


翻译自:https://huggingface.co/spaces/nanotron/ultrascale-playbook
作者:nanotron
校正:pprp

Sequence Parallel 序列并行
序列并行性(SP)涉及将模型中由张量并行性(TP)未处理的部分(如 Dropout 和 LayerNorm), 对于activation (shape为 [ bs, seq len, hidden dimension]沿输入序列维度( seq len) 进行拆分,而不是hidden dimension.
💡 序列并行性这个术语有点过载:本节中的序列并行性
SP与张量并行性TP紧密耦合,并适用于dropout和层归一化操作。然而,当我们转向更长的序列时,注意力计算将成为瓶颈,这需要像Ring-Attention这样的技术,这些技术有时也被称为 序列并行性SP,但我们将它们称为 上下文并行Context Parallel以区分两种方法。所以每次你看到序列并行性时,请记住它是与张量并行性一起使用的(与可以独立使用的上下文并行性相对)。
之所以在LayerNorm之前需要 all-reduce 是因为其需要完整的hidden dimension 来计算均值和方差。
其中 μ = mean(x), σ² = var(x) 需要在 hidden dimension h 上计算。
尽管这些操作在计算上非常cheap,但它们仍然需要大量的activation memory,因为它们需要完整的隐藏维度。SP 允许我们通过沿 序列维度seq 分割来将这个内存负担分散到多个 GPU 上。
在实践中,我们将从左图过渡到右图:
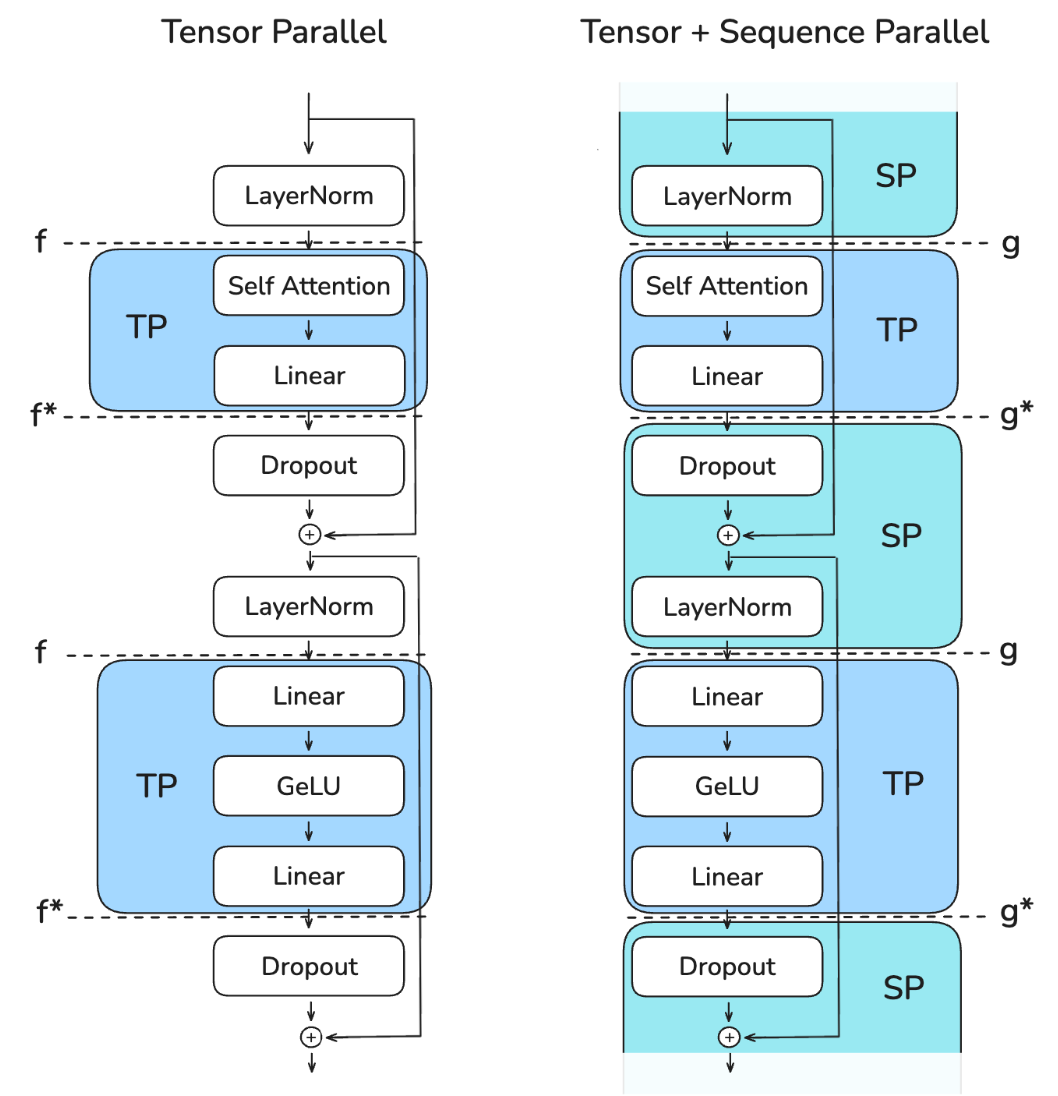
该图展示了如何通过不同的 Collective Operations(标记为“f”和“g”)在张量并行和序列并行区域之间进行转换。关键挑战是在保持内存使用低的同时确保正确性,并高效地管理这些转换。
在前向传播中:
-
“f” 是一个空操作(no operation),因为激活已经在各个 rank 之间复制。 -
“f*” 是一个 all-reduce操作,用于同步激活并确保正确性
在反向传播中:
-
“f*” 是一个空操作,因为梯度已经在各个 rank 之间重复了 -
“f” 是一个 all-reduce操作,用于同步梯度
这些操作 “f” 和 “f*” 被称为共轭对,因为它们相互补充——当一个在正向操作中为无操作时,另一个在反向操作中为全归约,反之亦然。
对于序列并行性(SP),我们使用标记为“g”和“g*”的不同操作。具体来说,我们避免在 SP 区域使用 all-reduce,因为这需要收集全部激活值并增加我们的峰值内存使用,从而违背了 SP 的目的。下面详细展开:
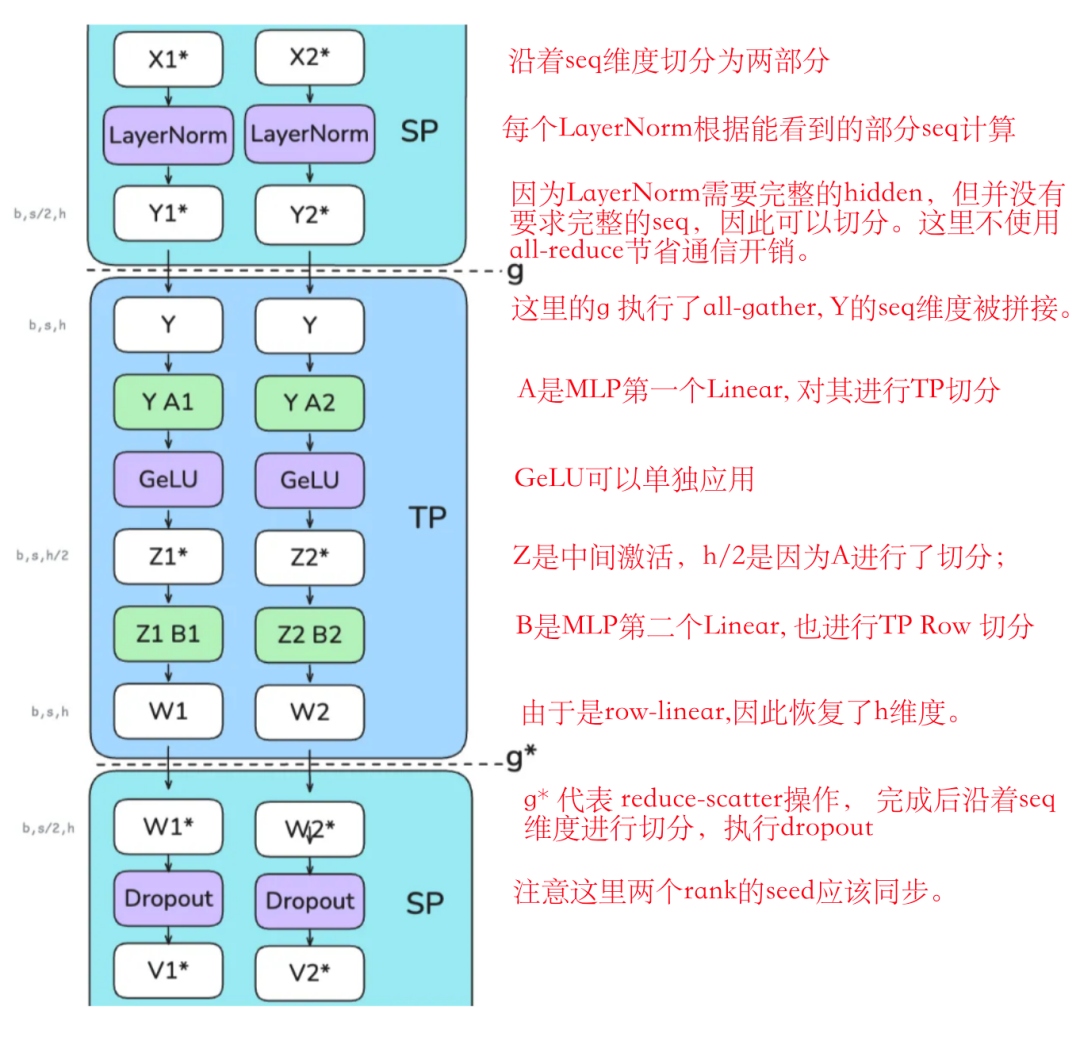
序列并行的一个关键优势是,它减少了我们需要存储的最大激活大小。在仅使用张量并行时,我们必须在多个点存储形状为(b,s,h)的激活值。然而,通过使用序列并行,最大激活大小减少为 b⋅s⋅h / tp ,因为我们总是沿着序列维度或隐藏维度进行分割。
用表格来总结以上分片过程(part1: hidden size和seq维度变化;
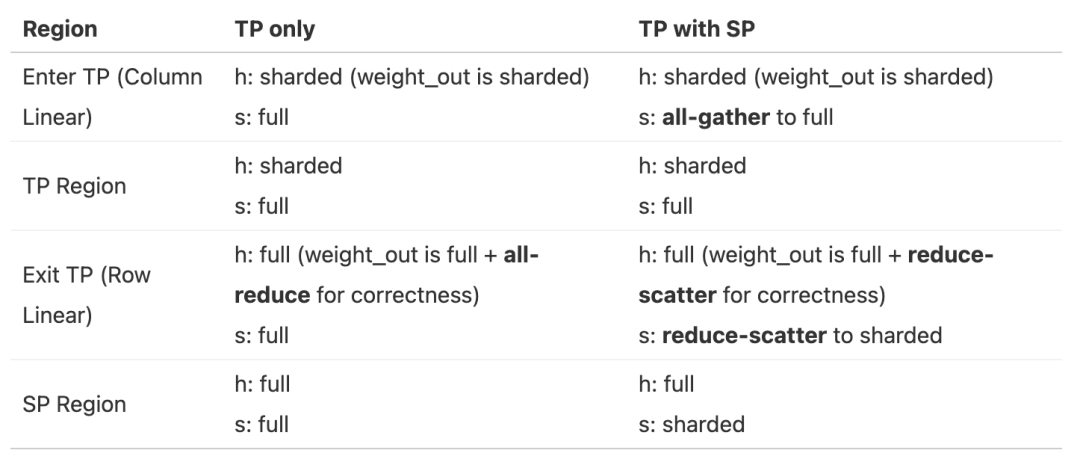
(part2: embedding Layer变化;

再看一下使用了SP以后的激活情况,跟上图对比,SP可以大幅度降低每个GPU的mem占用,尤其是对16k长序列场景下。

TP+SP是否会比单纯TP更耗通信?
