

今天是2025年02月23日,星期日,北京,天气晴。
我们今天继续来谈误区问题。之前已经谈过DeepseekR1,Ktransformer这些,现在来看看think这块。
现在Deepseek R1大家开始使用,但是针对think这个过程,目前也出现了许多不同的需求和问题,有些还让人哭笑不得,依旧存在一些误区,不从基本技术逻辑出发。
所以,我们来看看为什么会这样,有解决的方式么?【当然,都是探索的过程,目前没有根治方案】。
但是,我在想,一个模型出来其是带着它的特点来的,而为了上而上,而让它丢掉其原有特性去强制适应一些不合它设定的任务,这会失去使用它的意义。这个是大家需要意识到的。R1,有点不堪重负了。
专题化,体系化,会有更多深度思考。大家一起加油,多思考,多从基本逻辑出发。
一、从Deepseek-R1-think存在的一些客户需求
现在Deepseek R1大家开始使用,但是针对think这个过程,有许多疑惑,很多客户也提了一些很奇怪的需求。
例如,R1为什么不思考?无论问什么问题,都应该给出思考过程呀?
又如,为什么R1思考过度,简单问题也扯一堆?R1思考太长了,响应时间太长了,能不能别让别输出思考过程?
又如R1在一些问题上思考过度,能不能让其少思考一点?
又如R1在一些问题上思考的太短,能不能思考地长一点?
又如控制R1的思考方式?
当然,也有think过度,算个1+1等于几,就15秒,也有一些问题思考了很久然后还有幻觉问题。
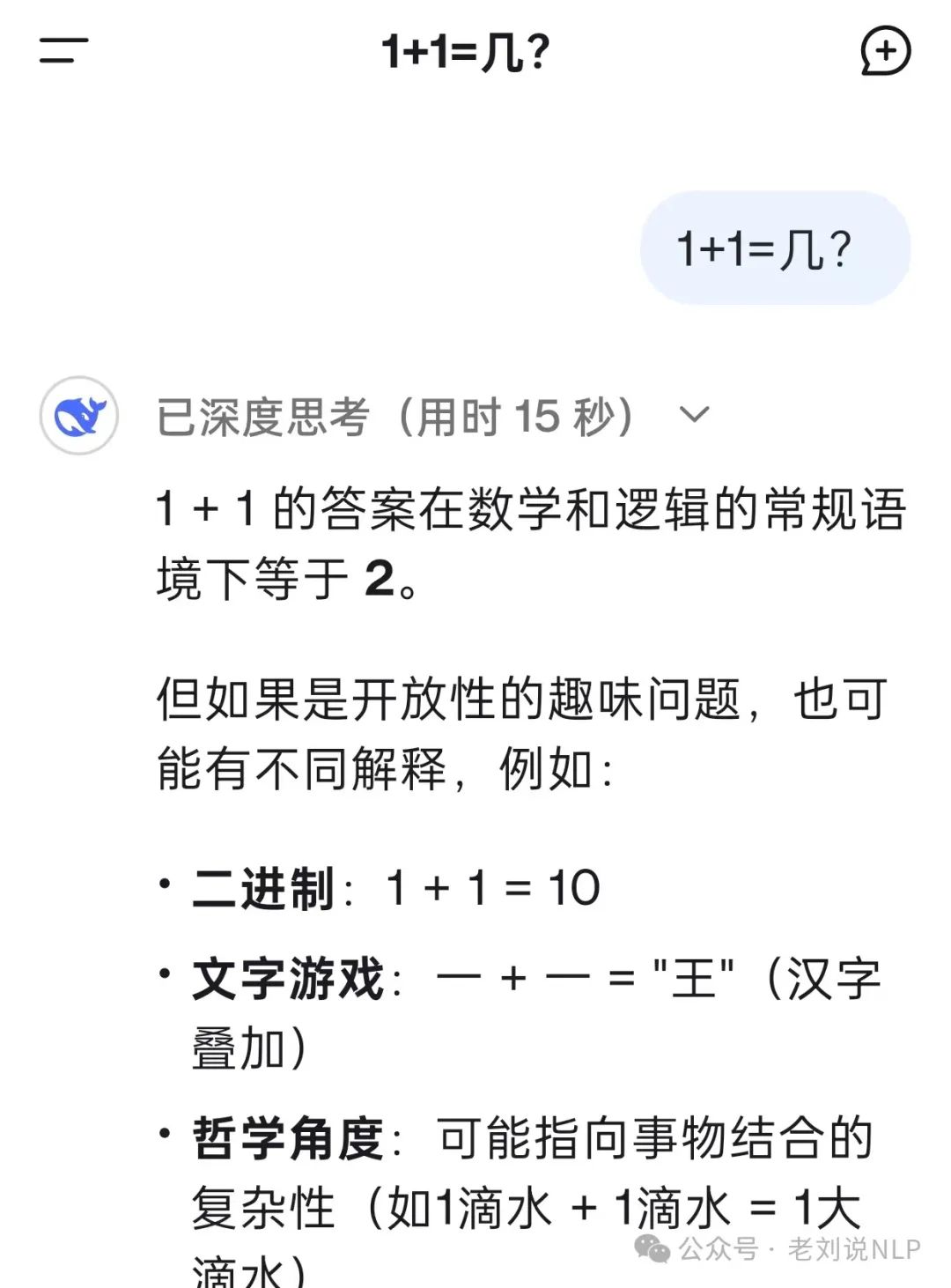
这些种种需求,实际上,很多都是对R1本身有误解,所以,我们同步来看看。
二、Deepseek-R1-think存在的四个问题看法
Deepseek R1是一个推理模型,其特点就是能够推理过程,目标也是如此,这是由其训练过程决定的。
1、R1一定要输出think过程?
