
 在人工智能飞速发展的今天,大语言模型已成为推动创新的核心力量。DeepSeek-R1-Distill-Qwen-7B 是深度求索(DeepSeek)推出的蒸馏版大语言模型,基于 Qwen-7B 进行知识蒸馏训练。它在保留 90% 以上性能的同时,显著降低了推理成本,为开发者提供了高性价比的选择。本教程将手把手教你如何借助 FastAPI 框架,将这一强大的模型部署为 API 服务,让应用开发更加便捷。
在人工智能飞速发展的今天,大语言模型已成为推动创新的核心力量。DeepSeek-R1-Distill-Qwen-7B 是深度求索(DeepSeek)推出的蒸馏版大语言模型,基于 Qwen-7B 进行知识蒸馏训练。它在保留 90% 以上性能的同时,显著降低了推理成本,为开发者提供了高性价比的选择。本教程将手把手教你如何借助 FastAPI 框架,将这一强大的模型部署为 API 服务,让应用开发更加便捷。一、模型概述
DeepSeek-R1-Distill-Qwen-7B 是一款基于 DeepSeek-R1 架构,通过知识蒸馏技术优化的高性能语言模型。它继承了大型教师模型的“推理 DNA”,在推理能力上表现出色,尤其适合需要高效逻辑推理和复杂任务处理的场景。该模型参数量为7B,基于 Qwen 2.5 架构,支持最长 128K 的上下文窗口,并能生成最多 8K tokens 的输出。它在资源消耗和性能之间取得了较好的平衡,适合在桌面级应用中使用,例如智能写作辅助工具、代码生成器或知识问答系统。
【核心优势】
推理能力:通过知识蒸馏技术,该模型在数学、编程和逻辑推理任务上表现出色。
高效部署:支持本地GPU、云端推理和 Docker 容器等多种部署方式。
适用场景:适合普通文本生成工具、小型企业日常文本处理等。
【应用场景势】
智能写作:为用户提供高质量的文本生成和语法检查功能。
代码生成:帮助开发者快速生成代码片段。
知识问答:在专业领域提供准确的知识问答服务。
DeepSeek-R1-Distill-Qwen-7B 是一个在推理效率和资源消耗之间达到良好平衡的模型,适合需要高效推理能力但资源有限的用户。
二、环境准备
1、资源配置
PyTorch 2.3.0
Python 3.12(基于 Ubuntu 22.04 操作系统)
CUDA 版本:12.1
GPU:NVIDIA RTX 3090(24GB 显存)× 1
CPU:18 vCPU,AMD EPYC 9754(128 核处理器)
内存:60GB
硬盘:系统盘30GB
2、环境验证
1)CUDA可用性检查:
import torchprint(torch.cuda.is_available()) # 应输出Trueprint(torch.cuda.get_device_name(0)) # 显示GPU型号
通过这段代码,我们可以快速验证 CUDA 是否正常可用。torch.cuda.is_available()函数用于检查 CUDA 是否能够被 PyTorch 正确识别和使用,如果输出True,则表明 CUDA 环境配置正确;torch.cuda.get_device_name(0)函数用于获取当前使用的 GPU 型号,方便我们确认 GPU 信息。
2)显存容量验证:
print(torch.cuda.get_device_properties(0).total_memory/1024**3) # 显示显存容量(GB)此代码用于获取当前 GPU 的显存容量,以 GB 为单位输出。

在部署模型前,准确了解显存容量至关重要,它可以帮助我们判断当前硬件是否满足模型的运行需求,避免因显存不足导致模型运行失败。
三、模型部署全流程
1、安装依赖
1)更换pip 源:为了加速依赖包的下载过程,我们首先更换 pip 源。执行以下命令:
python -m pip install --upgrade pippip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
将pip 升级到最新版本,确保能够使用最新的功能和特性;接着将 pip 的源设置为清华大学的镜像源,该镜像源具有高速稳定的特点,能够显著提升依赖包的下载速度。
2)接下来,安装所需的Python库:
pip install requests==2.32.3pip install fastapi==0.115.8pip install uvicorn==0.34.0pip install transformers==4.48.2pip install huggingface-hub==0.28.1pip install accelerate==1.3.0pip install modelscope==1.22.3
依赖安装优化方案:为减少依赖冲突,也可以采用下面的组合安装方式:
