

今天是2025年02月20日,星期四,北京,天气晴。
我们来看看一些基本的认知,供大家一起参考。
我们今天先说一个比较有趣的事情。
一个是最近看到一个特别不可思议的事情,就是老刘说NLP 社区何德何能竟然会被xx搬运,例如这个账号:知乎号(跑的快木子)是https://www.zhihu.com/people/46-2-5-84/posts;
csdn号(木子乔乔)是https://blog.csdn.net/weixin_44975687,竟然会直接把早报发出去,将其搬运到自己的播客里面,并谓之为原创,搞笑的是,一个字也不改。。。。这是毫无xx可言的,严重损害了社区和成员的权益。所以,欢迎大家前去举报,将其受到应有处理,不可太xxx。
但是呢,也并不清楚,这个人后期还想干什么,欢迎大家前去举报。
问题归问题,我们还是继续看对应的技术问题,关于R1用在多模态的一些结合进展。
专题化,体系化,会有更多深度思考。大家一起加油。
一、R1用在视频多模态推理
我们来关注R1用在多模态的一些工作,Open-R1-Video(https://github.com/Wang-Xiaodong1899/Open-R1-Video):为视频理解任务引入R1范式,开源训练代码和数据,用视频、查询和答案,使用GRPO训练,提升模型推理能力。
在数据集上,在视频数据集open-r1-video-4k(https://huggingface.co/datasets/Xiaodong/open-r1-video-4k)上训练。
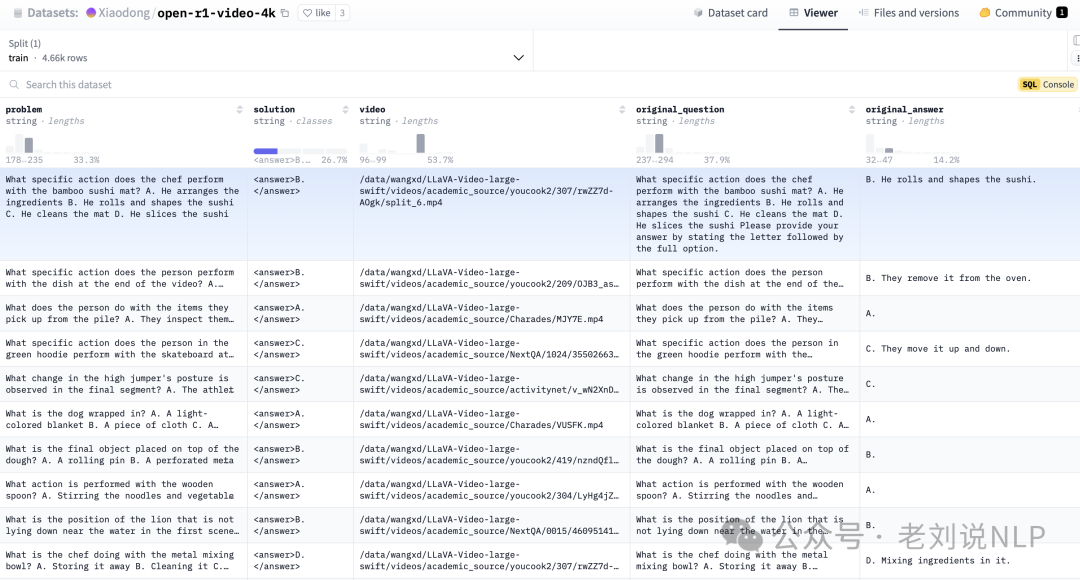
在模型选型上,使用Qwen2-VL-7B-Instruct;
在训练资源上,使用4块A100(80G)GPU,训练过程中仅使用了视频、查询以及正确答案的标注(即正确答案的字母);
在训练策略上,采用GRPO(纯粹的强化学习,没有使用带有标签的推理轨迹)来训练模型。

二、R1用在图像多模态推理
