


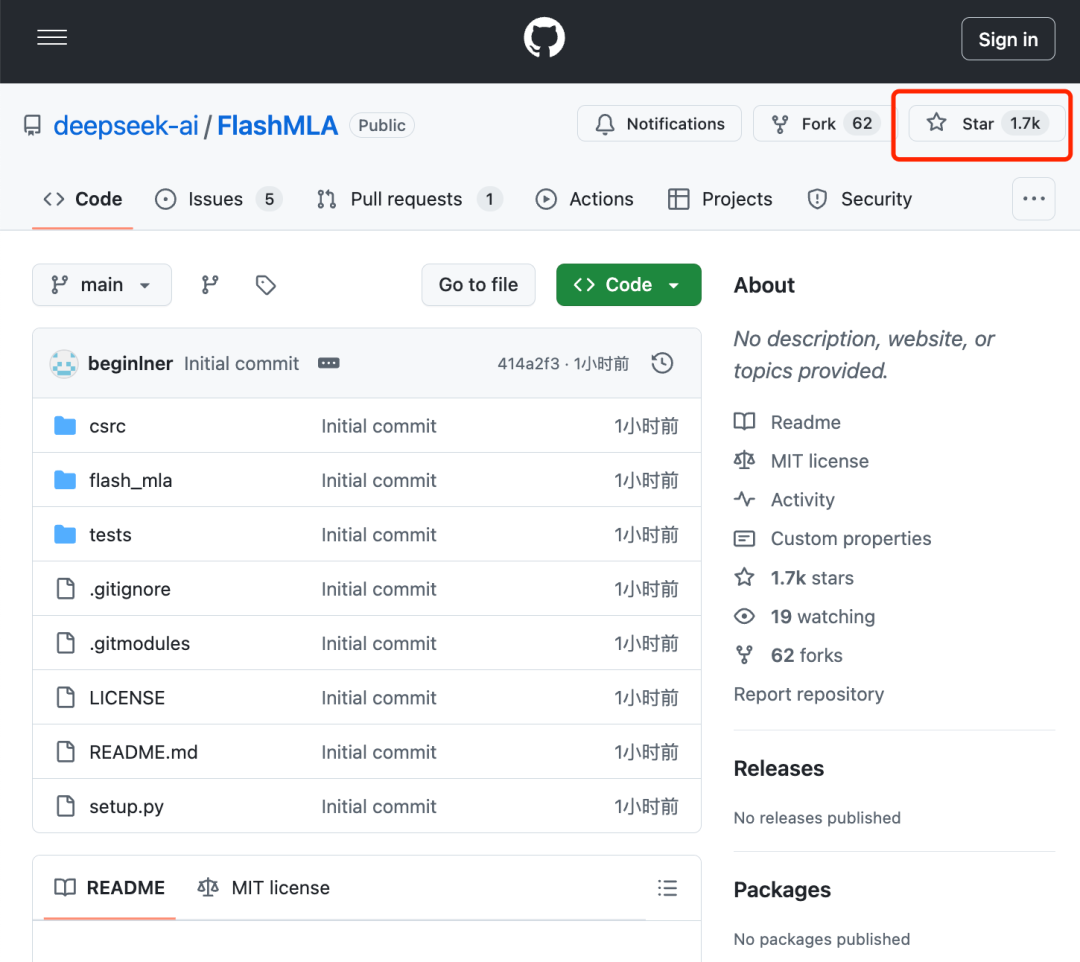
智东西2月24日报道,刚刚,DeepSeek开源周第一天重磅更新来了,开源首个代码库——FlashMLA,发布一小时GitHub Star数冲上1700。
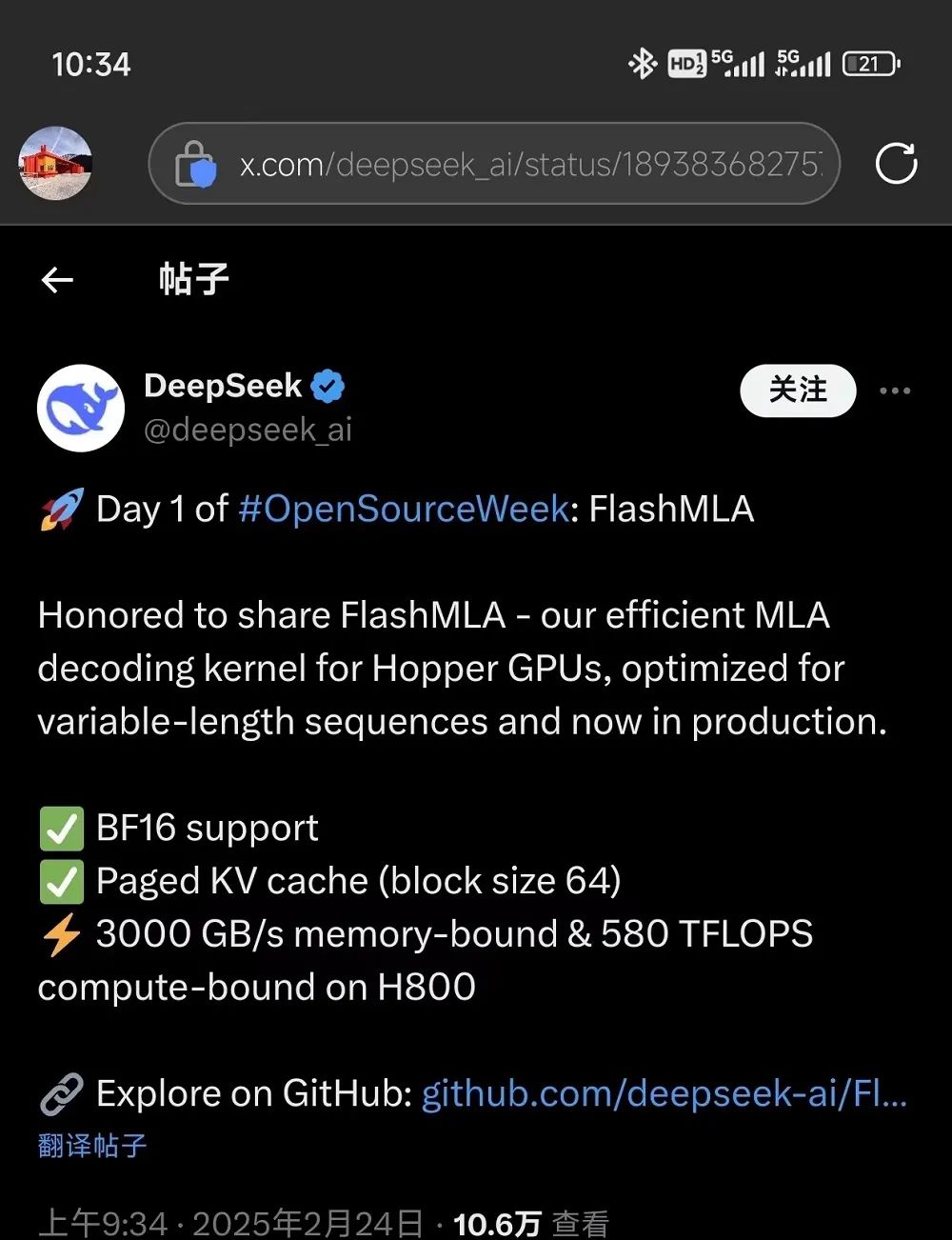
FlashMLA指的是DeepSeek针对Hopper GPU的高效MLA解码内核,针对可变长度序列进行了优化,现已投入生产。目前已发布的内容包括:采用BF16,以及块大小为64的分页kvcache(键值缓存)。
使用CUDA 12.6,在H800 SXM5上,其性能指标是:

