

在人工智能大模型的蓬勃发展浪潮中,多模态技术成为了新的焦点。语音作为人类最自然的交互方式之一,与语言模型的融合备受期待。近期,阿里通义实验室推出的MinMo多模态大型语言模型,以其独特的技术和强大的功能,在语音交互领域掀起了波澜。它致力于实现无缝语音交互,让人机对话更加自然流畅,宛如人与人之间的交流。接下来,让我们深入探索MinMo的技术原理、功能特点以及应用场景,一同感受它为语音交互领域带来的变革。
一、项目概述
MinMo是一款由阿里通义实验室精心打造的多模态大型语言模型,主打“可无缝语音交互”。它拥有约80亿参数,基于大规模的语音数据进行训练,涵盖超过140万小时的多样化语音内容,包括语音到文本、文本到语音、语音到语音以及语音到控制令牌等多种任务的数据。这使得MinMo在语音对话场景中表现卓越,能够实现实时、自然且类似人类的对话,还可支持不同语气、方言的表达,让人机交互更加贴近真实交流场景。

二、技术原理
1、独特的模型架构
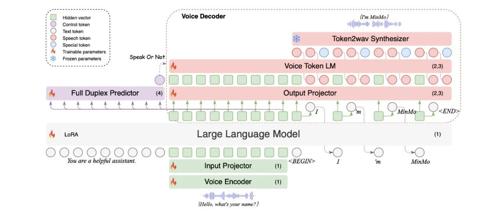
MinMo的模型架构精巧复杂,主要由语音编码器、输入投影器、大型语言模型(LLM)、语音令牌语言模型(Voice Token LM)、输出投影器、令牌到波形(Token2Wav)合成器以及全双工预测器构成。
-
语音编码器:采用预训练的SenseVoice-large编码器模块,具备强大的语音理解能力,能够支持多语种语音识别、情感识别以及音频事件检测。它就像是一个敏锐的“耳朵”,能够精准捕捉语音中的各种信息。
-
输入投影器:由两层Transformer和一个CNN层组成,主要负责维度对齐和降采样,将语音信号转化为适合后续处理的格式,为模型的高效运行奠定基础。
-
大型语言模型(LLM):选用预训练的Qwen2.5-7B-instruct模型,该模型在各种基准测试中成绩优异,赋予了MinMo强大的语言理解和处理能力,是模型的“智慧大脑”。
-
语音令牌语言模型(Voice Token LM):基于预训练的CosyVoice2 LM模块,能够自回归地生成语音令牌,在语音生成环节发挥关键作用。
-
输出投影器:作为一个单层线性模块,负责维度对齐,确保模型输出的语音令牌能够顺利进入下一个环节。
-
令牌到波形(Token2Wav)合成器:包含基于流的匹配模型和声码器,能将语音令牌合成为波形,最终输出自然流畅的语音,实现从文本到语音的转换。
-
全双工预测器:由一层Transformer和一个线性softmax输出层组成,用于实时预测是否响应用户命令或暂停当前系统广播以处理用户输入,保障了全双工对话的流畅进行。
2、创新的语音解码器
MinMo引入了创新的语音解码器,用于将LLM的文本输出转换为语音。该解码器包括输出投影器、语音令牌语言模型(Voice Token LM)和流令牌到波形(Token2Wav)合成器。输出投影器对齐LLM与语音解码器的维度,语音令牌语言模型自回归地生成语音令牌,而令牌到波形合成器则将语音令牌合成为波形,使得语音生成更加自然、流畅。
3、多阶段的训练方式
MinMo通过四个阶段的对齐训练来逐步获得音频理解和生成能力,同时保留文本LLM的能力。
-
语音到文本对齐:使用语音到文本数据对齐音频模态的输入潜在空间和预训练文本LLM的语义空间。先进行预对齐和全对齐,再进行指令微调,让模型初步适应语音与文本的转换。
-
文本到语音对齐:运用文本到语音数据对齐文本LLM的语义空间与音频模态的输出潜在空间。先训练输出投影器,再联合训练输出投影器和语音令牌语言模型,使得模型能够将文本准确地转换为语音输出。
-
语音到语音对齐:利用约1万小时的配对音频数据继续训练MinMo,主要更新输出投影器和语音令牌语言模型,进一步提升模型在语音生成方面的表现,使其能够生成更加自然、多样化的语音。
-
双工交互对齐:在前三个阶段的基础上,训练全双工预测器模块来支持全双工对话。全双工预测器利用LLM的语义理解能力来决定是否需要生成响应,或暂停当前输出以处理用户输入,实现用户和系统之间的同时双向通信。
三、主要功能
1、全双工语音交互
MinMo支持全双工语音交互,这意味着用户和系统同时说话也不会出现混乱。其语音到文本的延迟约为100毫秒,理论上的全双工延迟约为600毫秒,实际中约为800毫秒。在实际对话场景中,用户提问还未结束,MinMo就已经开始分析并给出反馈,整个过程几乎没有停顿,大大提升了对话的流畅性和效率。
2、多样化可控生成
用户可以根据自身需求指定情感、方言、说话风格,甚至模仿某人的声音。无论是热情洋溢的回答,还是带有地方特色的方言交流,亦或是模仿某个知名人物的声线,MinMo都能轻松实现,极大地丰富了语音交互的形式和内容。
3、多任务处理能力
在语音对话、多语言识别、多语言翻译、情感识别、说话人分析、音频事件分析等多个任务上,MinMo都有着出色的表现。在多语言识别中,能够准确识别多种语言的语音内容;在情感识别时,能精准判断语音中的情感倾向,为交互增添更多人性化元素。
四、应用场景
1、智能客服领域
在智能客服场景中,MinMo能够以自然流畅的语音与客户进行交互。当客户咨询问题时,它可以快速理解客户的意图,用合适的语气和语言风格进行回答,高效解决客户的问题,大大提高客户服务的效率和质量,减少人工客服的压力。
2、语音助理场景
作为语音助理,MinMo可帮助用户完成各种日常任务。用户可以通过语音指令让它查询信息,如天气、新闻等;设置提醒事项,不错过重要事件;播放音乐,营造愉悦的氛围等,为用户提供便捷、智能的语音交互体验。
3、人机对话系统
在智能家电、智能车载等领域,MinMo实现了人与设备之间的自然对话。在智能家电中,用户可以通过语音控制家电的开关、调节温度等;在智能车载系统里,用户可以与MinMo交流,实现导航设置、音乐播放切换、车辆信息查询等功能,提升设备的智能化水平和用户体验。
4、语音翻译场景
对于需要进行跨语言交流的用户,MinMo的多语言翻译功能大有用处。它支持多语言语音翻译,能够快速准确地将一种语言的语音翻译成另一种语言的语音,方便不同语言的用户进行交流,打破语言障碍。
五、结语
MinMo作为阿里在多模态语音交互领域的重磅成果,凭借其创新的技术架构、强大的功能以及广泛的应用潜力,为语音交互领域带来了新的发展方向。它不仅提升了人机对话的自然度和流畅性,还在多个应用场景中展现出了巨大的价值。随着技术的不断发展和完善,相信MinMo将在更多领域得到应用和拓展,为用户带来更加智能、便捷、自然的语音交互体验。让我们共同期待MinMo在未来的表现,以及它为人工智能语音交互领域带来的更多惊喜和变革。
项目地址
项目网页:https://funaudiollm.github.io/minmo
论文地址:https://arxiv.org/pdf/2501.06282
(文:小兵的AI视界)