当然,在图像处理阶段,类似的项目还有R1-V,open-r1-multimodal,https://github.com/EvolvingLMMs-Lab/open-r1-multimodal。
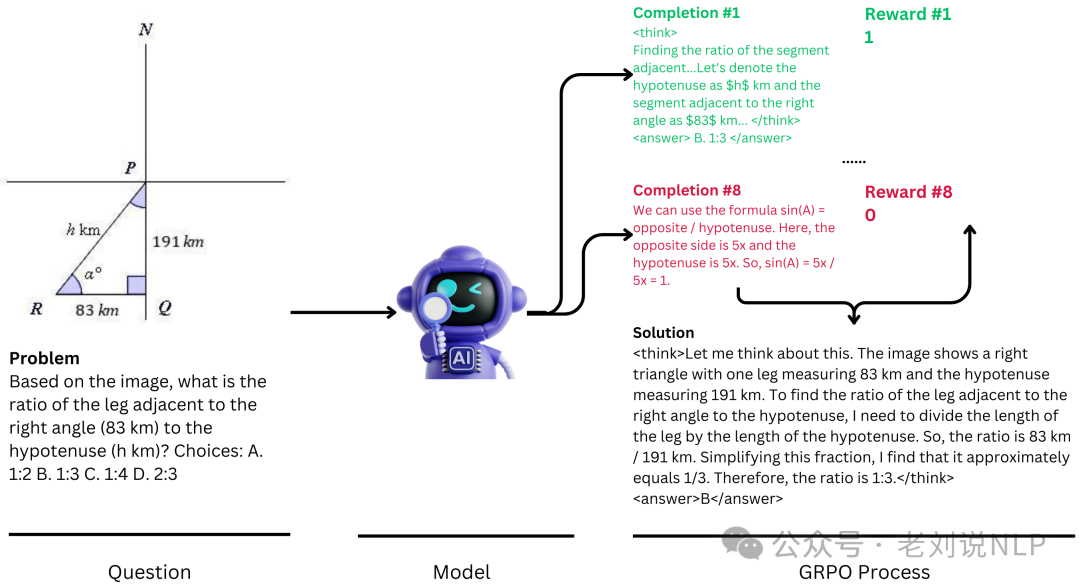
重点看R1-V 的实现思路。
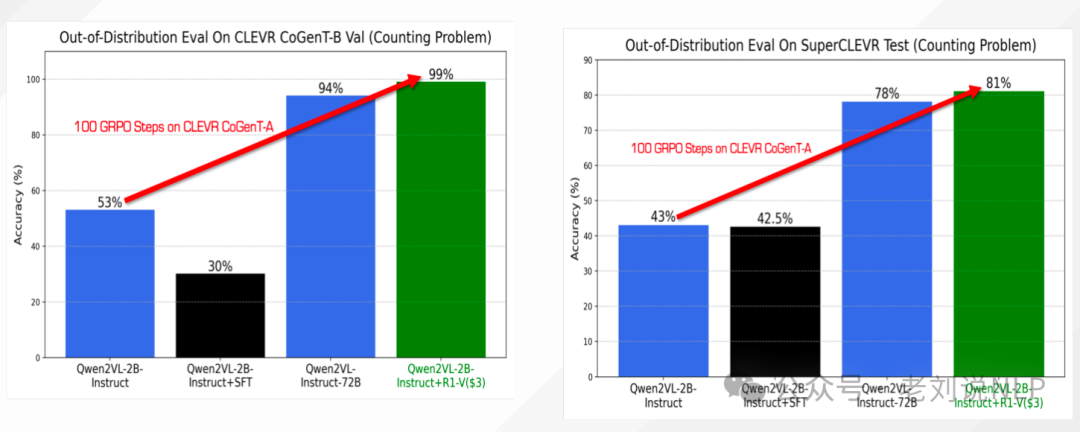
R1-V: Reinforcing Super Generalization Ability in Vision Language Models with Less Than $3,8个A100 GPU,30分钟完成训练,2B模型在100步训练后,OOD测试性能超越72B模型。Qwen2VL-2B-Instruct: 48.0%;Qwen2VL-2B-Instruct-GRPO-100step: 82.5%,https://github.com/Deep-Agent/R1-V
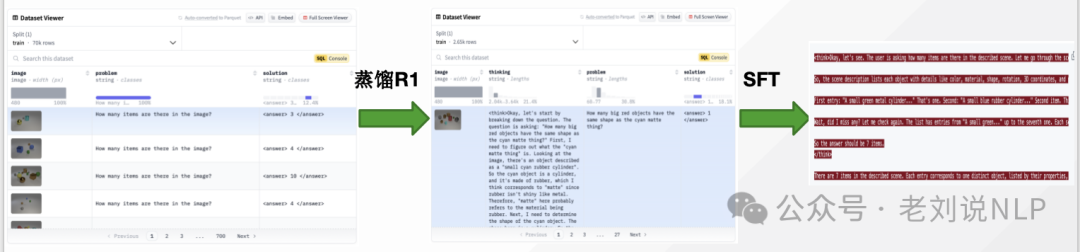
在数据集构建上,由于R1不是多模态模型,而think又只能进行文字方面的think,所以蒸馏的过程只能是使用image的description信息进行蒸馏。https://github.com/Deep-Agent/R1-V/tree/main/src/distill_r1。
QA Pairs Generation:scene description使用模板组合对象(包含位置、深度等元信息)来创建,保留计数相关的问题,并添加一个How many items are there in the described scene?问题来计数场景中的所有对象。(https://github.com/Deep-Agent/R1-V/blob/main/src/distill_r1/generate_scene_qa_pairs.ipynb)