# 使用组合安装减少依赖冲突pip install "fastapi>=0.115.8" "uvicorn>=0.34.0" \"transformers>=4.48.2" "huggingface-hub>=0.28.1" \"accelerate>=1.3.0" "modelscope>=1.22.3" \--extra-index-url https://pypi.tuna.tsinghua.edu.cn/simple
3)加速技巧
添加环境变量避免重复下载
export HF_HUB_ENABLE_HF_TRANSFER=1export HF_HUB_OFFLINE=1
HF_HUB_ENABLE_HF_TRANSFER=1启用高效文件传输功能,在需要下载大模型时,能够显著提升下载速度。HF_HUB_OFFLINE=1启用离线模式,适用于离线环境或减少远程依赖的场景。在离线环境中,提前下载好所需模型和依赖,然后启用离线模式,可以确保项目的正常运行,避免因网络问题导致的错误。
2、模型下载
为了下载和管理预训练模型,我们使用modelscope库(必须提前安装modelscope)。modelscope提供了丰富的预训练模型以及灵活的下载和管理方式。
创建一个名为download.ipynb的文件,并输入以下代码:
from modelscope.hub.snapshot_download import snapshot_download# 下载预训练模型并指定缓存路径model_dir = snapshot_download('deepseek-ai/DeepSeek-R1-Distill-Qwen-7B', cache_dir='/root/autodl-tmp', revision='master')执行代码后,模型将被下载到指定路径,为后续的推
理和部署做好准备。
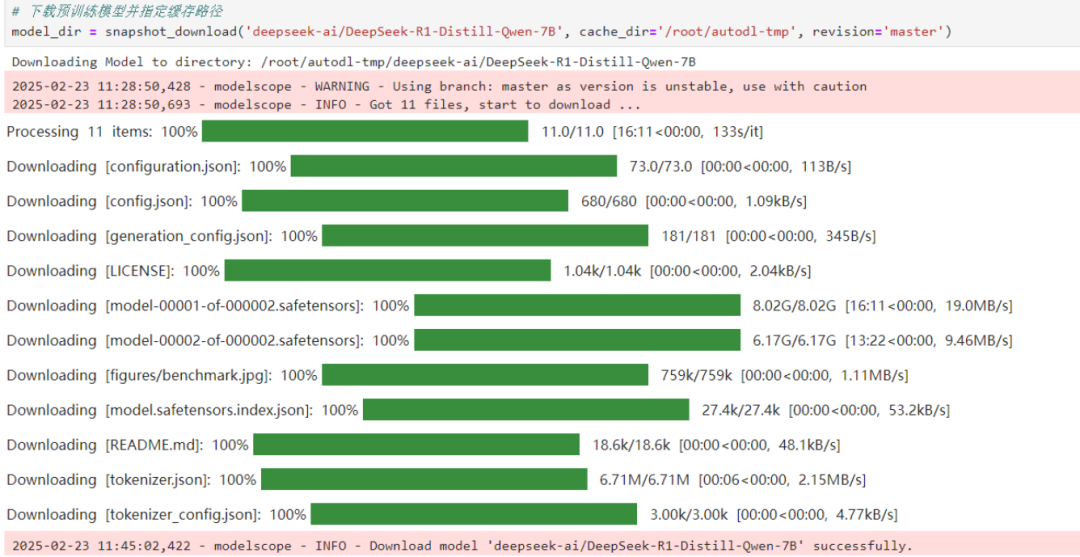
注意:下载过程中要确保网络稳定,路径设置正确,否则可能会下载失败。
代码说明:snapshot_download 函数:这是ModelScope 提供的工具函数,用于直接下载模型文件到指定路径。
参数说明:model_id:模型的唯一标识符,这里是 deepseek-ai/DeepSeek-R1-Distill-Qwen-7B。cache_dir:指定模型文件的缓存路径。你可以根据需要修改为其他路径,例如 /path/to/your/directory。revision:指定模型的版本,默认为 master。
3、API服务核心代码
创建一个api_test.py文件,文件内容如下:
from fastapi import FastAPI, Requestfrom transformers import AutoTokenizer, AutoModelForCausalLMimport uvicorn, json, datetime, torch, re# 设备配置DEVICE = "cuda"DEVICE_ID = "0"CUDA_DEVICE = f"{DEVICE}:{DEVICE_ID}"def torch_gc():if torch.cuda.is_available():with torch.cuda.device(CUDA_DEVICE):torch.cuda.empty_cache()torch.cuda.ipc_collect()app = FastAPI().post("/")async def create_item(request: Request):global model, tokenizerjson_post = await request.json()prompt = json_post.get('prompt')# 模型推理过程messages = [{"role": "user", "content": prompt}]input_ids = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)model_inputs = tokenizer([input_ids], return_tensors="pt").to(model.device)generated_ids = model.generate(model_inputs.input_ids, max_new_tokens=8192)# 响应处理response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]think, answer = re.search(r'<think>(.*?)(.*)', response, re.DOTALL).groups()return {"response": response,"think": think.strip(),"answer": answer.strip(),"status": 200,"time": datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")}if __name__ == '__main__':# 注意修改模型实际路径model_path = '/root/autodl-tmp/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B'tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)model = AutoModelForCausalLM.from_pretrained(model_path,device_map=CUDA_DEVICE,torch_dtype=torch.bfloat16)uvicorn.run(app, host='0.0.0.0', port=6006)