-
在纯 TP 的前向传播中,我们每个 Transformer 块有两个 all-reduce 操作,而在 SP 中,我们每个 Transformer 块有两个 all-gather 和两个 reduce-scatter 操作。所以 SP 的通信操作数量是 TP 的两倍。 -
但是由于 all-reduce 操作可以被分解为 all-gather + reduce-scatter,它们在通信方面实际上是等效的。对于反向传播,只是使用每个操作的共轭(no-op ↔ all-reduce 和 all-gather ↔ reduce-scatter),推理方式相同。
编者注:All-reduce 可以分解为 reduce-scatter 和 all-gather,因为 reduce-scatter 先归约并分散数据,all-gather 再收集完整结果。
使用TP+SP的 profiling如下图所示,每层有4个通信操作(2个来自MLP,两个来自MHA):
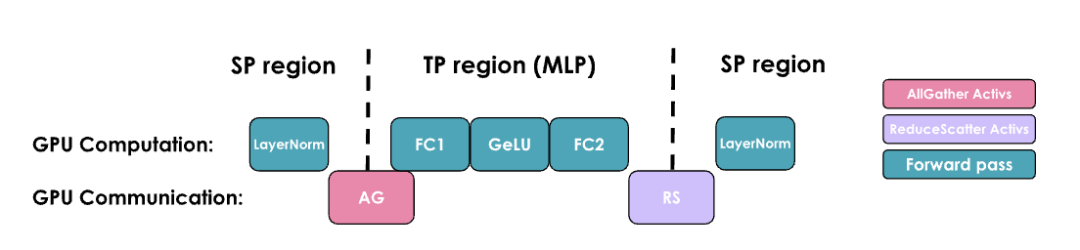
就像传统的TP一样,TP+SP也不能轻易与计算操作重叠,这使得吞吐量在很大程度上依赖于通信带宽。这里,像传统TP一样,TP+SP通常只在单个节点内进行(保持TP度数不超过每个节点的GPU数量,例如TP≤8)。
下面继续benchmark,随着TP rank增加,通信开销变化(实验setting seq len 4096, 模型大小3B):
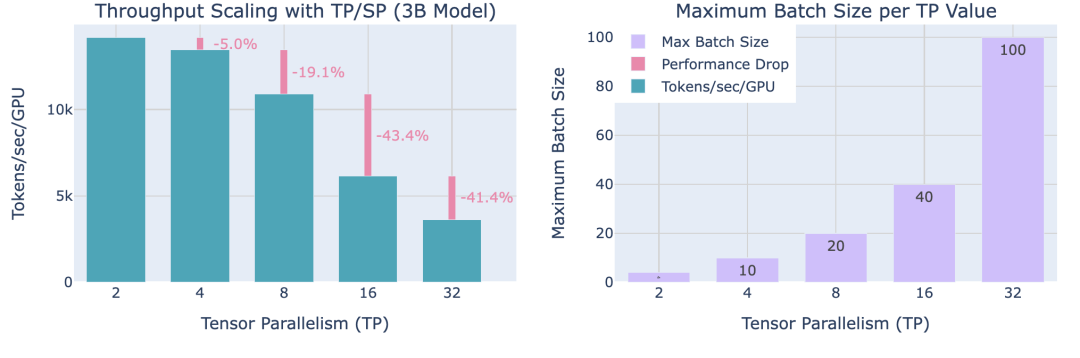
可以得出结论:虽然更高的并行度通过减少激活内存使得处理更大的Batch成为可能,但它们也会减少每个GPU的吞吐量,特别是当并行度超过节点内GPU数量时。
总结一下观察结果:
-
对于这两种方法,注意到从TP=8移动到TP=16时,性能下降最为明显,因为这是从仅在单个节点内(NVLink)通信,转向跨节点通信(EFA)的时候。 -
使用TP和SP时,激活的内存节省帮助我们适应比仅使用TP时更大的Batch。
到这里我们已经看到 TP 如何通过沿隐藏维度分割注意力和前馈操作,将激活操作分割到多个 GPU 上,以及 SP 如何通过沿序列维度分割,自然地补充了TP。
注意:
由于SP区域中的LayerNorm操作在序列的不同部分进行,因此它们的梯度将在TP的不同rank之间有所不同。为了确保权重保持同步,我们需要在反向传播过程中对它们的梯度进行all-reduce操作,这类似于数据并行(DP)中确保权重同步的方式。然而,由于LayerNorm的参数相对较少,这个通信开销较小。
然而,TP和SP有两个限制:1️⃣ 如果增加序列长度,激活内存在TP仍然会膨胀;2️⃣ 如果模型太大,无法适应TP=8,那么由于跨节点连接性问题,遇到巨大的性能下降。
可以通过Context Parallel上下文并行解决问题 1️⃣ ;用Pipeline Parallel流水线并行解决问题 2️⃣;
Context Parallel 上下文并行
通过张量并行TP和序列并行SP,可以显著降低每个GPU的内存需求,因为模型权重和激活值均分布在各个GPU上。然而,当训练的序列越来越长(例如当每个序列扩展到128k个token甚至更多时),仍可能超出单节点可用内存,因为在TP区域内仍需处理完整的序列长度。
此外,即使采用gradient checkpointing 的方法(这会带来约30%的沉重计算开销),我们仍需在内存中保留部分层边界的激活值,而这些激活值随序列长度呈线性增长。来看看上下文并行如何帮助我们:
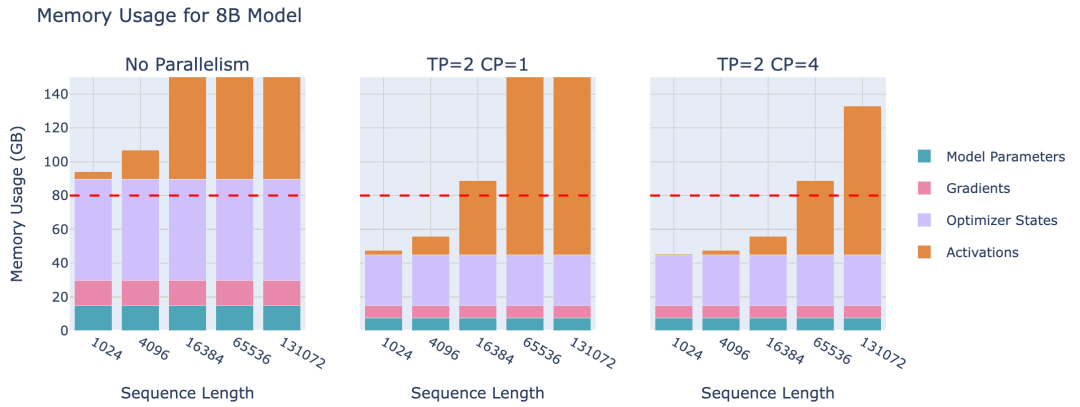
上下文并行的核心思想是 将序列并行的方法(也就是沿序列长度进行拆分)的思路应用到已经采用张量并行的模块上。我们将对这些模块沿两个维度进行拆分,从而也减少序列长度带来的影响。经过前面所讨论的内容,你会发现这种方法非常直观,但这里有一个技巧,所以请保持警惕!