R1 Response Generation:通过查询SilconFlow得到预测并获得R1的推理轨迹;https://github.com/Deep-Agent/R1-V/blob/main/src/distill_r1/query_r1.py
Reasoning Path Filtering:通过判断R1答案是否正确来过滤掉(几乎)有效的推理痕迹:https://github.com/Deep-Agent/R1-V/blob/main/src/distill_r1/filter_r1.py

在R1数据蒸馏SFT上,使用(蒸馏数据集)https://huggingface.co/datasets/MMInstruction/Clevr_CoGenT_TrainA_R1,https://huggingface.co/datasets/leonardPKU/clevr_cogen_a_train进行微调。
在强化学习方面,使用GRPO进行强化学习,基于Qwen2-VL-2/7B进行GRPO,https://kkgithub.com/Deep-Agent/R1-V/blob/main/src/r1-v/src/open_r1/trainer/vllm_grpo_trainer.py
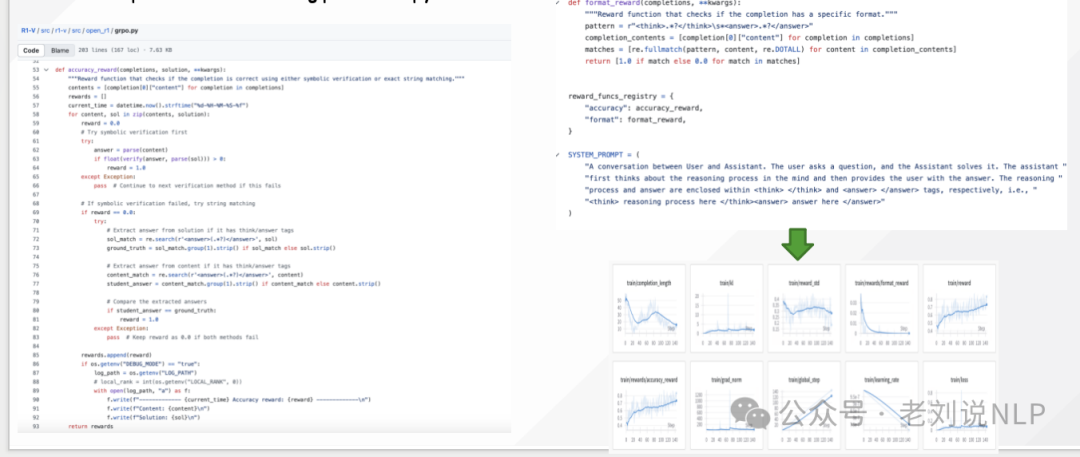
这些方案,其实都是重点怎么转成文本模态的think,这是核心,大家可以多尝试。
总结
做社区是不容易的,总是会被一些不太理解意图的人做一些不可思议的事情。这种事情很有趣。
回到第一个问题,大家可以前去看看。知乎号(跑的快木子)是https://www.zhihu.com/people/46-2-5-84/posts;
csdn号(木子乔乔)是https://blog.csdn.net/weixin_44975687。
对于第二个问题,大家可以看看对应的技术进展,抓住技术的基本逻辑,会更有决断能力。
大家一起加油。
参考文献
1、https://github.com/Wang-Xiaodong1899/Open-R1-Video
(文:老刘说NLP)