

月之暗面最新技术报告 —— 《Muon is Scalable for LLM Training》! 推出了一个全新的优化器 Muon,并基于此训练出了 3B/16B 参数的混合专家模型 (MoE)——Moonlight。这个 Moonlight 不是普通的模型,它在训练效率上实现了200% 倍提升,并且一举突破了现有大语言模型的性能边界

我们都知道,训练大型语言模型 (LLM) 就像一场“烧钱”大战,计算资源和时间都是巨大的挑战。而优化器,就如同这场战役中的“兵法”,直接决定了训练的效率和模型的最终效果。
一直以来,AdamW 都是大家训练 LLM 的标配。但是,月之暗面团队这次带来的 Muon 优化器,却展现出了更强大的潜力!
简单来说,Muon 优化器基于矩阵正交化,这是一种听起来有点高深的技术。但你可以把它想象成,Muon 在更新模型参数的时候,会让参数矩阵的各个方向都“雨露均沾”,避免模型只沿着少数几个“主导方向”学习,从而提升学习效率和模型的泛化能力。
Muon 的两大“神技”: 🔑
之前的研究表明,Muon 在小规模模型上表现出色,但能否扩展到更大规模的模型,一直是个未知数。经过深入研究,研究人员发现了 Muon 扩展的关键秘诀,主要有两点:
-
1. 加入权重衰减 (Weight Decay): 就像给模型训练加上了“刹车”,防止模型参数过度膨胀,保持训练的稳定性和模型的泛化能力 -
2. 精细调整参数更新尺度: 针对不同形状的参数矩阵,智能调整更新幅度,确保更新的“力度”恰到好处,避免“用力过猛”或“力不从心”
Muon 优化器还自带三大 BUFF 加成:
-
• 效率 BUFF: 对比 AdamW,计算效率直接翻倍 -
• 丝滑 BUFF: 无需繁琐的超参数调整,AdamW 用户可以无缝切换到 Muon -
• 性能 BUFF: 内存和通讯效率都大幅提升,分布式训练更轻松
实验数据说话:Muon 效率提升 📊
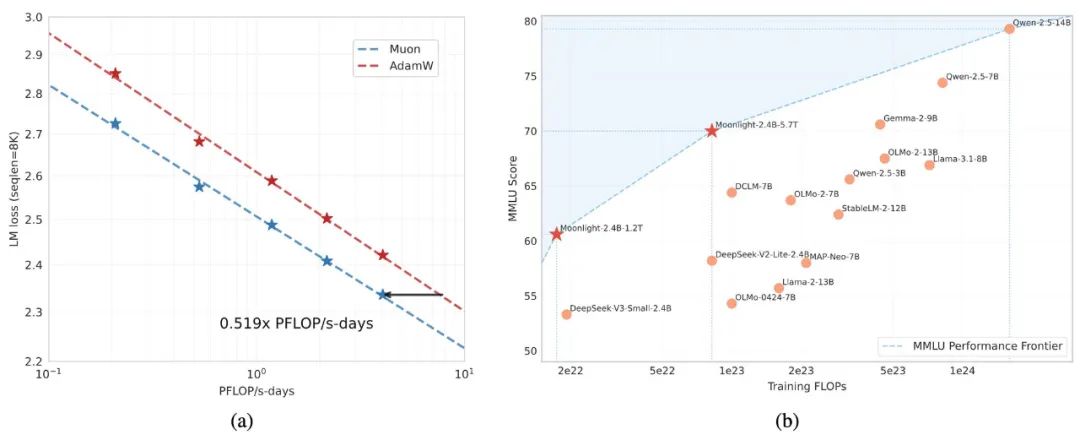
为了验证 Muon 的实力,团队进行了大量的实验,包括大规模的 Scaling Law (扩展定律) 实验。结果令人震惊:
-
• 计算效率暴涨: 在计算量最优的训练条件下,Muon 的计算效率是 AdamW 的 2 倍!这意味着,用 Muon 训练模型,可以用一半的计算资源达到 AdamW 相同的效果! -
• 性能更上一层楼: 基于 Muon 优化器训练的Moonlight 模型,在MMLU 基准测试 上表现出色,大幅超越了同等规模的其他模型,真正做到了“少花钱,多办事”! -
• 突破 Pareto 前沿: Moonlight 模型成功突破了 MMLU 性能的 Pareto 前沿,这意味着,在性能和计算成本之间,Moonlight 找到了更优的平衡点
写在最后
月之暗面开源了所有成果!
💻 代码 & 实现:
https://github.com/MoonshotAI/Moonlight
🤗 全系列模型 (预训练, 指令微调 & 中间检查点):
https://huggingface.co/moonshotai
📜 技术报告 Paper:
https://github.com/MoonshotAI/Moonlight/blob/master/Moonlight.pdf(硬核技术细节,尽在 Paper 中)
⭐
(文:AI寒武纪)