对于上下文并行CP,就像序列并行SP一样,将沿序列维度拆分输入,但这次我们对整个模型进行拆分,而不仅仅是对之前Tensor+Sequence并行中涉及的部分模型。
-
拆分序列不会影响大多数模块,如MLP和LayerNorm,因为它们对每个token的处理是独立的。它也不像TP那样需要昂贵的通信,因为只拆分了输入而非权重矩阵。就像数据并行一样,在计算梯度后,会启动一次all-reduce操作以在上下文并行组内同步梯度。 -
有一个重要例外需要特别注意,那就是注意力模块。 -
在注意力模块中,每个token需要访问来自所有其他序列token的键/值对; -
在Casual Attention 的情况下,至少需要关注每个前面的token。 -
由于上下文并行是沿序列维度将输入分布到各个GPU上,注意力模块将需要各个GPU之间进行充分通信,以交换必要的键/值数据。
如果采用简单的方法会非常昂贵。但有没有办法能更高效、更快速地完成这一操作呢?幸运的是,有一种核心技术可以高效地处理键/值对的通信,叫做环形注意力 Ring Attention。
注意:
上下文并行性与 Flash Attention 在概念上存在一些相似之处——这两种技术都依赖于在线 softmax 计算以减少内存使用。虽然 Flash Attention 专注于在单个 GPU 上优化注意力计算本身,而上下文并行性通过将序列分布到多个 GPU 上实现内存减少。
发现环状注意力 Ring Attention
在这个注意力机制的实现中,每个 GPU 首先启动异步通信操作,将其键/值对发送到其他 GPU。在等待其他 GPU 的数据时,它计算内存中已有数据的注意力分数。理想情况下,在完成计算之前,从另一个 GPU 接收到下一个键/值对,使 GPU 能够在完成第一次计算后立即开始下一轮计算。
举例说明。假设有 4 个 GPU 和一个包含 4 个Token的输入。最初,输入序列在序列维度上均匀分割,因此每个 GPU 将恰好有一个Token及其对应的 Q/K/V 值。假设 Q1、K1 和 V1 分别代表第一个Token的查询、键和值,它们位于第 1 个 GPU 上。注意力计算需要 4 个时间步来完成。在每一个时间步,每个 GPU 执行这三个连续操作:
-
以非阻塞的方式将“当前的K和V”发送给下一台机器(在非阻塞模式下的最后一个时间步除外),以便在此步骤尚未完成时即可开始下一步骤 -
在本地对已拥有的“当前K和V”计算注意力得分 Attention Score. -
等待接收来自上一台GPU的K和V,然后返回到步骤1,此时“当前的K和V”即为刚刚从上一台GPU接收到的K/V对。
执行这 3 个步骤四次以完成注意力计算。
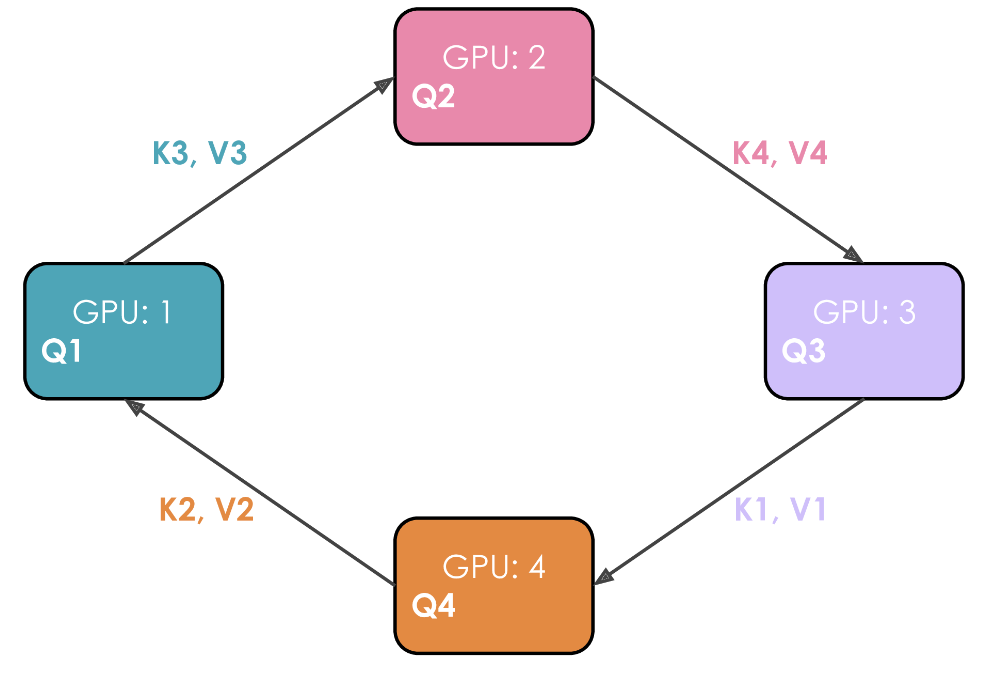
从上图中很明显就能看出作者为什么选择将这种方法称为环状注意力。
然而有一个大问题,那就是环状注意力(Ring Attention)的简单实现导致因果注意力矩阵的形状产生了强烈的失衡。让通过考虑带有因果注意力掩码的注意力得分矩阵来查看 SoftMax 的计算:
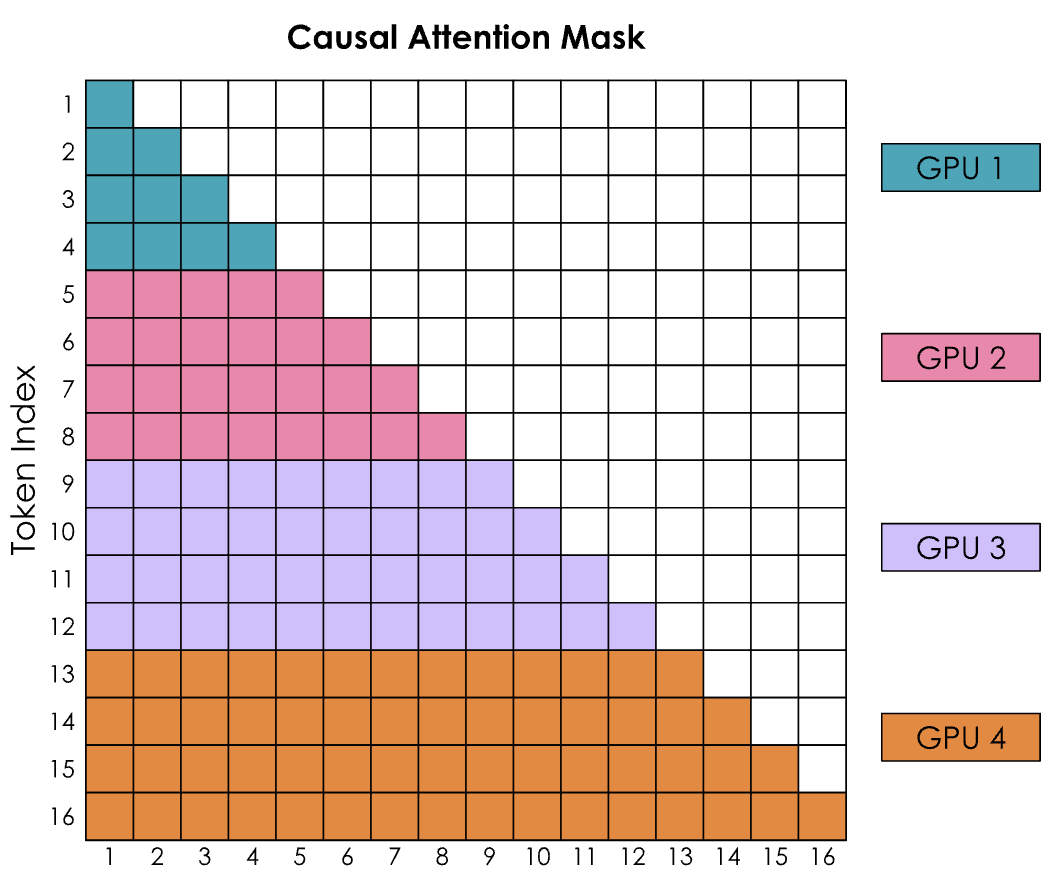
编者注:在Transformer模型的注意力机制中,这种矩阵通常表示注意力掩码,其中行(y轴)代表查询(query)token,列(x轴)代表键(key)token。矩阵中的每个单元格(y, x)表明查询token y是否可以关注键token x。
SoftMax 是按行计算的,这意味着每当 GPU 收到一行中的所有标记时,就可以进行计算。
-
GPU1 可以立即计算,因为它从标记 1-4 开始,而 GPU1 实际上不需要从任何其他 GPU 接收任何信息。 -
GPU2 将需要等待第二轮才能也收到 1-4,从而获得标记 1-8 的所有值。此外,GPU1 似乎比所有其他 GPU 的工作量都要少。
如何更好的平衡计算呢?
