

这段时间DeepSeek确实是太火了。
但说实在的,火有火的道理,确实是好用。
那么问题来了,铺天盖地的DeepSeek推荐,我过年回家,村里的大妈都用上了,DeepSeek官方的算力严重不足。
每次我打开DeepSeek官网想用一下,问第一个问题还能回答,第二个问题就用不了了,不知道你们有没有遇到。
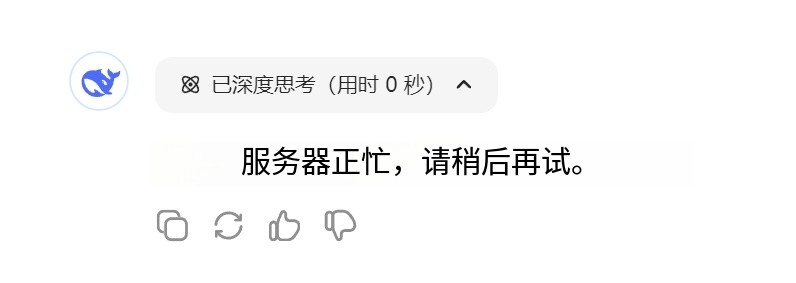
无情的提示我服务器繁忙。
官方的API也是直接用不了,后来API权限都不往外放了。
好在DeepSeek是开源的,所以也能有别的渠道可以使用。
今天给大家推荐两种免费的使用方式。
一个是用4090显卡自己部署DeepSeek R1模型,项目是开源的。
另一个是直接用问小白,现在是免费放量给大家使用。
有硬件条件想自己尝试动手部署的可以试下第一种,不想麻烦或者新手小白直接无脑选择问小白就可以了。
一、通过KTransformers本地部署
KTransformers主要解决的是优化了LLM的推理,就像DeepSeek R1,本来要8张H100才能推的动,现在只需要一张4090显卡就可以了。
下面这是需要的硬件配置。
显存占用:仅需 14GB VRAM(显存)。
内存占用:需要 382GB DRAM(内存)。
想自己跑起来,只有4090的显卡其实还不行,还得有512G的运行内存。
如果这些条件都满足的话,那你可以试着玩一玩了。
为什么只要4090就能推得动DeepSeek R1?
1. 模型量化技术
KTransformers 支持多种量化格式,通过对模型进行量化,可以显著减少模型参数存储所需的显存空间。
2. 专家卸载和选择策略
-
专家计算卸载:这种策略与 DeepSeek 的架构完美对齐,能够在有限的显存条件下实现最佳效率。
-
选择性专家激活:根据离线配置文件的结果,KTransformers 可以选择更少的专家进行计算。
3. 多 GPU 支持与并行计算
项目链接
https://github.com/kvcache-ai/ktransformers
但是讲实在的,想完全部署好也挺麻烦的,前几天看到群友推荐了一个平台叫问小白,就一直在用,今天恰好也推荐给大家。
二、通过问小白直接使用
