机器人前瞻2月22日报道,昨夜,美国人形机器人独角兽Figure AI重磅推出了一款通用型视觉语言动作(VLA)模型——Helix,将感知、语言理解与学习控制统一,克服了机器人技术领域的多项长期挑战,让两个人形机器人能够听从语音指令,互相帮助,互相理解,搭伙干家务活儿。
Helix实现了一系列首创:1)首次实现直接控制整个人形机器人上半身;2)是第一个同时在两个机器人上运行的VLA;3)只需按照自然语言指令,就能拿起几乎任何小型家居物品,哪怕它从未见过;4)使用一组神经网络权重来学习所有行为;5)可在嵌入式低功耗GPU上运行,能立即进行商业部署。
在Figure分享的视频中,人类当面说出整理杂物的要求后,两个机器人在从未见过这些物品的情况下,通过推理能力,能够协作将这些物品摆放归位,把鸡蛋、番茄酱等需要冷藏保鲜的放进冰箱,把水果放进果盒,把零食收进抽屉里。
两个机器人传递物品时指尖相触的刹那,被网友调侃像是复刻世界名画《创造亚当》里亚当与上帝伸手名场面。

网友们立即开始催进度:什么时候能卖?我已经想好让家用机器人拿快递、搬杂货、收拾饭后残羹、拿吸尘器做清洁、拖地叠衣服了。
也有一些网友因为两个机器人交接物品后互相对视的微妙氛围,感到不寒而栗。

值得一提的是,就在2月5日,Figure的创始人兼CEO Brett Adcoc在推特上发布了一条帖子,宣布终止与OpenAI的合作协议,并表示Figure在完全自主研发的端到端机器人AI方面取得了重大突破,接下来的30天内展示一些人们从未在人形机器人上见过的东西。
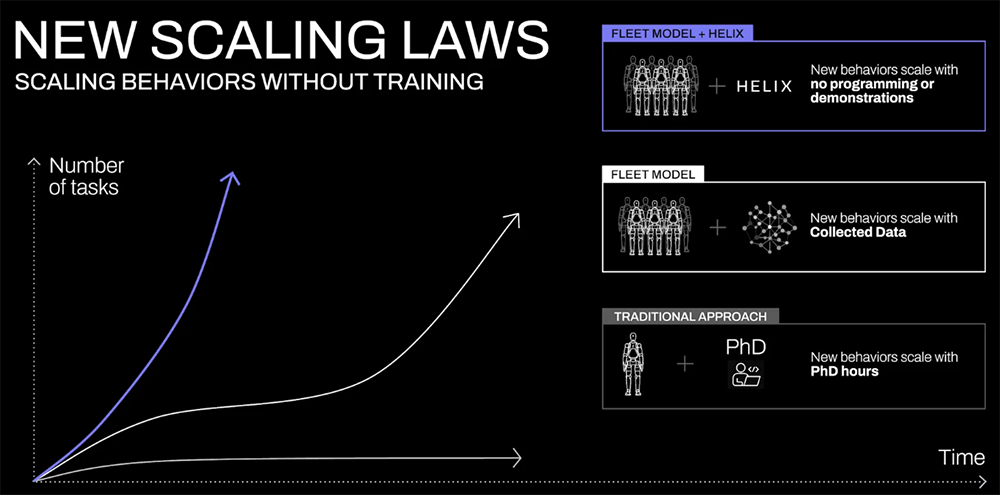
而今天,据Brett Adcoc介绍,团队花了一年多的时间研发出了Helix,做到了让人形机器人不需要经过任何训练、代码,就能抓取几乎任何家庭用品。
英伟达高级研究科学家、通用具身智能体研究实验室负责人Jim Fan也在社交平台上转发夸赞:“恭喜!又干得漂亮!”
01.
家用人形机器人的难点是怎么对家里千奇百怪的物品产生对应的智能行为。家里有各种不同形状、材质的物品,比如易碎的瓷器和玻璃制品、皱巴巴的衣服、椭圆的鸡蛋、杆状的晾衣杆吸尘器。
要教机器人学会一个新行为颇费周折:要么需要博士级专家花费几小时手动编程,要么需要对它进行数千次演示,两种方法的成本都很高。那么问题来了,每家每户买的东西那么多,消费品发展速度飞快,总会有机器人没见过的东西,难道要一个一个教给它吗?
好在AI领域已经展示了实时泛化的能力。Figure AI提出,将视觉语言模型中捕获的丰富语义知识,直接转化为机器人动作,将从根本上改变机器人的Scaling Laws。曾经需要数百次演示的新技能,现在只需用自然语言与机器人交谈,即可立即获得。
关键是如何从VLM中提取所有这些常识性知识,并将其转化为可泛化的机器人控制?对此,Figure构建了Helix模型。
据Figure介绍,Helix模型创造了多项业界首次:
在测试中,机器人成功地处理了杂乱无章的数千件新物品——从玻璃器皿和玩具到工具和衣服,并且无需任何事先演示或定制编程。