Zig-zag Ring Attention 平衡版本实现
我们需要一种更好的方法来分配输入序列。这可以通过将非纯顺序的标记分配给 GPU,并通过稍微混合排序,使得每个 GPU 上都有早期和晚期标记的良好混合来实现。这种方法被称为之字形注意力 Zig-zag Ring Attention。
在这个新的配置中,注意力掩码将显示计算分布均匀,但如果计算彩色方格的数量,会发现计算现在均衡分布在所有 GPU 上。
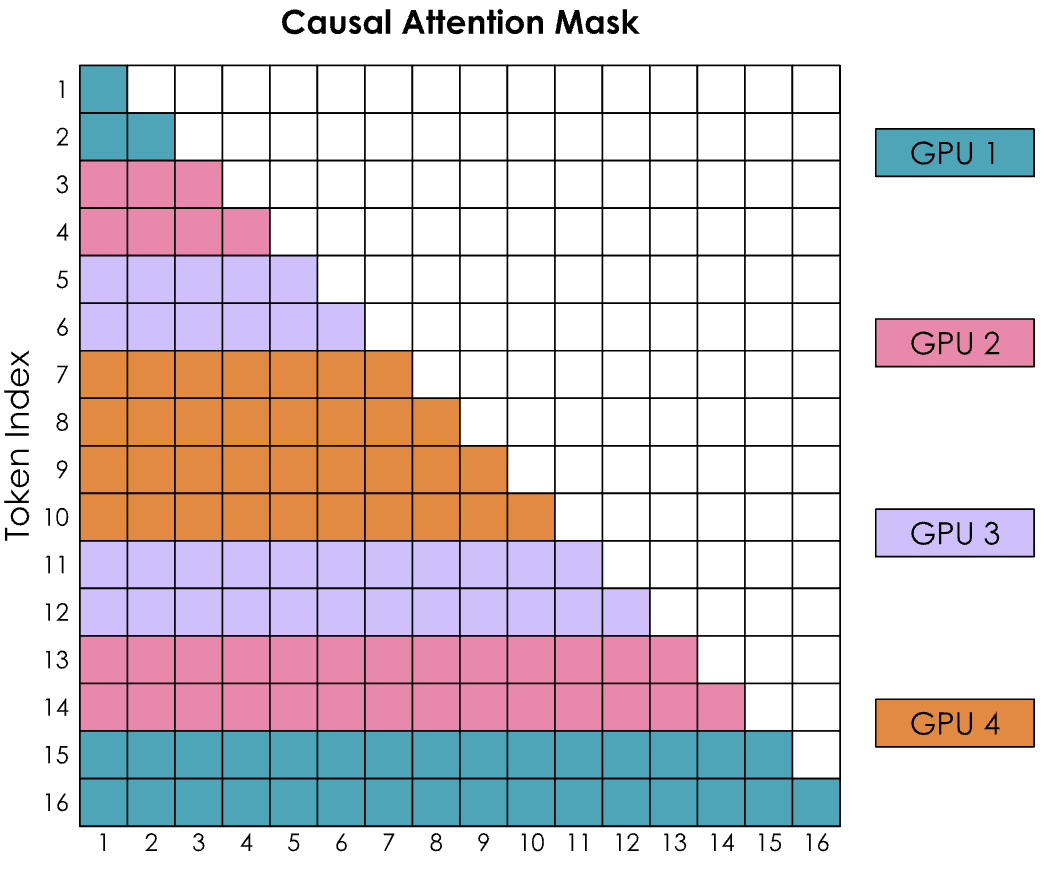
同时也会看到,为了完成所有行,每个 GPU 都需要从所有其他 GPU 获取信息。
一般有两种常见方式来重叠计算和通信:一种是通过执行一次通用的 all-gather操作,同时在每个GPU上重新组合所有KV(类似于Zero-3的方式);另一种是根据需要从每个GPU逐个收集KV对:
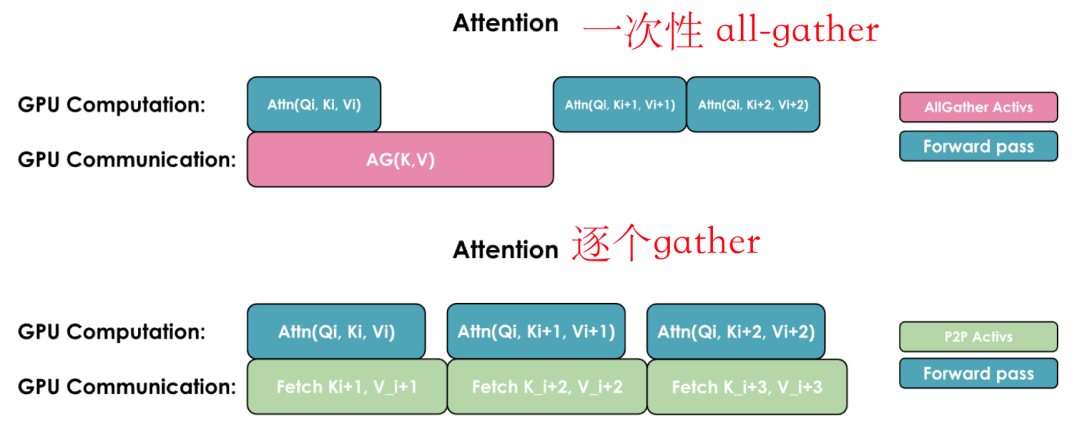
这两种实现方式的关键区别在于它们的通信模式和内存使用:
1. All-Gather实现:
-
所有GPU同时收集来自其他所有GPU的完整键/值对 -
需要更多的临时内存,因为每个GPU需要一次性存储完整的KV对 -
通信在一步内完成,但伴随较大的内存开销
2. All-to-All(Ring)实现:
-
GPU以环形模式交换KV对,每次传输一个数据块 -
更节省内存,因为每个GPU只需临时存储一个数据块 -
通信被分散并与计算重叠,尽管由于多次通信步骤会带来一些额外的基础延迟
到目前为止,我们已经看到如何通过TP在单个节点上拆分模型以驯服大模型,以及如何利用CP应对长序列带来的激活值爆炸问题。
然而,TP在跨节点扩展时并不理想,那么如果模型权重难以容纳在单个节点上,该怎么办?这时,另一种并行度——流水线并行,将派上用场!
Pipeline Parallel 流水线并行
在TP部分,当张量并行度超过单个节点的GPU数量(通常为4或8)时,会遇到带宽较低的“跨节点连接”,这会严重影响性能。可以通过在集群的多个节点上基准测试 all-reduce 操作清楚地看到这一点(每个节点有8块GPU):
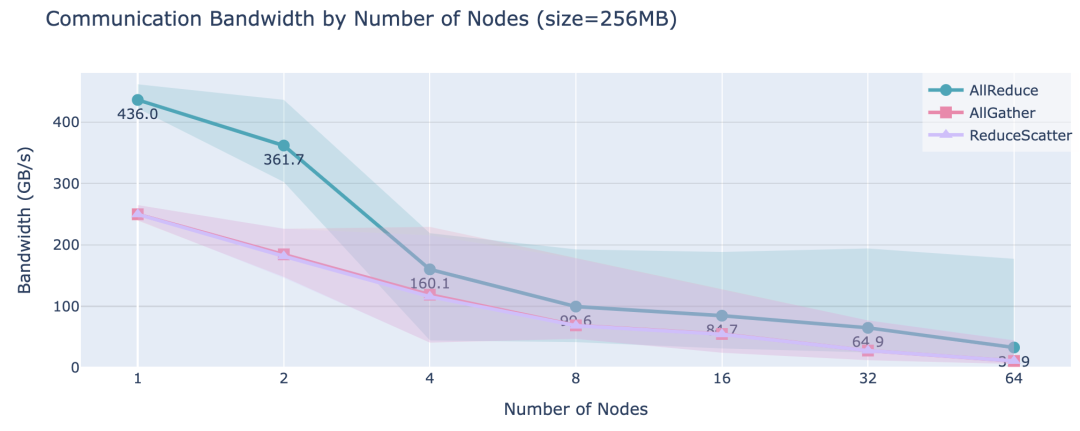
序列并行SP和上下文并行CP对于长序列有帮助,但如果序列长度并不是导致内存问题的根本原因,而是模型本身的大小,那么它们的作用就相对有限。
对于大模型(70B+),仅权重的大小就可能超出单个节点的4-8块GPU的承载能力。可以通过引入第四种(也是最后一种)并行方式来解决这个问题:“流水线并行 Pipeline Parallel”。
流水线并行是一种简单但强大的技术——将模型的层划分到多个GPU上!例如,如果有8块GPU,可以将第1-4层放在GPU 1上,第5-8层放在GPU 2上,以此类推。这样,每块GPU只需要存储和处理部分模型层,大幅减少了每块GPU的内存需求。来看看流水线并行在8B模型上的内存使用效果:
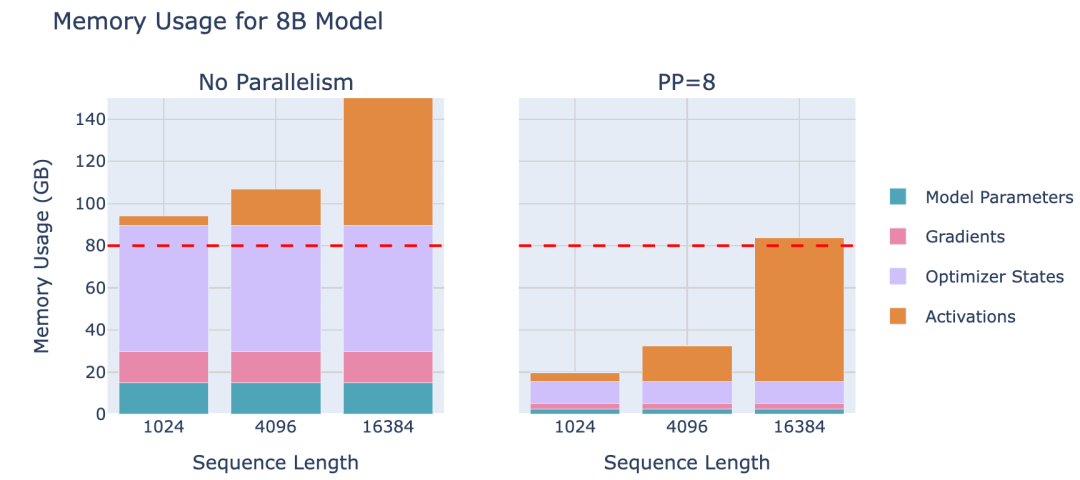
可以发现:虽然模型参数被很好地拆分到多个GPU上,但每块GPU上的激活内存仍然保持不变!这是因为每块GPU仍然需要处理整个数据Batch,只是处理的层不同。一个GPU计算出的激活将被发送到下一个GPU,以继续完成前向传播。
编者注:PP让人想到Zero-3的模型拆分,但是他们存在区别: (1) PP 将模型按照层(layer)纵向分割成多个阶段(stage),每个阶段分配给不同的计算设备(通常是 GPU)。比如,一个有 32 层的模型可以被分成 4 个阶段,每阶段包含 8 层,由 4 个 GPU 分别处理。(2)Zero3 并不直接按层分割模型,而是将模型的参数(权重、梯度和优化器状态)分片(shard)到多个设备上。每个设备持有整个模型的一部分参数,而不是特定的层。
这引入了一种新的通信模式:与ZeRO-3在数据并行中同步参数不同,在这里,我们是在GPU之间按顺序传递激活张量,形成一个“流水线”。虽然这个概念很简单,但高效地实现这一技术却颇具挑战。让我们深入探讨其具体细节!
