

当下,AI 生成图像的技术足以以假乱真,在社交媒体肆意传播。
如何对不同生成模型实现通用检测?
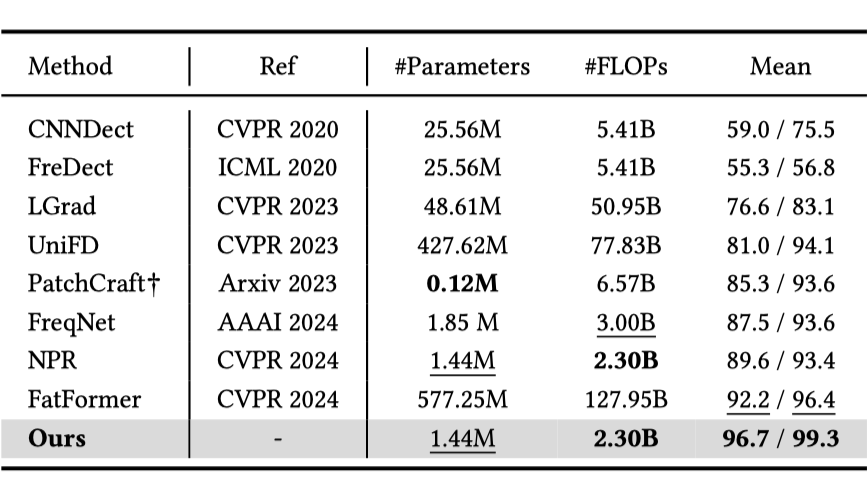
小红书联合中国科学技术大学给出了解决方案,仅用 1.44M 参数量实现了通用 AI 图片检测,在 33 个测试子集上达到 96.7% 准确率,超 SOTA 模型 4.5 个百分点。
这项研究目前已经被 KDD 2025 接收。

论文链接:
代码链接:

要实现通用的 AI 图像检测,核心问题是如何泛化到未知的生成模型上去,现在主流的生成模型包括生成对抗网络 GANs 和扩散模型 DMs。
研究团队从生成模型架构的共性出发,期望从 AI 图像和真实图像的成像机制的差异中找到突破口。
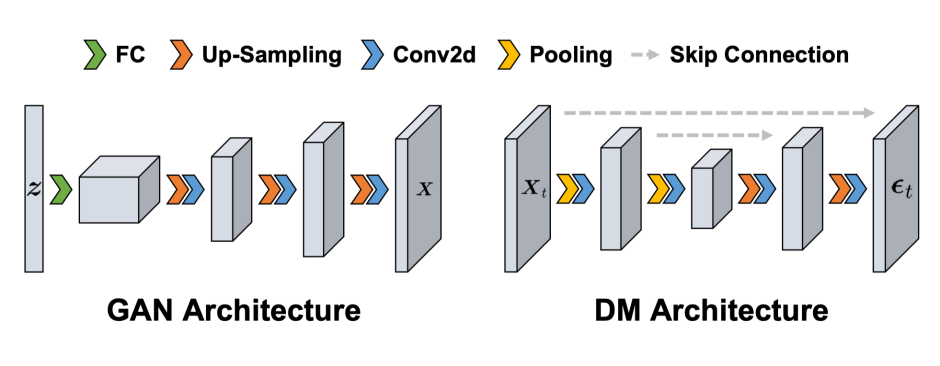
在 GANs 中,先通过全连接层把低分辨率的潜在特征变成高分辨率,然后用上采样和卷积操作合成图像。DMs 呢,先把有噪图像通过池化和卷积操作降维,再通过同样的操作升维预测噪声。
这两种模型在合成图像时,都大量使用上采样和卷积,而这两个操作在数值计算上相当于对像素值加权平均,会让合成图像相邻像素的局部相关性变强,留下独特的 “伪影特征”,这就是 AI 图像检测的关键线索。

