对模型的思考过程进行模糊化处理。对此,马斯克给出的解释是,防止被其他对手抄袭。
第三,在这次发布会上,马斯克还发布了一个Agent工具——Grok DeepSearch。
这是xAI对标OpenAI深度研究工具的产品。DeepSearch通能够生成针对各种研究性/查找性问题,扫描互联网和X平台上的信息生成高质量回答,类似于你在互联网上的文章中可能找到的答案。
Andrej Karpathy对这一功能的评价是:大约在Perplexity DeepResearch功能的水平,但尚未达到OpenAI最近发布的“深度研究”水平,后者给人感觉更全面、更可靠。
/ 02 /
Scaling laws要失效了?
看完Grok 3的发布会,大部分人都有一个疑惑:Scaling laws还存在吗?
原因很简单,马斯克说服了投资人搞了十万卡进行预训练,现在更是升级到了二十万卡。但Grok 3的能力与现有模型的性能没有拉开。
目前,xAI有全球最大的Al训练集群Colossus,搭载10万个NVIDIA Hopper GPU(现在提升至20万卡),Grok 3就是在Colossus上训练出来的,这是Grok3最大的竞争力。
对比之下,根据市场人士透露,幻方真实的数字大概就在1万多张,而且主力还是A100和H800。
也就是说,马斯克堆了10万张卡,用了比DeepSeek多几十倍的模型计算量,只换来了20%的性能提升。
这基本上可以印证Ilya说的预训练到头的结论了。
根据OpenAI最新发文,GPT-4.5会是他们最后一个非推理模型,也从侧面说明了预训练的Scaling Law已经到了一个瓶颈。
而Grok3升级的思维链,本质上还是对目前主流技术路线的跟随,在预训练已经难以突破的情况下,通过提高test-time compute(测试时间计算)的方式提升模型表现。
在技术路线没有太大突破的情况下,依靠提升模型参数和通用能力来构建差异化优势变得越来越困难。换句话说,OpenAI等头部模型的护城河正在不断缩小。
比起Grok 3,马斯克的工程能力,倒给人留下了更深刻的影响。
在这次发布上,马斯克透露,Colossus已经从10万卡提升到20万卡,而这仅仅花了92天时间。
这样的速度还是很吓人的,也延续了马斯克雷厉风行的办事效率。当初,在建设超算中心“Colossus”的时候,也不过只花了122天,而业内平均建设周期需要4年。
之前红杉美国合伙人David Cahn曾提到过一个观点:
算力基建效率,将成为赢得AI下一轮竞争的关键条件。
这个逻辑很简单,建设一个庞大的数据中心,是一项混乱而复杂的业务,不仅需要购买足够的土地、钢铁和电力,还需要完成从钢和混凝土,到工业部件和GPU安装漫长的建造过程。
漫长的建设周期,给AI的竞争带来了更多变量。
无论是探索智能,还是应用智能,虽然短期有质疑,中长期的算力需求也会爆炸,这也解释了为什么马斯克从第一性原理出发,xAI 坚持扩建集群。
从这个角度上说,相比Grok3模型的微弱领先,Colossus或许才是马斯克竞争AGI最大的底气。
文/林白 树一
PS:如果你对AI大模型领域有独特的看法,欢迎扫码加入我们的大模型交流群。

(文:乌鸦智能说)