在不同节点上拆分层 —— AFAB
假设简单地将模型的层分布到多个设备上,例如,第一个GPU处理前几层,第二个GPU处理模型的后续部分,以此类推。这样,前向传播过程就变成了依次将数据Batch沿着模型传递,并依次使用每个计算设备。
这种方法带来的第一个直接优势是:所需的互连带宽较低,因为只在模型的少数位置传输中等大小的激活值。与张量并行不同,张量并行需要在每层内部进行多次通信,而这里的通信次数要少得多。
你可能已经开始隐约察觉到即将出现的问题:“依次” 和 “顺序执行”?在并行计算的世界里,这听起来似乎效率不高,特别是在刚刚讨论了计算与通信重叠的重要性之后。
确实如此!流水线并行 PP 的主要挑战在于 如何有效地绕过这种顺序执行的限制,确保GPU始终保持忙碌,避免一个GPU在计算时,其他GPU处于等待状态。下面是一个简单的前向和反向传播示例,展示了GPU的利用情况(数字表示模型的层编号), 展示了一个16层4卡流水线并行:
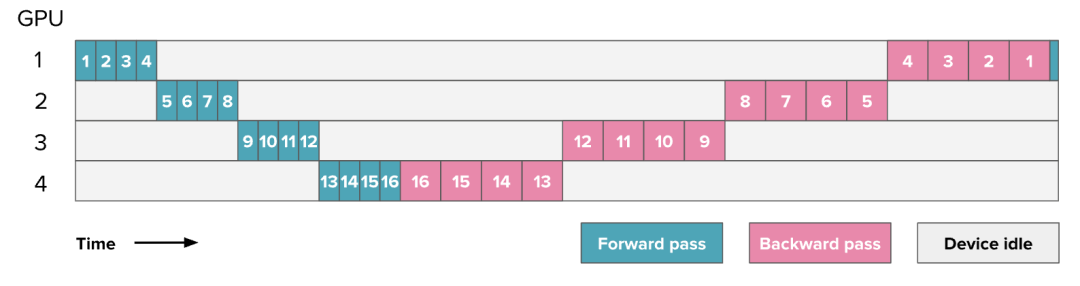
图中灰色部分表示剩余的空闲时间,通常称为“气泡(bubble)”。看到这些空闲时间,你可能会感到沮丧,毕竟我们已经花费了大量时间来优化吞吐量。我们可以通过计算“气泡”导致的额外时间来衡量流水线并行的效率。假设 和 分别是单个Micro Batch在流水线的一个阶段上进行前向传播和反向传播所需的时间(通常假设 ,在上图中可以观察到)。如果能够完美并行化,理想总时间应为 。但由于流水线气泡的存在,额外的时间为 (其中 是流水线并行度,即上图中的GPU数量),即每个GPU在其他GPU计算时的等待时间。可以计算额外气泡时间与理想时间的比值:
当增加流水线数时,气泡时间随之增加,GPU利用率下降。可以看出,在一个简单的实现中,流水线气泡可能会非常大!幸运的是,已经有多种流水线并行方案被设计出来,以减少气泡的大小。
第一个优化方法是,将Batch拆分成更小的micro batches,使它们可以并行或近乎并行地处理,就像在数据并行中做的那样。例如,当第二块GPU在处理Micro-Batch1时,第一块GPU可以开始处理Micro-Batch2。以下是一个使用8个Micro-Batch的调度方案:
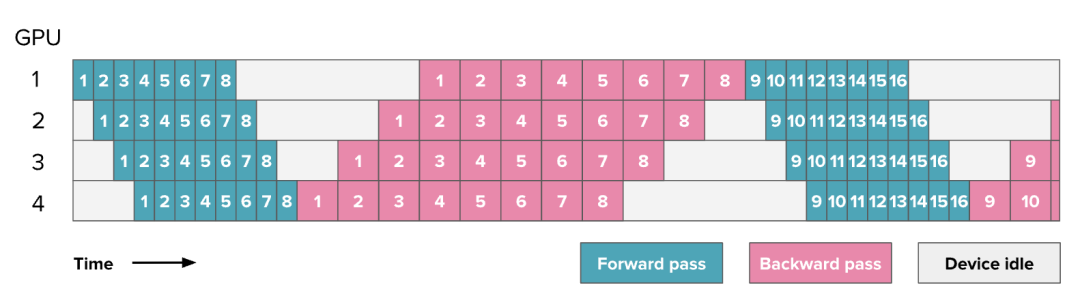
注意:
在之前的图表中,数字代表的是模型的层数,而从这一张图开始,所有流水线并行相关的图表中的数字都表示 Micro Batch。可以将每个方块理解为包含多个层,就像前一张图所示的那样。
上述调度方式被称为全前向-全反向(AFAB, All-Forward-All-Backward)调度,因为它先执所有前向传播,然后再执行所有反向传播。
其优势在于前向和反向传播仍然是严格顺序的,因此可以保持模型训练代码的整体组织,使这种流水线并行实现方式成为最容易实现的一种。
下面是Picotron的AFAB 流水线实现代码:
def train_step_pipeline_afab(model, data_loader, tensor_shapes, device, dtype):
logging_loss: torch.float32 = 0.0
input_tensors, output_tensors = [], []
requires_grad_sync = pgm.process_group_manager.cp_dp_world_size > 1
# 从这里开始分前向的micro batch
for _ in range(data_loader.grad_acc_steps): # All forward passes
input_tensor = pipeline_communicate(operation='recv_forward', shapes=tensor_shapes, device=device, dtype=dtype)
batch = next(data_loader)
batch["hidden_states"] = input_tensor.to(device) if input_tensor isnotNoneelse input_tensor
output_tensor = model.forward(input_ids=batch["input_ids"].to(device), position_ids=batch["position_ids"].to(device), hidden_states=batch["hidden_states"])
pipeline_communicate(operation='send_forward', tensor=output_tensor, device=device, dtype=dtype)
# calculate loss on the last stage
if pgm.process_group_manager.pp_is_last_stage:
output_tensor = F.cross_entropy(output_tensor.transpose(1, 2), batch["target_ids"].to(device), reduction='mean')
logging_loss += output_tensor.item() / data_loader.grad_acc_steps
input_tensors.append(input_tensor)
output_tensors.append(output_tensor)
# 这里开始反向
for ith_microbatch in range(data_loader.grad_acc_steps): # All backward passes
if requires_grad_sync:
is_last_iteration = (ith_microbatch == data_loader.grad_acc_steps - 1)
model.require_backward_grad_sync = is_last_iteration
output_tensor_grad = pipeline_communicate(operation='recv_backward', shapes=tensor_shapes, device=device, dtype=dtype)
input_tensor, output_tensor = input_tensors.pop(0), output_tensors.pop(0)
input_tensor_grad = model.backward(input_tensor, output_tensor, output_tensor_grad)
pipeline_communicate(operation='send_backward', tensor=input_tensor_grad, device=device, dtype=dtype)
return logging_loss
现在我们来估算这种方法的流水线气泡时间。在第一个示例中,理想情况下处理 个Micro-Batch所需的时间为 :
可以通过增加Micro-Batch数量 来减少流水线阶段的不效率,从而按 的比例减少气泡的大小。
然而,除了气泡问题,还有另一个令人头疼的问题:存储所有激活值所需的内存。需要将所有的激活值保留在内存中,直到反向传播阶段开始,这会导致内存使用量迅速膨胀,从而使这些流水线并行实现变得不可行。那么,能否找到一种方法,避免这种内存膨胀呢?
既然内存膨胀是由反向传播阶段所需的激活存储导致的,可以尝试在仍然执行部分前向传播时就开始执行反向传播,这样可以尽早释放部分激活,减少内存占用。
这种方案被称为 One-forward-one-backward (1F1B), 因为中间/稳定状态涉及交替执行一次正向和一次反向传递。总体思路是尽可能早地开始执行反向传递。这个调度看起来是这样的:
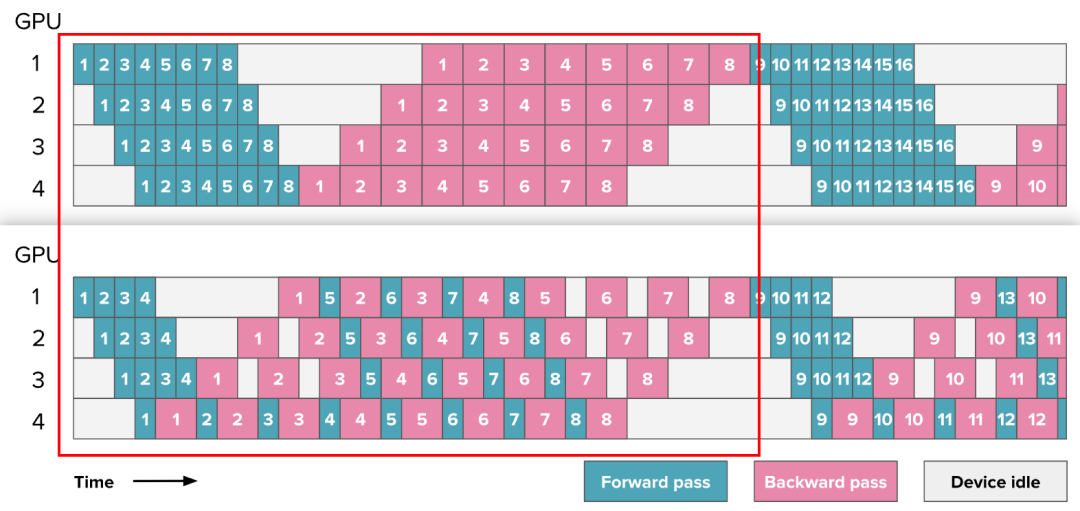
可以发现,修改前后并没有提高训练效率,气泡仍然保持相同大小。
然而,我们只需要存储 p 次micro batch的激活(其中 p 是流水线并行度),而不是 m(其中 m 是Micro Batch数),这可以减少在 AFAB 计划中遇到的激活内存爆炸问题。因此,可以添加更多的微Batch,这实际上会减少气泡。
这种设置的复杂性(如上图所示)主要在于前向和反向传播不再是完全顺序执行的,而是在设备之间并行交错执行。这意味着,需要在每个设备上独立调度从前向传播到反向传播的切换,而不是像往常那样在一个简单的中央训练循环中统一调度。
这也是流水线并行通常需要对训练代码和建模代码进行大幅修改的原因之一。
在 picotron 中找到 1F1B 的完整实现:
def train_step_pipeline_1f1b(model, data_loader, tensor_shapes, device, dtype):
num_warmup_microbatches = min(pgm.process_group_manager.pp_world_size - pgm.process_group_manager.pp_rank - 1, data_loader.grad_acc_steps)
num_microbatches_remaining = data_loader.grad_acc_steps - num_warmup_microbatches
logging_loss, input_tensors, output_tensors = 0.0, [], []
requires_grad_sync = pgm.process_group_manager.cp_dp_world_size > 1
def _forward_step(input_tensor):
batch = next(data_loader)
batch["hidden_states"] = input_tensor.to(device) if input_tensor isnotNoneelse input_tensor
output_tensor = model.forward(input_ids=batch["input_ids"].to(device), position_ids=batch["position_ids"].to(device), hidden_states=batch["hidden_states"])
# calculate loss on the last stage
if pgm.process_group_manager.pp_is_last_stage:
output_tensor = F.cross_entropy(output_tensor.transpose(1, 2), batch["target_ids"].to(device), reduction='mean')
nonlocal logging_loss
logging_loss += output_tensor.item() / data_loader.grad_acc_steps
return output_tensor
for _ in range(num_warmup_microbatches): # Warmup forward passes
input_tensor = pipeline_communicate(operation='recv_forward', shapes=tensor_shapes, device=device, dtype=dtype)
output_tensor = _forward_step(input_tensor)
pipeline_communicate(operation='send_forward', tensor=output_tensor, device=device, dtype=dtype)
input_tensors.append(input_tensor)
output_tensors.append(output_tensor)
if num_microbatches_remaining > 0:
input_tensor = pipeline_communicate(operation='recv_forward', shapes=tensor_shapes, device=device, dtype=dtype)
if requires_grad_sync:
model.require_backward_grad_sync = False
for ith_microbatch in range(num_microbatches_remaining): # 1F1B steady state
is_last_iteration = (ith_microbatch == num_microbatches_remaining - 1)
output_tensor = _forward_step(input_tensor)
output_tensor_grad = bidirectional_pipeline_communicate(operation='send_fwd_recv_bwd', send_tensor=output_tensor, recv_shapes=tensor_shapes, device=device, dtype=dtype)
input_tensors.append(input_tensor)
output_tensors.append(output_tensor)
input_tensor, output_tensor = input_tensors.pop(0), output_tensors.pop(0)
# Trigger gradient sync on the last microbatch but only when last rank (the one that has num_warmup_microbatches = 0) has finished computing its backward pass.