检测方法 “跑偏”:错在训练策略
想象一下,你要在一堆真假难辨的画作里找出赝品,如果用来鉴定的方法本身就有缺陷,那肯定很难完成任务。
现有的 AI 图像检测方法,就面临着这样的困境。
当前的 AI 图像检测方法大多将重点放在挖掘真实图像与 AI 图像之间的通用差异,,也就是“通用伪影特征”,却忽略了训练过程中的关键问题。
研究团队发现,当前的训练模式存在两大问题。

第一个问题是“弱化的伪影特征”。
AI 图像在生成过程中,由于使用了上采样和卷积等操作,图像像素之间的联系变得更加紧密,从而留下了可供检测的痕迹。然而,许多检测方法在对图像进行预处理时,常常采用下采样操作来统一图像尺寸,这一操作会“抹除”那些细微的痕迹,大大增加了检测的难度。
第二个问题是“过拟合的伪影特征”。
现有的检测方法在训练时,数据增强方式较为单一,比如仅仅进行水平翻转操作。这就使得模型过度适应了训练数据中的特定特征,出现过拟合现象。一旦遇到未曾见过的 AI 图像,模型就无法准确识别,泛化性能较差。

简单图像变换:有效去偏
为了解决这些问题,研究团队提出了 SAFE,它凭借三种简单的图像变换直击难题。
第一是痕迹保留(Artifact Preservation)。
SAFE在图像预处理阶段,舍弃了传统的下采样(Resize)操作,改为采用裁剪(Crop)操作。在训练过程中进行随机裁剪(RandomCrop),测试时则使用中心裁剪(CenterCrop)。这样一来,AI 图像中的细节以及像素之间的微妙联系得以保留,方便检测器发现那些细微的“破绽”,显著提升了捕捉 AI 伪影的能力。
第二是不变性增强(Invariant Augmentation)。
SAFE 引入了 ColorJitter 和 RandomRotation 两种数据增强方式。ColorJitter 通过在色彩空间中对图像进行调整,能够有效减少因颜色模式差异而带来的偏差。RandomRotation 则让模型在不同旋转角度下依然能够聚焦于像素之间的联系,避免受到与旋转相关的无关特征的干扰,增强了模型对图像旋转的适应能力。
第三是局部感知(Local Awareness)。
SAFE 提出了基于 Patch 的随机掩码策略(RandomMask)。在训练时,按照一定概率对图像实施随机掩码,引导模型将注意力集中在局部区域,进而提升模型的局部感知能力。令人惊喜的是,即使图像的大部分区域被掩蔽,模型依然能够依据剩余的未掩蔽部分准确判断图像的真伪。
此外,SAFE 利用简单的离散小波变换(DWT)来提取高频特征,并将其作为检测的伪影特征。由于 AI 图像与自然图像在高频分量上存在明显差异,DWT 能够很好地保留图像的空间结构,有效提取这些差异特征。