用法:
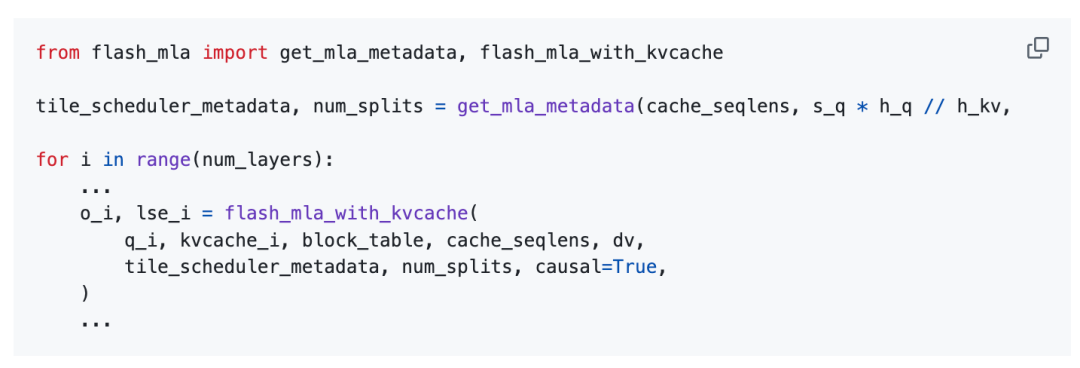
FlashMLA的使用基准为:Hopper GPU、CUDA 12.3及以上版本、PyTorch 2.0及以上版本。
DeepSeek介绍称,FlashMLA受到FlashAttention 2&3和CUTLASS项目的启发。
其中,FlashAttention是斯坦福联合纽约州立大学在22年6月份提出的一种具有IO感知,且兼具快速、内存高效的新型注意力算法;CUTLASS是由英伟达开发和维护的开源项目,CUTLASS提供了更高级别的灵活性和可配置性,允许用户自定义和优化矩阵运算的细节。