if num_warmup_microbatches == 0and is_last_iteration:
model.require_backward_grad_sync = True
input_tensor_grad = model.backward(input_tensor, output_tensor, output_tensor_grad)
if is_last_iteration:
input_tensor = None
pipeline_communicate(operation='send_backward', tensor=input_tensor_grad, device=device, dtype=dtype)
else:
input_tensor = bidirectional_pipeline_communicate(operation='send_bwd_recv_fwd', send_tensor=input_tensor_grad, recv_shapes=tensor_shapes, device=device, dtype=dtype)
for ith_warmup_microbatches in range(num_warmup_microbatches): # Cooldown backward passes
if requires_grad_sync:
is_last_iteration = (ith_warmup_microbatches == num_warmup_microbatches - 1)
model.require_backward_grad_sync = (ith_warmup_microbatches == num_warmup_microbatches - 1)
input_tensor, output_tensor = input_tensors.pop(0), output_tensors.pop(0)
output_tensor_grad = pipeline_communicate(operation='recv_backward', shapes=tensor_shapes, device=device, dtype=dtype)
input_tensor_grad = model.backward(input_tensor, output_tensor, output_tensor_grad)
pipeline_communicate(operation='send_backward', tensor=input_tensor_grad, device=device, dtype=dtype)
return logging_loss
来看看 1F1B 流水线并行调度在实践中的扩展情况,并查看集群上的一些基准测试结果:
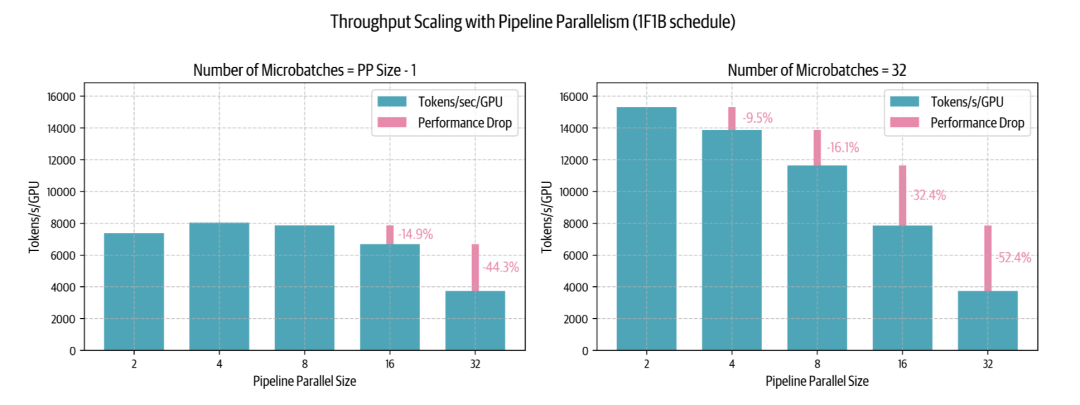
可以观察到:
-
左侧图表中,当Micro Batch数量等于或小于流水线并行度减1( )时,可以看到流水线气泡的负面影响——性能较低,并且随着流水线并行度的增加甚至下降。 -
右侧图表显示,当Micro Batch数量远大于流水线并行度( )时,可以改善低并行度时的性能,但在较大并行度时仍然受到限制。实际上,我们无法无限增加Micro-Batch数量以维持 ,因为最终会受限于global batch size。当流水线并行度增加到最大可用Micro-Batch数时,我们将不得不按照 增大气泡尺寸。
有趣的是,在较少Micro-Batch的情况下,从一个节点( )扩展到两个节点( )时,性能仅下降 14%——这远比张量并行要好,PP在类似的跨节点场景下通常会出现约 43% 的性能下降。这种行为在低带宽跨节点网络环境下,使流水线并行在分布式训练中更具吸引力。
Interleaving Stage 交错阶段
1F1B 调度优化了内存使用,但对于流水线空闲气泡的大小并没有太大改善。有没有更进一步的方法?
事实证明,如果引入一些额外的通信操作,这是可能的。是时候谈谈 交错阶段 Interleaving Stage 了。
到目前为止,按照模型深度对其进行切片,例如,将第 1-4 层放在第一块 GPU 上,将第 5-8 层放在第二块 GPU 上。但其实,可以用不同方式进行切片,例如,将奇数层(1、3、5、7)放在第一块 GPU 上,而偶数层(2、4、6、8)放在第二块 GPU 上。
这本质上形成了一种 “循环流水线 Loop Pipeline”,在前向传播过程中,一个Micro Batch 会在 GPU 之间循环流转。来看一个图示:
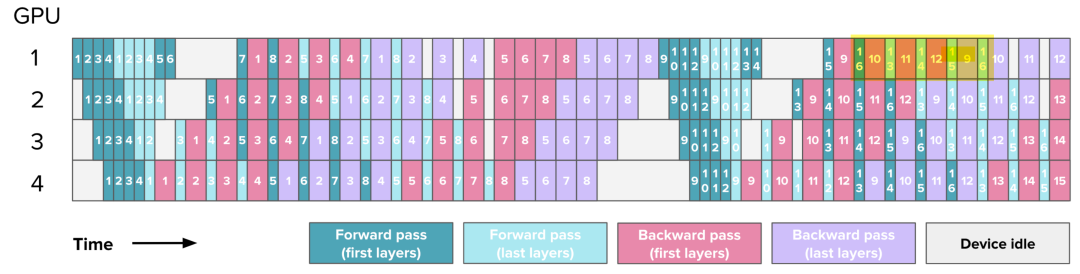
编者注: 深绿色/深红色代表一个模型的前N//2层,浅绿色/浅紫色代表后N//2层。可以看出从1-4卡,前一半和后一半形成交错。在这个例子中=2
随着模型多次通过每个 GPU 进行相同的计算,而之前只需一次遍历,额外的通信发生了。然而,每次正向和反向传播都被除以一个因子 ,其中 是每个 GPU 中的阶段或模型块的数量,因为能够更好地交错正向和反向传播。
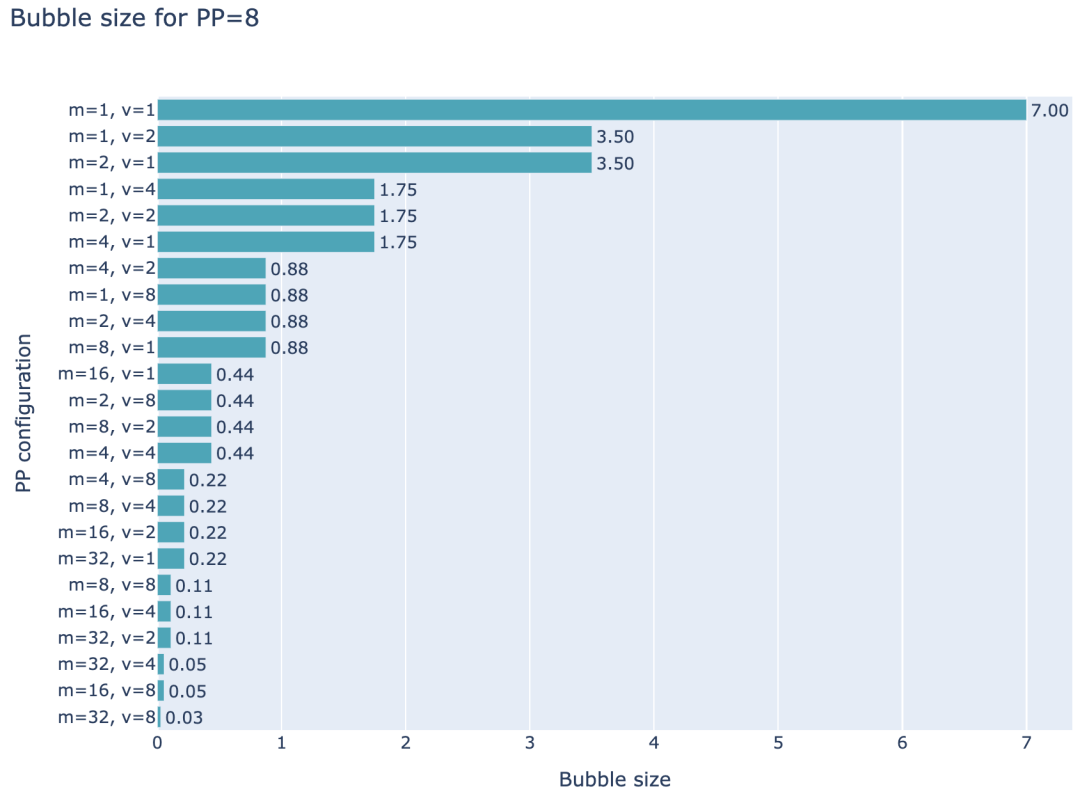
因此,可以通过增加Micro-Batch(microbatches)和交错阶段(interleaved stages)来减少流水线气泡(bubble),但需要注意的是,从数量上来看,通信量也会随之增加 ,这实际上是一个权衡。在下图中,你可以看到针对
p=8 的流水线并行(PP)设置的几种不同配置,其中 m=1,=1 是最基础的流水线并行方式,而 =1 代表 AFAB 或 1F1B 方案,而 ≠1 则是交错配置。
在流水线并行 PP 中,每个 GPU 在某个时刻只能干一件事:要么处理某个Micro-Batch的前向传播(forward pass),要么处理反向传播(backward pass)。因此,需要决定:
-
是优先让 早期的Micro-Batch(比如 micro-batch 1) 尽快通过所有层,完成前向和反向传播(即尽早“出结果”)?