实验对比:轻量且高效
研究团队开展了大量实验,以验证 SAFE 的实际效果。
在实验设置上,训练数据选用 ProGAN 生成的 AI 图像以及对应的真实图像,测试数据则广泛涵盖了多种来源的自然图像,以及由 26 种不同生成模型所生成的 AI 图像,包括常见的 GANs 和 DMs 等。并且选取了 10 种极具代表性的方法作为基线进行对比,通过精确的分类准确率(ACC)和平均精度(AP)来衡量检测效果。
4.1 泛化性能对比
SAFE 在 33 个测试子集上达到了平均 96.7% 的准确率,超过 SOTA 方法 4.5 个点。
值得注意的是,SAFE 只有 1.44M 的参数量,在实际推理时的 FLOPs 仅为 2.30B,相比于 SOTA 方法有 50 多倍的效率提升,便于工业部署。
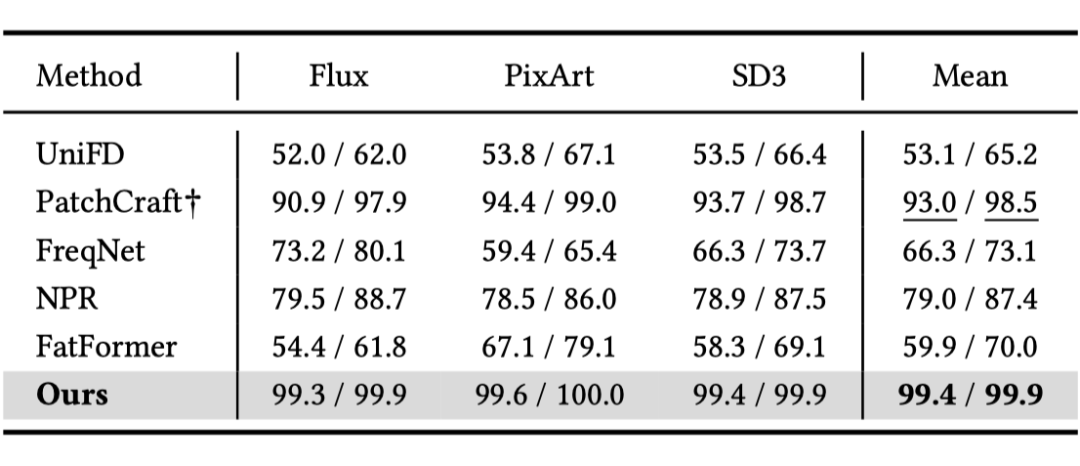
针对最新的基于 DiTs 的生成器,研究团队构建了 DiTFake 测试集,包含最新的生成模型 Flux、SD3 以及 PixArt。SAFE 在 DiTFake 上表现堪称卓越,平均准确率达到 99.4%,对新型生成器的泛化能力极强。
4.2 即插即用的特性
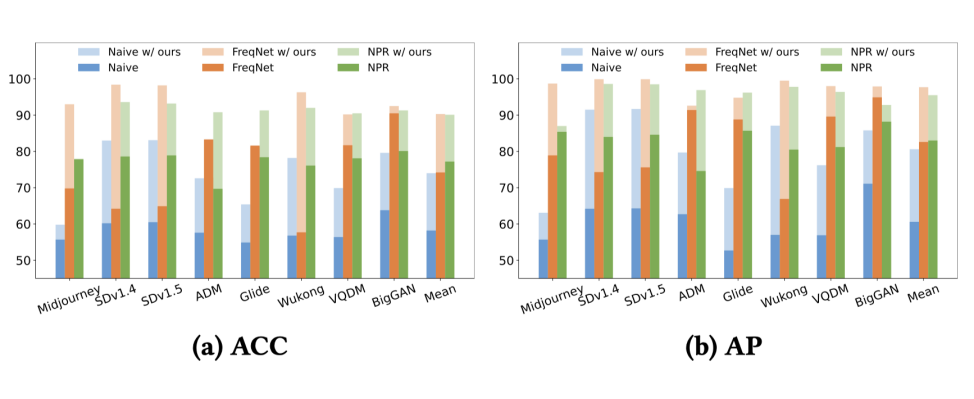
值得一提的是,由于 SAFE 具有模型无关的特性,研究人员将其提出的图像变换作为一个即插即用的模块,应用到现有的检测方法之中。从 GenImage 测试集的对比结果来看,这一应用带来了令人惊喜的效果,检测性能得到了一致提升。
4.3 消融实验
研究团队还进行了充分的消融实验,深入探究模型各个组成部分的具体作用。
在图像预处理环节,重点聚焦于裁剪(Crop)操作的效能探究。实验数据有力地证实,在训练进程中,裁剪操作相较于传统的下采样(Resize),具有不可替代的关键作用。
即使测试图片在传输过程中不可避免地经历了下采样操作,基于裁剪方法比基于下采样方法训练出的模型仍表现出更好的检测效果。
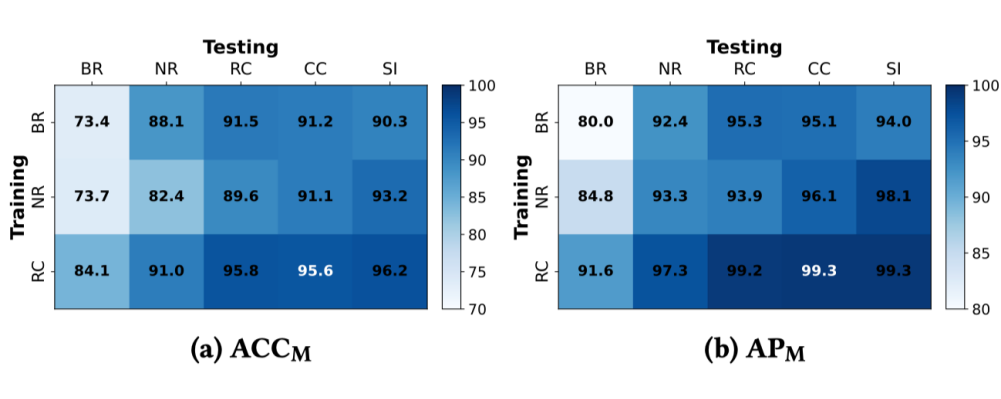
对于数据增强技术,分别对 ColorJitter、RandomRotation 和 RandomMask 进行了单独和组合的效果评估。这三种数据增强技术不仅各自都能发挥有效的作用,而且当它们共同作用时,效果更加显著,能够进一步提升检测性能。