当然,并不是所有问题都会生成think过程,其在训练过程当中,有一些非推理问题的数据,正如其官方(https://github.com/deepseek-ai/DeepSeek-R1)所说:

DeepSeek-R1系列模型在响应某些查询时倾向于绕过思考模式(即输出 <think>\n\n</think>),这可能会对模型的性能产生不利影响。为了确保模型进行彻底的推理,我们建议强制模型对每个输出都以 <think>\n为其响应的开头。
2、不让R1输出think过程?
第一个问题已经回答了,其模型设置就是要输出think 过程,如果不需要其推理过程,那么则可以使用DeepSeek V3版本或者其他不输出推理过程的模型。
例如,通过prompt中加入约束,让其直接回答。
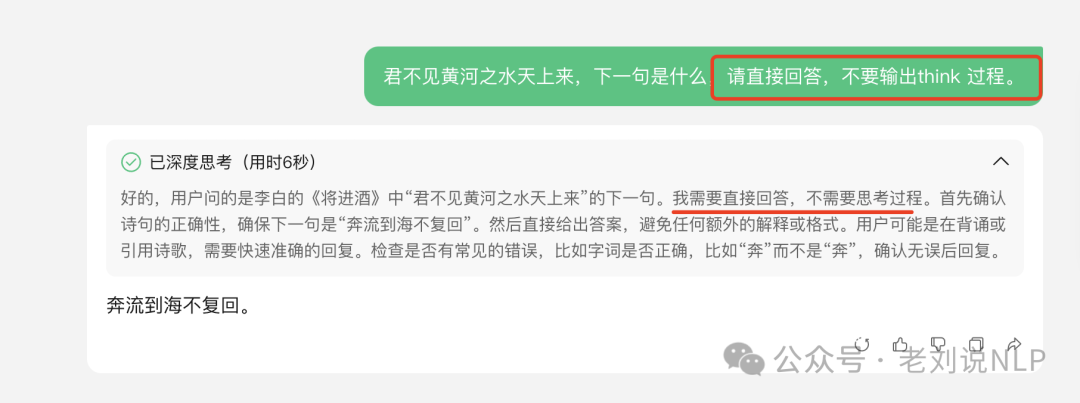
结果还是会进行思考,这也符合直觉。
但是,如果我们进一步地去想这个事情,从干预其解码过程出发,似乎也能找到一些思路?既然输出依赖于之前的输入,那么直接帮他提前人工手动think是不是就行了?另外,既然think过程中带有明显的token,如果我们不关注其能力的损失,那么久不要采样这些推理token是不是就行?