举例:
-
GPU 0 处理 micro-batch 1 的第 1-8 层(前向传播)。 -
GPU 1 马上接手,处理 micro-batch 1 的第 9-16 层。 -
依此类推,直到 micro-batch 1 跑完所有层的前向传播。 -
然后反向传播也按同样顺序从后向前完成。 -
等 micro-batch 1 完全处理完,才开始处理 micro-batch 2。 -
还是优先让 后期的Micro-Batch(比如 micro-batch 2、3、4) 先通过前面的层,把流水线尽量填满?(详细内容见《Breadth-First Pipeline》[3])
举例:
-
GPU 0 先处理 micro-batch 1 的第 1-8 层。 -
GPU 0 紧接着处理 micro-batch 2 的第 1-8 层,而不是等 micro-batch 1 跑到下一阶段。 -
等 GPU 0 处理完多个Micro-Batch后,GPU 1 再依次接手这些Micro-Batch的第 9-16 层。
这两种选择分别对应 深度优先(Depth-First) 和 广度优先(Breadth-First) 的调度策略。
现在,你已经掌握了 Llama 3.1 的流水线并行PP方法的所有关键要素。它采用了一种“一前一后”(1F1B)设置,并结合了交错阶段,同时优先级可调,可在深度优先和广度优先之间调整, 如下图所示:

然而,我们尚未探索所有可能的流水线调度方法,最近,一些新方法已经被提出,可以 将气泡减少到几乎为零 !例如,DeepSeek V3/R1 实现中就使用了这些技术 – DualPipe [4]。是不是很好奇?让在离开流水线并行的世界之前,最后快速看一下这些神奇的调度方法吧!
Zero Bubble & Dual Pipe
最近,一些更复杂的气泡优化方法被提出,并达到了接近“零气泡”的状态。秘诀在于对涉及的操作进行更加精细的拆分,以实现最高效的交错。例如,DeepSeek V3/R1 的流水线实现方法——DualPipe——就几乎达到了零气泡状态。
先简要了解一下 ZeroBubble[5]研究,它是 DualPipe 方法的前身。
ZeroBubble 的核心观察点是:矩阵乘法的反向传播实际上涉及两个独立的操作——输入的反向传播(B)和权重的反向传播(W):
其中,B(输入的反向传播)的输出对于执行浅层的反向传播是必需的,而 W(权重的反向传播)并不是必须立即执行的,它通常只需要在优化器步骤之前完成。如下图所示:

这意味着 W 可以在同一阶段的 B 之后的任何位置灵活调度。这种灵活性使得我们可以巧妙地安排 W,以填补流水线中的气泡。右上角的 ZB-H2 调度就是利用这种精细拆分实现零气泡的示例(理论上的)。

DeepSeekV3中提出的 DualPipe 方法,对这种分解策略进行了扩展,它引入了两个沿流水线并行(PP)维度传播的独立数据流,并通过交错执行来最大限度减少 GPU 的空闲时间。其调度方式如下图所示,比之前的方法更为复杂:

通常,要完全优化如此复杂的调度方式,需要精确测量各个细粒度操作的执行时间,并利用 整数线性规划(ILP)来最小化最终的气泡时间。ZeroBubble 论文[5] 讨论了用于实现此类调度的启发式方法和算法。因此,ZeroBubble 和 DualPipe 调度方式过于复杂,无法在这里提供代码示例,但你应该已经对其中涉及的概念有了大致了解。
Expert Parallel 专家并行
这是我们要讨论的最后一种并行方法。在深入探讨之前,如果你对专家混合(Mixture-of-Experts,MoE)还不熟悉,可以阅读我们之前发布的博客[6],它能帮助你更好地理解 MoE 体系结构。
近年来,专家混合模型受到了越来越多的关注,例如 GPT-4、Mixtral,以及最近的 DeepSeek-V3/R1。这类模型的基本思想是,每一层不是单独使用一个前馈模块(feedforward module),而是可以并行使用多个模块,并通过不同的路径处理 token。
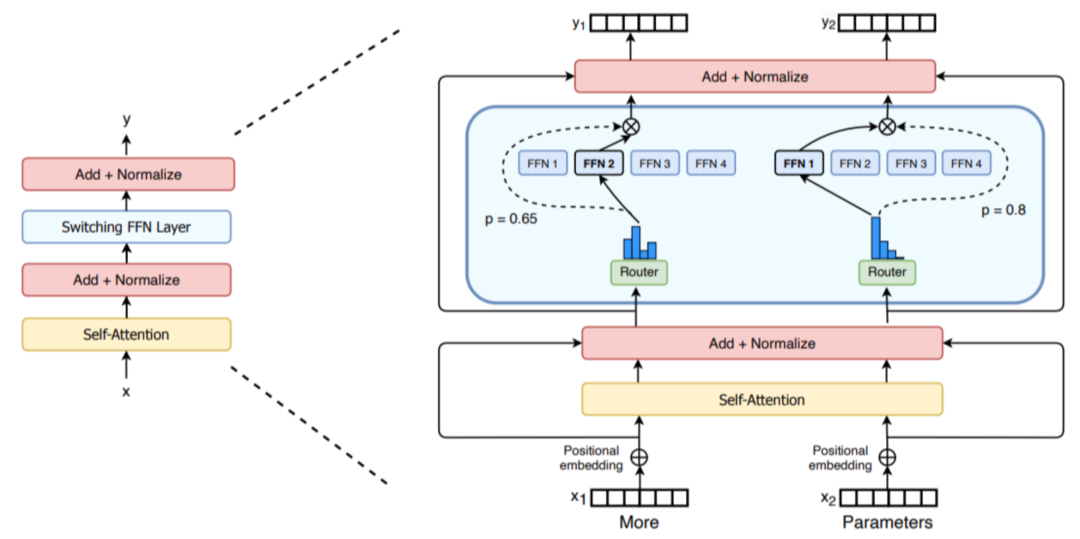
MoE 层的设计使其能够在专家(expert)维度上轻松实现并行计算,称之为 专家并行(Expert Parallelism, EP)。由于前馈层(feedforward layers)完全独立,可以将每个专家的前馈层放置在不同的计算节点上。相比于张量并行(TP),EP 更加轻量级,因为它不需要拆分矩阵乘法,只需要将 token 的隐藏状态正确路由到相应的专家即可。
在实际应用中,EP 通常会与其他并行方式结合使用,例如 数据并行(Data Parallelism, DP)。这是因为 EP 仅影响 MoE 层,并不会像上下文并行(Context Parallelism)那样在序列长度维度上对 token 进行分片。如果仅使用 EP,GPU 仍然会对所有非 MoE 模块执行冗余计算。通过将 EP 与 DP 结合,可以有效地在 GPU 之间分片专家模块和输入Batch,如下图所示:
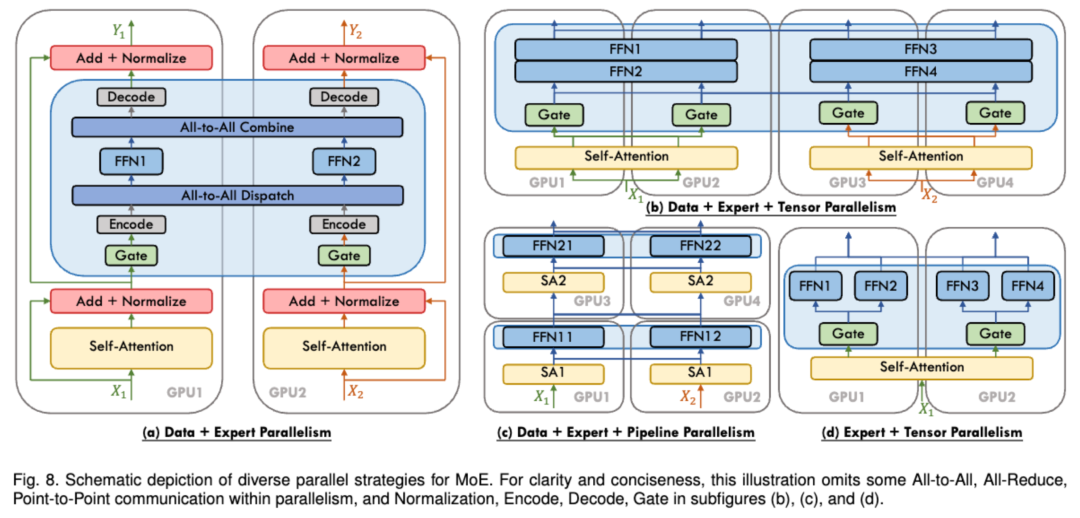
在实践中,有一些技巧可以提高 EP 的效率,这些技巧与模型设计密切相关。例如,DeepSeek-V3 在 router 中施加了一个约束,确保每个 token 最多被发送到 M 个计算节点(在其设计中为 4 个),从而尽可能让 token 保持在单个节点上,并减少通信开销。虽然专家并行已经存在了一段时间, 它现在正随着 MoE 架构的吸引力增强而获得新的动力。
编者注:DeepSeek-V3模型采用混合并行(Hybrid Parallelism)策略,结合了16PP+8TP+Zero-1 DP+64EP, 在8个节点上计算。DualPipe允许同时计算两个连续的流水线阶段。通过重叠这些阶段的计算,可以减少流水线中的空闲时间(bubble),从而提升整体吞吐量
5D Parallelism 5D并行
恭喜你!你已经了解了用于扩展模型训练的五种并行策略:
-
数据并行(DP)——按Batch维度并行 -
张量并行(TP)——按隐藏维度并行 -
序列并行 & 上下文并行(SP/CP)——按序列维度并行 -
流水线并行(PP)——按模型层并行 -
专家并行(EP)——按模型专家并行
此外,还有三种 ZeRO 策略可以与数据并行结合,以减少内存占用:
-
ZeRO-1 —— 在 DP 复制之间分片优化器状态 -
ZeRO-2 —— 在 DP 复制之间分片优化器状态和梯度 -
ZeRO-3 —— 在 DP 复制之间分片优化器状态、梯度和模型参数
到目前为止,你可能会好奇这些并行和 ZeRO 策略如何相互比较和交互。换句话说,我们应该选择哪些策略进行组合,而哪些应该避免混用?