值得注意的是,当提示“捡起沙漠物品”时,Helix不仅会识别出玩具仙人掌符合这个抽象的概念,还会选择最近的手并执行所需的精确运动命令,牢牢地抓住它。
这种通用的“从语言到动作”的抓取功能为在非结构化环境中部署人形机器人提供了更大的可能性。

在一个更加复杂的应用场景中,当人类把Figure机器人从未见过的杂物放置在桌上时,提出整理要求时,两个机器人可以在没有经过明确分工的情况下,自然而然地开始协作,将杂物归类放置。

机器人甚至细心到,知道瓶装的物品应该放置在冰箱门上的置物筐中才不会容易翻倒,而不是往冰箱里随便一塞就了事;另一个机器人则知道要将饼干放到抽屉中。

在协调过程中,机器人用头部平稳地跟踪双手,同时调整躯干,以确定最佳触及范围,同时保持精确的手指控制来进行抓握。在高维动作空间中实现这种精度水平,非常有挑战性。Figure称之前没有VLA系统能展示出如此程度的实时协调、同时保持跨任务和对象泛化的能力。
收拾好后,它们还会记得贴心地把抽屉关好、关上冰箱门。美中不足的是,机器人一开始就把冰箱门打开,直到收拾完全部物品,才把冰箱门缓缓合上,丝毫没有节省电费的意识。