那么就有两条路可以走。
第一条路,修改prompt template,添加<think>/n/n</think>,这样减少think的概率,与前面强制进行think相对,这是骗过R1,让它误以为已经think过了,从而降低再出现think的概率。但这个是得碰运气。当然,这里的修改prompt template,不是直接在prompt后面加<think>/n/n</think>,这个没用,如下。
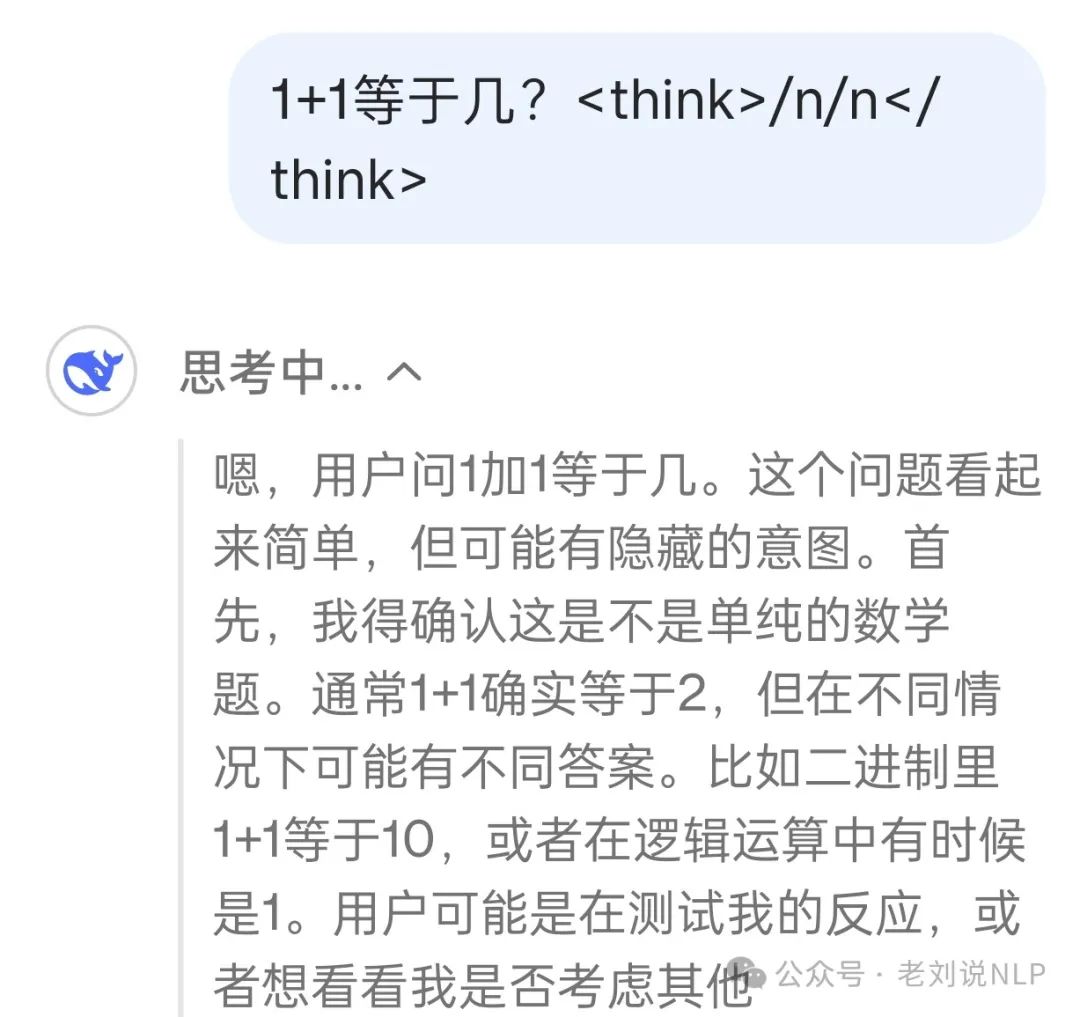
而是在启动的时候,写入到chat template里。
第二条路,是干预token解码采样,把think相关的token去掉不去采样就好了。例如基于SGLang修改,修改模型服务方式,跳过tokenizer阶段,加上 这个参数 –skip-tokenizer-init,然后手动进行 tokenizer 的 encode decode。但这种方式,其实破坏了之前模型预测的概率分布,理论上说会想想效果。但具体损失多少,需要具体实验,例如,社区成员实验发现,32b蒸馏模型上很稳定,到这个测试集合还是偏向于非推理任务。
不过我在想,R1本身就是为推理而生的,效果好就是think这个分支输出是最好的加上prompt和输出约束,效果是会有折扣,去掉失去使用R1的意义了。与其如此,不如使用R1的回退版本V3。
3、让R1根据指定思考方向调整think?