在特征提取方面,研究团队对不同的图像处理算子进行了消融,包括用原图(Naive)、频域变换算子(FFT、DCT、DWT)、边缘提取算子(Sobel、Laplace)以及不同的频带(LL、LH、HL、HH)。
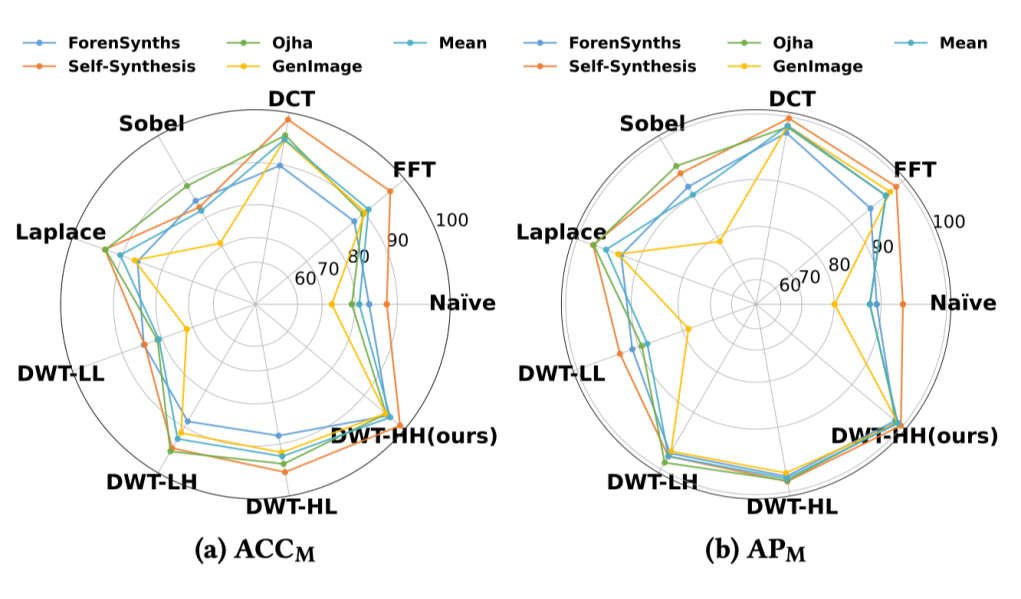
因为 AI 图像在高频部分的拟合能力相对较弱,通过高频信息的差异进行判别展现出了卓越的性能。在高频信息提取上,FFT 和 DCT 仍表现出和 DWT 相当的性能,说明简单的频域变换已经能够很好地进行 AI 图像检测。
SAFE 为 AI 图像检测领域开辟了新的方向。它促使我们重新思考复杂的人工设计特征的必要性,也启发后续研究可以从优化训练模式入手,减少训练偏差。
(文:PaperWeekly)