DeepSeek开源FlashMLA的推文发布不到一小时,就已经吸引了超10万人关注,上百条评论。
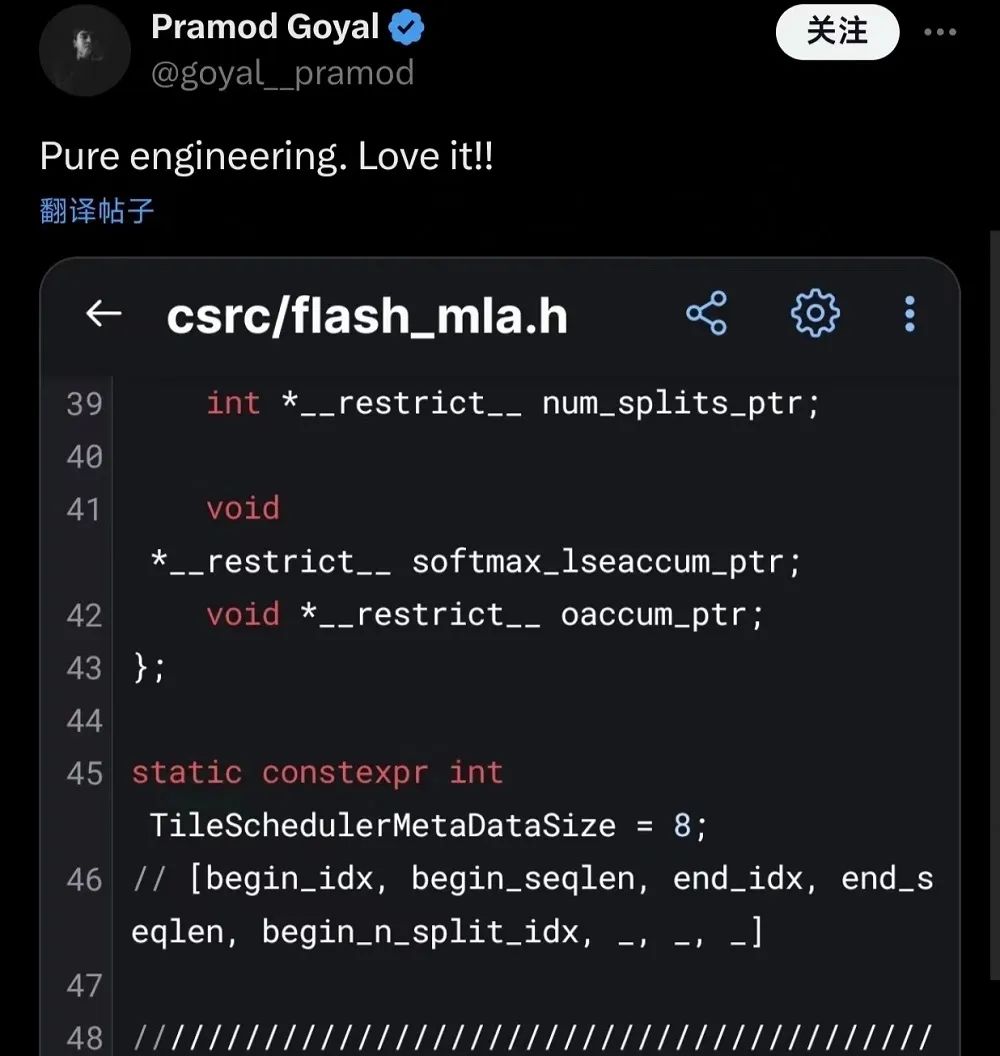
已有海外开发者第一时间研究起了FlashMLA的代码库,他感叹道:“真是纯粹的工程,太爱了!”
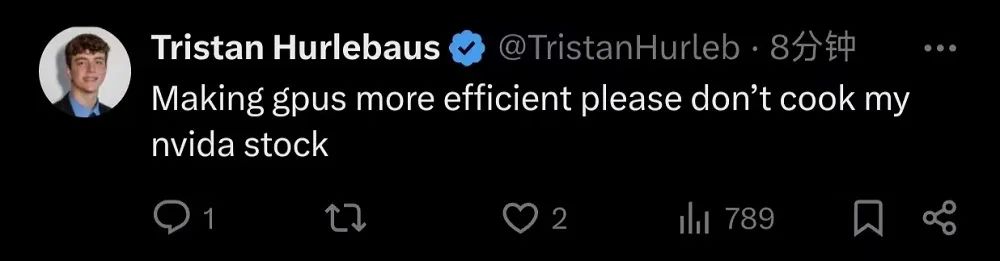
有一位英伟达股民跑到DeepSeek的评论区祈祷,希望DeepSeek能在不影响英伟达股价的前提下,让GPU更为高效。


GitHub地址:
https://github.com/deepseek-ai/FlashMLA
(文:智东西)