而至于对于R1思考太长或者太短的问题,这个问题的根治办法,还是在原有模型上进行微调或者强化。因为思考的长度,再起训练阶段就已经决定了,即由其训练中已经使用的80W数据的长度来决定,其是一个拟合过程。并且,根据测试时间的scaling law,思考的时间越久,长度越长,效果越好,这些也都决定了其偏向于泛化思考很长。
目前,也试过一些通过 prompt进行控制,例如可以使用腾讯元宝中接入的Deepseek-R1接口。
以“分析下铁矿石这个品种”为例,不加限定地问,其思考会很长,也很全面。
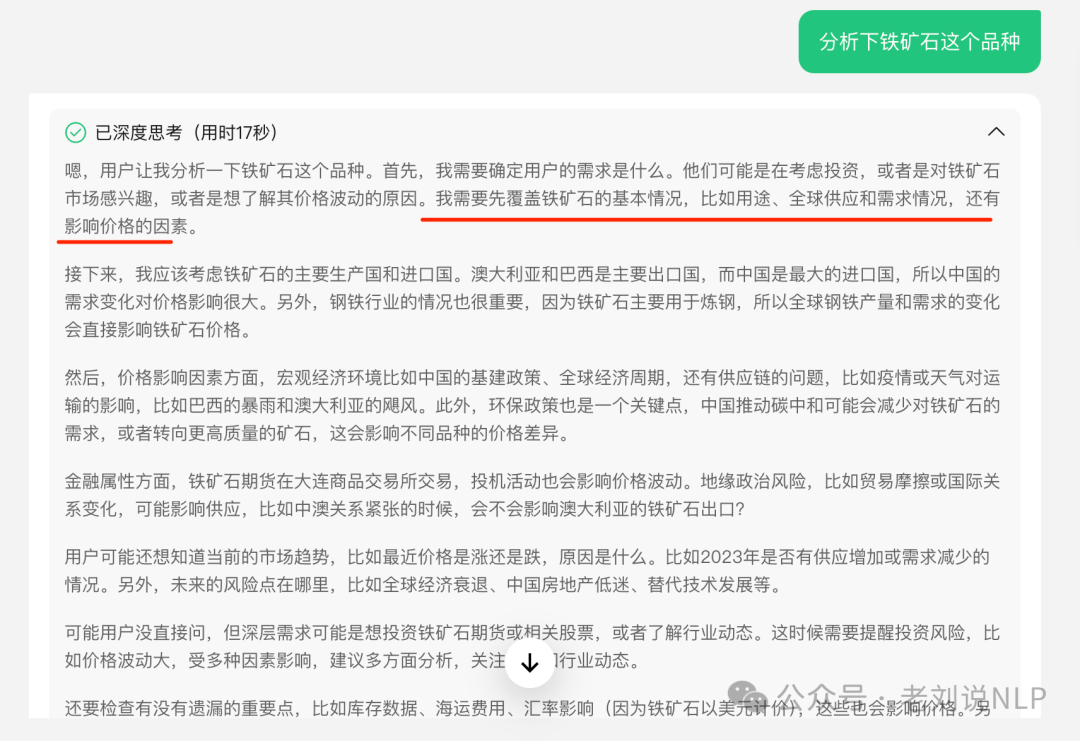
但加上限定,“分析下铁矿石这个品种,按照我的思考方式来。仅仅从铁矿石的产量、品种两个方面思考,不要发散。”

这个是有效的,说明R1有遵循思考方式的能力,可以进行约束。
4、让R1缩短思考时间?或者长度?
DeepSeek存在很严重的过度推理,正如https://github.com/deepseek-ai/DeepSeek-R1/issues/394所说,

当前观察到的现象:1)啰里啰嗦没完没了的分析;看似有模有样的分析,实际都是胡说八道,说10000+tokens。也有测试,你给他十个数,然后问他第3个数字是啥,他也会“过度推理”。
当然,这个issues下有一些讨论,可以看看,也对比了其他的模型,如豆包、百度的分析。
这里的说的有道理,确实有点过于啰嗦了,它过多的自我反思,以及用不同的策略和路线来印证自己结论的准确性,因为目前对大模型的评判标准主要是准确率与推理速度,而推理速度也包括think部分,我觉得对于Deep Research类型的模型,应该再加一项产生有效响应的时间,防止模型为了提升准确率而无限制的增加思考深度。
前面说到,通过prompt约束,让其不输出think,还是会进行思考,但是,其可以缩短思考时间,如君不见黄河之水天上来,下一句是什么,原本思考需要25秒,约束之后是6秒:

从prompt上,限制思考的长度,也是行不通的,也还是会think。

出了在prompt上做些花样之外,还有就是在生成参数上做一些控制,在思考时间上,也有一个例子,就是无休止的重复或不连贯的输出。官方也给到一个方案,将温度设置在0.5-0.7范围内(建议为0.6)。
总结
本文只说了几个点,大家致所有会有一些误区,还是对其模型本身缺乏了解,缺乏基本逻辑认知。还是那样,单纯靠prompt,就是在拆盲盒,治标不治本,尤其是针对这类推理模型。如果要根治,要从微调、强化等方式进行处理,但是,这个成本就更高了。
看项目的github,并且去看issues,能够看到很多有趣的事,大家也可以多看看。
参考文献
1、https://github.com/deepseek-ai/DeepSeek-R1/issues/394
(文:老刘说NLP)