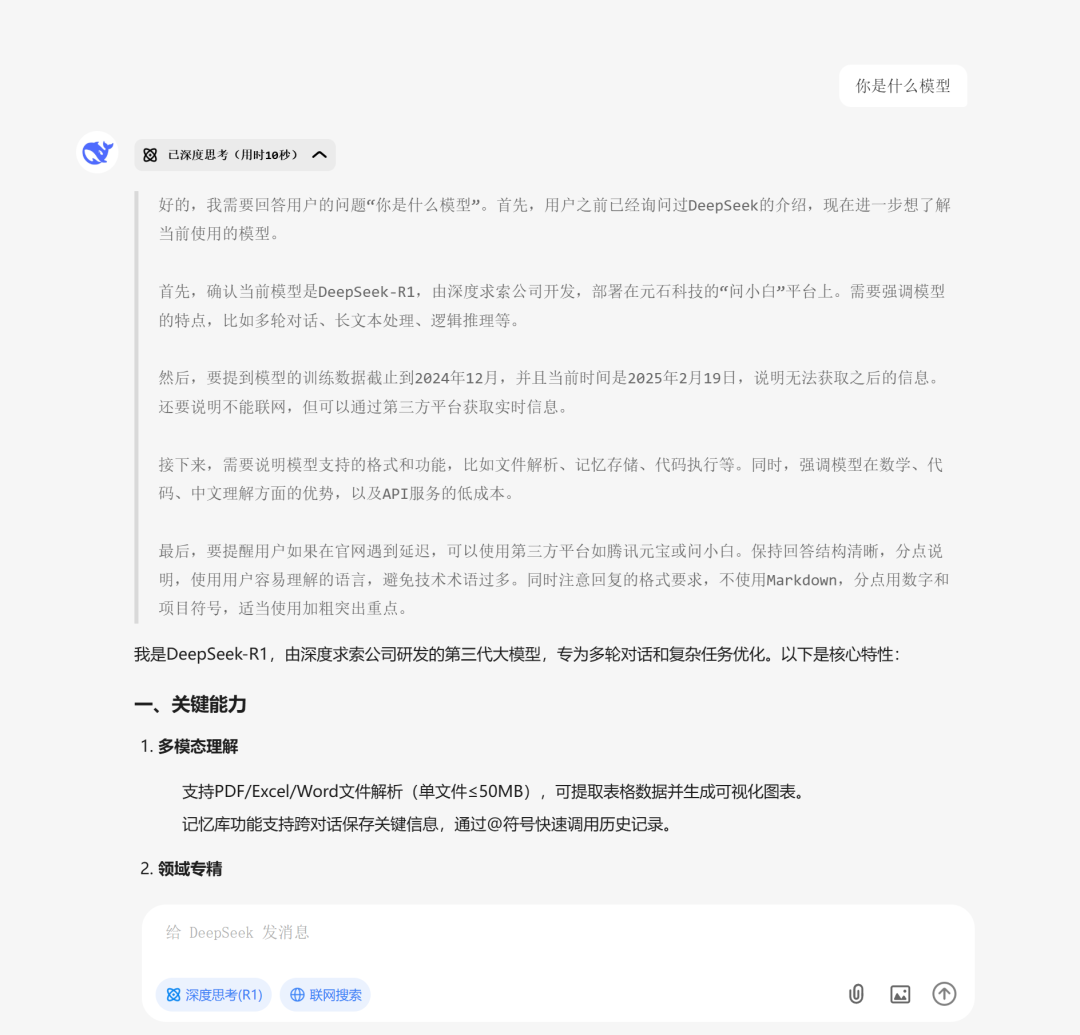
整个的使用页面可以说是跟官方版本的一模一样,非常的简洁。
大家最关心的一点我猜到了,它是免费的,所以我也在用。
这个月直接没续费GPT的订阅。
但也有不同的地方,它回答的真的太快了,不需要在那排队等。
至于联网搜索功能,大家也不用担心没有,而且还做的很好。
今天攻略了一下,问小白在帮用户做高质量信息获取方面非常专业,所以积累了非常多的联网搜索经验,搜索极速、丰富、精准,技术架构也非常的成熟稳定。
自己部署的话可能要搭搜索系统,直接用的话就省了这一步了。
市面上其实最近很多家都接了DeepSeek,我感觉大家也用的迷迷糊糊的。
就像微信灰度测试的,把微信里接入了DeepSeek,我试了好多次,就是不回答。
问小白体验下来,给我的感觉就是“快”!
其他软件相当一部分算力不足,导致直接不回答,还有一部分就回答的很慢,要四五秒甚至十几秒才会出来第一个token,而问小白只需要1-2秒就会开始输出了。
问小白本身就有自研MOE大模型优势,2023年的时候就在国内率先使用了MOE模型架构,所以也对DeepSeek的MOE模型非常熟悉,这也使得问小白能在这一波对决中胜出。
问小白给我的另一个感觉是实在。
免费给大家用已经很好了,但是很多营销号一直在讲DeepSeek到底怎么用才更好,只有问小白告诉我:
“对复杂提示词说NO!只需简单表达,R1比你更懂你想要的。”
确实是这样,这也是我想给大家讲的。
用DeepSeek跟用GPT是一样的,只要模型够强,提示词其实并不需要那么复杂。
我们平时写复杂的提示词是为了固定输出格式,其实咱们平时用的时候根本没必要到处去学提示词。
大道至简,想用好DeepSeek,写提示词的秘诀就是把问题描述清楚。
肯定有人不喜欢用网页,或者想外出不带电脑的时候也在手机使用。
问小白的APP也上线了,大家也可以直接在应用商店去下载使用,页面也是同样的简洁,速度也是依旧的快。
网页版使用链接
https://www.wenxiaobai.com/
如果你还不知道怎么用DeepSeek,或者想跟大家交流下如何使用,可以加一下问小白的官方群聊。

(文:开源AI项目落地)