接下来,我们将分析它们之间的相似性和相互作用。首先,我们将比较流水线并行(PP)和 ZeRO-3,它们在某些方面非常相似,但也存在重要的区别。
(1) 流水线并行 vs. ZeRO-3 —— PP 和 ZeRO-3 都是通过将模型权重分布在多个 GPU 上,并在模型深度轴上进行计算和通信(例如,在 ZeRO-3 中,我们在计算时预取下一层数据)。在这两种方法中,每个设备都需要完整地计算层操作,而不像 TP 或 EP 那样在子层级别进行计算。
|
|
ZeRO-3 | 流水线并行(PP) |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
正如上表所示,ZeRO-3 和 PP 解决了相同的挑战,但采用了不同的方法,选择哪种方式取决于你是更关注权重的通信,还是激活的通信。虽然它们可以结合使用,但在实践中不常见,因为这样做需要显著增加global batch size 以摊销通信成本,从而在global batch size、模型大小、网络带宽和训练效率之间形成权衡。如果你决定结合使用它们,ZeRO-3 应该被配置为在一系列 PP Micro Batch 期间将权重保留在内存中,以尽可能减少不必要的通信开销。
另一方面,ZeRO-1 和 ZeRO-2 关注优化器状态和梯度,它们可以轻松与流水线并行(Pipeline Parallelism)结合,并且是互补的。结合使用它们不会带来额外的新挑战。例如,DeepSeek-v3 的训练使用了 PP 结合 ZeRO-1。
(2) 张量并行(Tensor Parallelism)与序列并行(Sequence Parallelism)是天然互补的,并且可以与流水线并行 PP 和 ZeRO-3 结合使用,因为它依赖矩阵乘法的分布性质,使得权重和激活可以被分片并独立计算后再合并。
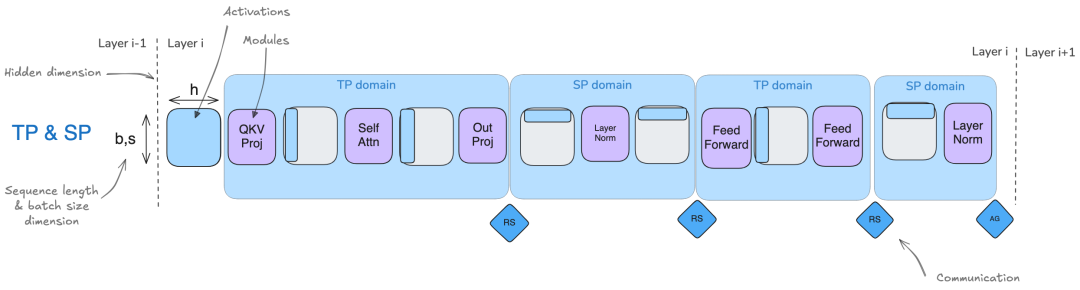
我们不希望仅使用 TP 进行并行计算的主要原因是,在实践中,TP 有两个限制,在前面部分已经讨论过:
-
首先,由于其通信操作是计算的关键路径之一,在扩展到一定规模后,通信开销开始占据主导地位,使得扩展变得困难。 -
其次,与 ZeRO 和 PP 这类与模型无关的方法不同,TP 需要仔细处理激活分片——有时沿隐藏维度(TP 区域),有时沿序列维度(SP 区域)——这使得其正确实现变得更加复杂,并且需要特定的模型知识来确保整个过程中分片模式的正确性。
因此,在结合并行策略时,TP 通常用于高速的节点内通信,而 ZeRO-3 或 PP 则用于跨节点的低速通信,因为它们的通信模式对带宽需求较低(PP),或者更容易与计算重叠(ZeRO-3)。
结合这些技术时,主要的考虑因素是如何高效地组织 GPU,使其在每个并行维度的分组中最大化吞吐量并最小化通信开销,同时注意 TP 的扩展限制。例如,TP 的通信 GPU 组应保持在同一个节点内部
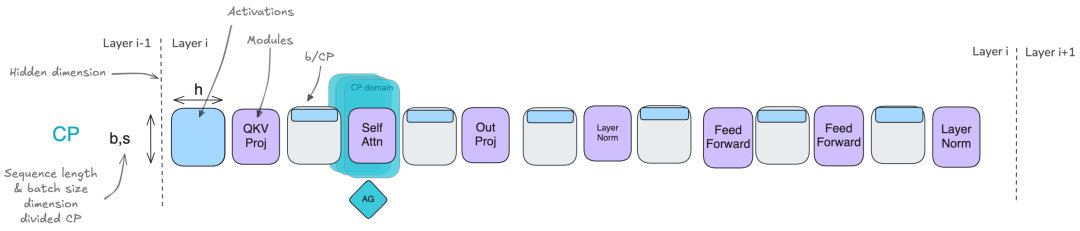
(3)上下文并行(Context Parallelism) 和 专家并行(Expert Parallelism) 也可以帮助分片激活,并且可以视为 TP 的补充。前者处理长序列,而后者用于分布式 MoE 训练,它们可以无缝结合使用。
上下文并行(CP) 主要用于解决超长序列训练的挑战,它通过在 GPU 之间沿序列维度分片激活来实现。大多数操作(如 MLP 和 LayerNorm)可以独立处理这些分片的序列,而注意力层需要通信,因为每个 token 需要访问整个序列的 key/value。通过环形注意力模式(ring attention patterns)高效地处理,实现了计算和通信的重叠。当扩展到极端长的序列(128k+ tokens)时,即使使用完整的激活重计算,单个 GPU 也无法满足注意力计算的内存需求,此时 CP 就尤为重要。
(4) 专家并行(EP) 主要用于训练 MoE(Mixture of Experts)模型,它通过在 GPU 之间分片专门的“专家”(experts),并在计算过程中动态地将 token 路由到相关的专家。EP 中的关键通信操作是 all-to-all 操作,它负责将 token 发送到相应的专家,并收集返回的计算结果。虽然这种操作引入了一定的通信开销,但它使得模型容量可以大规模扩展,因为每个 token 在推理(或训练)期间仅由一小部分参数处理。对于大规模专家模型,将专家在 GPU 之间分片变得尤为重要。

备注:
EP 在输入处理方面与数据并行(DP)有相似之处,因此某些实现将专家并行视为数据并行的一个子类别,主要区别在于 EP 使用专门的专家路由,而不是让所有 GPU 处理相同的模型副本。
范围与重点 我们快速总结一下不同的并行策略在模型的哪些部分影响最大:
-
张量并行TP和序列并行SP影响整个模型的计算,它们分片权重和激活。 -
上下文并行CP主要影响注意力层,因为这里需要跨序列通信,而其他层可以独立处理分片的序列。 -
专家并行EP主要影响 MoE 层(替代标准的 MLP 块),不会影响注意力和其他组件。 -
流水线并行PP和 ZeRO 并不特别针对某个子模块或组件,但在流水线并行中,模块和层需要均衡分布,第一层和最后一层通常需要特殊处理,因为它们涉及额外的嵌入层。
| 张量 + 序列并行 | 上下文并行 | 专家并行 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
总结一切—— 现在,让我们尝试将我们在一个单一图表中看到的所有技术聚合和组合起来。
在这个总结图表中,您将找到单个transformers层的激活和模块的插图,以其MoE变体形式展示。我们还展示了各种并行性的方向以及我们在所有前文讨论中讨论过的通信操作。

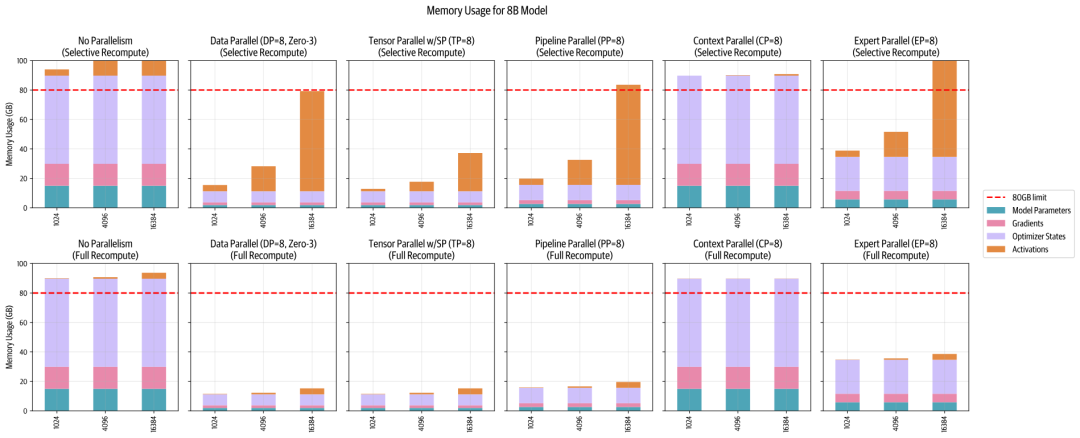
我们还可以并排表示这些策略的全面概述。我们将它们与不同的序列长度以及(顶部) Selective 和(底部) Full Recomputation 一起绘制,以便您了解它们如何与激活交互:
让我们以一个高层次的视角结束本节,看看所有这些技术,它们的主要基本思想和主要瓶颈:
| 方法 | 特定应用的内存节省 | 并行/分片维度 | 缺点 |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
显然,这些技术都不是解决所有问题的灵丹妙药,我们经常需要以某种方式组合它们。我们是否可以制定一些规则,帮助我们找到选择和组合它们的良好起点?这将是我们下一节的主题。
Reference:
[1] https://huggingface.co/spaces/nanotron/ultrascale-playbook
[2] https://huggingface.co/spaces/Ki-Seki/ultrascale-playbook-zh-cn
[3] Breadth-First Pipeline Parallelism
[4] DeepSeek-V3 Technical Report https://arxiv.org/pdf/2412.19437
[5] Zero Bubble Pipeline Parallelism https://arxiv.org/pdf/2401.10241
[6] https://huggingface.co/blog/zh/moe

(文:GiantPandaCV)