视频中一个值得关注的细节是,两个机器人在协作后会看向对方,这个画面很像人类会做的眼神交流。但实际上应该就是Figure设计用来吸引观众的一种营销策略,从Helix的技术介绍来看,两个机器人的协作主要靠软件系统和摄像头追踪动作,并不具备看眼色这种高级能力。
02.
现有VLA系统通常需要专门的微调或专用的动作头,来优化不同高级行为的性能。而Helix仅用一个统一模型就能执行不同任务,不需要针对特定任务进行调整。
Helix的系统由两个部分组成——即“系统1+系统2”架构,实现对人形机器人上半身的高速精准控制。
以前的方法有个问题,VLM骨干网络(backbone)是通用的,但速度慢;机器人视觉运动策略速度快,通用性又不行。Helix通过两个互补的系统S2(VLM骨干网络)和S1(潜在条件视觉运动Transformer)来权衡,这两个系统都经过了端到端训练,可以进行通信:
S2:基于7B参数的开源VLM,该VLM已在互联网规模数据上进行了预训练,在潜在视觉语言空间中进行“慢思考”,以7-9Hz频率运行,负责场景理解与语义理解,确保跨物体、跨场景的泛化能力。
S1:80M参数的交叉注意力编码-解码Transformer,负责处理低级控制,可“快速思考”,将S2的潜在语义表征转化为精确连续机器人动作,以200Hz频率协调35自由度动作空间,控制完整的机器人上半身,实现毫秒级实时响应。
这种解耦架构让两个系统各司其职:S2专注慢思考,负责制定战略,S1负责实时执行和调整行动。
例如在协作过程中,S1能快速适应机器人伙伴不断变化的动作,做出细粒度运动调整,同时保持S2的语义目标。最终Helix的运行速度做到与Figure最快的单任务策略一样快。
和现有方法相比,Helix采用的这种设计有四个主要优势:
1、速度和泛化:Helix匹配专门的单任务行为克隆策略的速度,同时将零样本泛化到数千种新测试物品。
2、可扩展性:Helix直接输出高维动作空间的连续控制,避免了先前VLA方法中使用的复杂动作标记方案,这些方案在低维控制设置(例如二值化并行抓取)中已取得一些成功,但在高维人形控制中面临扩展挑战。
3、架构简单:Helix使用标准架构——用于S2的开源、开放权重VLM和用于S1的简单Transformer视觉运动策略。
4、关注点分离:将S1和S2解耦,可以分别在每个系统上进行迭代,而不受寻找统一的观察空间或动作表示的限制。
03.
Helix以极少的资源实现了强大的物体泛化,总共使用约500小时的高质量监督数据来训练Helix,这只占先前收集的VLA数据集规模的不到5%,而且不依赖多机器人实体收集或多训练阶段。其收集规模更接近于现代单任务模仿学习数据集。
数据需求少了,不妨碍Helix能力强。Helix可以扩展到更具挑战性的动作空间,即完整控制人形机器人上半身,实现高速率、高维度的输出。
为了生成自然语言条件训练对,Figure使用自动标注VLM来生成事后指令。VLM处理来自机载机器人摄像头的分段视频片段,并提示:“你会给机器人什么指令来执行此视频中看到的动作?”训练期间处理的所有物品均不包含在评估中,以防污染。
Helix经过完全端到端的训练,从原始像素和文本命令映射到具有标准回归损失的连续动作。梯度通过用于调节S1行为的潜在通信向量从S1反向传播到S2,从而允许对两个组件进行联合优化。
在训练过程中,Figure在S1和S2输入之间添加时间偏移,此偏移经过校准以匹配S1和S2部署的推理延迟之间的差距,确保部署期间的实时控制要求准确反映在训练中。
Helix的训练设计支持在Figure机器人上高效并行部署模型,每个机器人都配备了双低功耗嵌入式GPU。
推理管道分为S2(高级潜在规划)和S1(低级控制)模型,每个模型都在专用 GPU上运行。S2作为异步后台进程运行,使用最新的观察结果(机载摄像头和机器人状态)和自然语言命令,不断更新编码高级行为意图的共享内存潜在向量。
S2将单目机器人图像和机器人状态信息(包括手腕姿势、手指位置等)投影到视觉语言嵌入空间后进行处理。结合指定所需行为的自然语言指令,S2将所有语义任务相关信息提炼为单个连续潜在向量,并传递给S1。
来自S2的潜在向量被投影到S1的token空间中,沿着序列维度与来自S1视觉骨干网络的视觉特征连接起来,提供任务调节。S1依靠完全卷积、多尺度视觉骨干网络进行视觉处理。该骨干网络通过完全在模拟中完成的预训练进行初始化。
虽然S1接收与S2相同的图像和状态输入,但S1以更高的频率来处理,作为单独的实时过程执行,能保持整个上身动作流畅所需的关键200Hz控制环路,采用最新的观察结果和最新的S2潜在向量。
Figure在动作空间中附加了一个合成的“任务完成百分比”动作,使Helix能够预测自己的终止条件,从而更容易对多个学习到的行为进行排序。
S2和S1推理之间固有的速度差异自然导致S1在机器人观察上以更高的时间分辨率运行,从而为反应控制创建更紧密的反馈环路。
这种部署策略刻意反映了训练中引入的时间偏移,从而最大限度地减少了训练-推理分布差距。异步执行模型允许两个进程以最佳频率运行,使Figure团队能以最快的单任务模仿学习策略速度运行Helix。
04.
与在规范化的工业环境不同,机器人如果要真正应用到家庭环境中,就必须应对家庭环境中各种不可控的因素,每个物品都有不可预测的形状、大小、颜色和纹理,需要能够按照实际情况智能生成新行为。
而Helix无需任何针对特定任务的示范、无需大量的手动编程,就能即时生成长期的、协作性的、灵巧的操作动作,展现出了强大的物体泛化能力。
这种能力,展现出人形机器人实现近乎人类的环境适应性的巨大潜能。而随着模型规模的不断扩展,也将为人形机器人真正进入家庭等更多负责环境、融入人类生活创造了更多可能性。


(文:智东西)