注意:请确保修改model_path为你下载模型的实际路径。
4、部署API服务
python api_test.py执行上述命令,即可启动 API 服务。

此时,模型已经部署为一个可以通过 HTTP 请求访问的 API,等待接收用户的请求并进行处理。
四、服务调用示例
1、CURL命令调用
默认部署在 6006 端口,通过 POST 方法进行调用,可以使用 curl 调用,如下所示:
curl -X POST "http://127.0.0.1:6006" \-H 'Content-Type: application/json' \-d '{"prompt": "请简单介绍一下deepseek"}'
模型响应如下:

2、Python代码调用
import requestsdef get_completion(prompt):response = requests.post('http://127.0.0.1:6006',json={"prompt": prompt})return response.json()if __name__ == '__main__':result = get_completion("请创作一首七言绝句")print(result['answer'])
模型回复如下:
“`
嗯,用户让我创作一首七言绝句。首先,我得回忆一下七言绝句的结构,四句,每句七个字,通常讲究平仄和对仗。然后,我得确定主题。用户没有指定主题,我可以选择一个比较通用的,比如自然景色,这样比较容易引起共鸣。
接下来,我考虑用哪些意象。山花、夕阳、薄雾、飞鸟这些元素比较适合表现宁静和美丽的画面。然后,我开始构思每句的内容。第一句可以描绘山花在夕阳下的美景,第二句描绘薄雾中的飞鸟,第三句表达时间的流逝,第四句用飞鸢象征自由和永恒。
然后,我注意对仗和押韵。第一句和第二句的结构要对仗,比如“山花”对“飞鸟”,“夕阳”对“薄雾”。“红紫”和“青灰”形成色彩对比,增加画面的层次感。
在押韵方面,我选择“花”、“鸟”、“曲”、“思”作为韵脚,虽然不完全押韵,但整体读起来还是流畅的。最后,加上赏析部分,解释诗中的意象和情感表达,让用户更好地理解创作意图。
整个过程需要确保语言简洁,意境深远,同时符合七言绝句的格律要求。这样,一首简短而富有画面感的诗就完成了。
</think>
《七绝·咏山花》
山花红紫映夕阳,雾里飞鸟日初残。
百鸟纷争争自由,一曲高歌向天山。
赏析:这首作品描绘了一幅山花与夕阳相映成趣的美丽画卷。通过“山花红紫”与“飞鸟青灰”的色彩对比,营造出丰富的视觉效果。后两句以百鸟争自由、一曲歌天山为喻,表达了对自由精神的赞美和向往。
“`
从模型的响应结果中可以发现,大模型不仅出色地完成了我们的请求——成功编写了一首七言绝句,还详细展示了其思考与推理的过程。
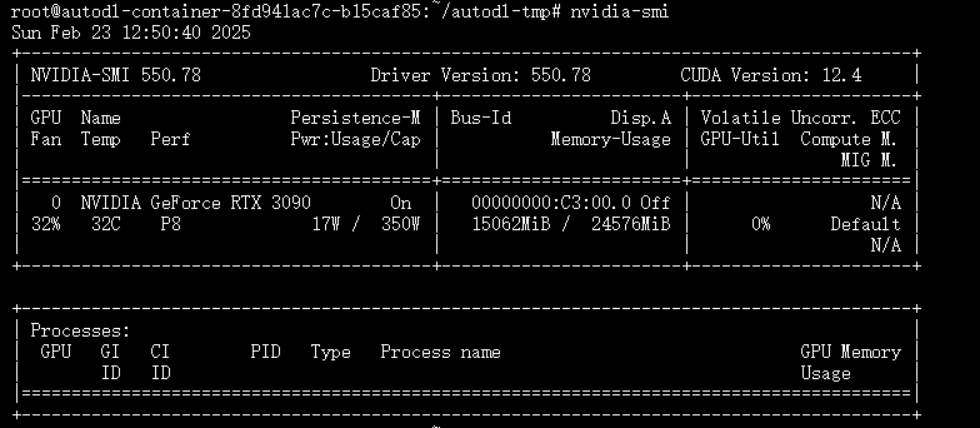
资源消耗查看:(消耗GPU大概15G左右)
五、常见问题
1、路径配置:确保cache_dir和 model_path与实际存储路径一致。如果路径配置错误,模型将无法正确下载或加载,导致程序运行失败。在修改路径时,要仔细检查路径的准确性,包括目录结构和文件名的拼写。
2、端口冲突:如果在启动API 服务时遇到端口冲突,可以通过修改uvicorn.run()中的port参数更换端口。例如,将port参数修改为6007,则 API 服务将在http://127.0.0.1:6007上运行。在选择新端口时,要确保该端口没有被其他程序占用,可以使用一些端口检测工具进行检查。
3、内存管理:定期调用torch_gc()清理显存,建议部署在 24G 以上显存的 GPU 环境。模型在运行过程中会占用大量显存,如果不及时清理,可能会导致显存溢出,使程序崩溃。在高并发请求或长时间运行的情况下,更要注意显存的管理,确保服务的稳定性。
总结
我们成功地实现了模型的部署和调用。希望这篇技术指南能帮助你快速上手相关技术,开启基于大语言模型的应用开发之旅。如果你在部署过程中遇到任何问题,欢迎参考本文的步骤和解决方案,也可以查阅相关文档或寻求社区的帮助。在未来的开发中,你可以进一步探索模型的优化和扩展,如调整模型参数、增加功能模块等,以满足不同的业务需求。
(文:小兵的AI视界)