
刚刚Anthropic公司正式发布了他们最新的AI王牌组合—— Claude 3.7 Sonnet 和 Claude Code!各种能力超群,只是数学能力还是不及DeepSeek等,感觉Claude所有重点都在代码能力
第一时间(熬夜🤣)给大家划个重点
Claude 3.7 Sonnet:混合推理架构登场,打造前所未有的智能巅峰!
Anthropic毫不掩饰对Claude 3.7 Sonnet的自信,直接称其为 “迄今为止最智能的模型”,更重要的是,它还开创性地成为了 “市场上首个混合推理模型”!
与以往模型不同,Claude 3.7 Sonnet 的独特之处在于其 “混合” 能力:
-
• 极速响应与深度思考并存: 它既能像猎豹一样 “即时响应”,满足对速度有极致要求的场景;又能进行 “扩展的、逐步思考”,处理需要复杂推理的任务。深度思考的过程不再是黑箱操作,而是 “对用户可见的”! -
-
• 思考时长由你掌控: 对于API开发者而言,Anthropic 开放了 “思考预算 (budget for thinking)” 的精细控制权。你可以根据任务的复杂程度和对结果质量的要求,设定模型思考的tokens上限 (最高可达 128K tokens 输出限制)。 这意味着开发者可以根据实际需求,在 速度、成本和答案质量 之间自由调优,实现真正的 “按需定制”!👍 这种灵活性是前所未有的,也体现了Anthropic对开发者需求的深刻理解 -
-
• 标准模式与扩展思考模式: Claude 3.7 Sonnet 在 标准模式 下,是 Claude 3.5 Sonnet 的升级版,性能已经非常出色。 而在 扩展思考模式 下,它会进行 “自我反思 (self-reflects)” 后再给出答案,这使得它在 数学、物理、指令跟随、编码 等多个领域的性能都得到显著提升。更棒的是,无论在哪种模式下,prompt的编写方式都基本一致,降低了用户的学习成本
💪 代码能力史诗级跃升!Claude Code横空出世,赋能智能体编码新范式!
如果你是一名开发者,尤其是专注于 编程和前端Web开发,那么Claude 3.7 Sonnet 和 Claude Code 的组合绝对会不失所望! Anthropic 明确指出,新模型在 “编码和前端Web开发” 领域取得了 “特别强劲的改进”
更重要的是“Claude Code” —— 一个跨时代的 “智能体编码命令行工具”! 这不仅是 Claude 系列的首款代码工具,更预示着AI辅助编程进入了一个全新的阶段。 目前 Claude Code 以 “限量研究预览版” 的形式推出
Claude Code 的强大之处在于,它将 AI 的代码智能直接融入开发者的工作流中,让你能够在熟悉的 终端环境 下,“直接委托实质性的工程任务给 Claude”。 想象一下,你只需在命令行输入指令,就能让 AI 智能体完成代码搜索、文件编辑、测试编写和运行、代码提交和推送等一系列复杂的编程任务
Claude Code 的核心能力包括:
-
• 代码检索与阅读: 快速搜索和理解代码库,不再需要在海量代码中手动翻找 -
• 文件编辑: 智能修改代码文件,无论是简单的bug修复还是复杂的重构,都能轻松应对 -
• 测试编写与运行: 自动生成和执行测试用例,确保代码质量,提升软件可靠性 -
• 代码提交与推送 (GitHub 集成): 无缝集成 GitHub,方便代码的版本控制和协作 -
• 命令行工具集成: 灵活使用各种命令行工具,扩展功能,满足更复杂的需求。
Anthropic 强调,Claude Code 在 测试驱动开发、复杂问题调试和大规模重构 等场景中尤其得心应手。 在早期测试中,Claude Code 能够在 “单次操作中完成通常需要 45 分钟以上的手动工作”,显著缩短开发时间和成本
Claude Code 目前处于研究预览的 beta 阶段:
https://docs.anthropic.com/en/docs/agents-and-tools/claude-code/overview
📊 权威评测数据震撼发布:实力碾压,问鼎多项榜单!
性能是检验 AI 模型实力的硬指标。Anthropic 在公告中展示了 Claude 3.7 Sonnet 在多个权威基准测试上的卓越表现,用数据说话,实力尽显:
-
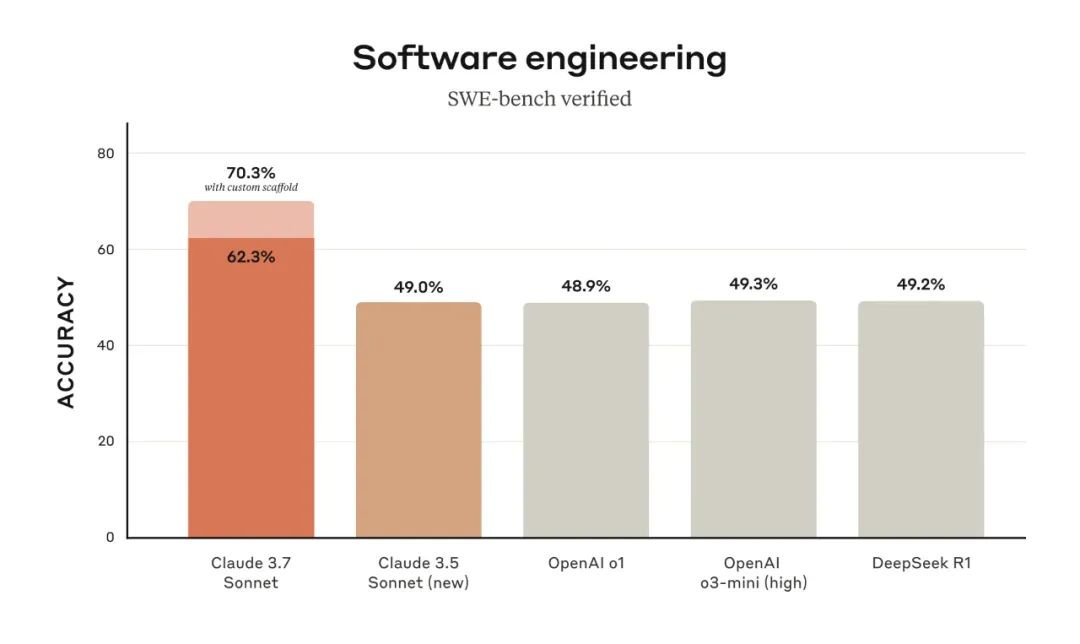
• SWE-bench Verified (软件工程基准测试): Claude 3.7 Sonnet 以 70.3% (使用定制 scaffold) 和 62.3% (标准 scaffold) 的惊人成绩,再次成为该榜单的王者,远超 OpenAI 的 GPT-4 和 DeepSeek R1 等强劲对手。 SWE-bench Verified 专注于评估 AI 模型解决真实世界软件问题的能力,Claude 3.7 Sonnet 的优异表现充分证明了其在实际编码场景中的强大实力。值得注意的是,70.3% 的高分使用了 “定制 scaffold”,并在问题子集上进行了内部评分,而 62.3% 的分数则使用了 bash/editor 工具和一个 “思考工具”,在 500 个问题上进行了单次尝试,没有额外的测试时计算
-
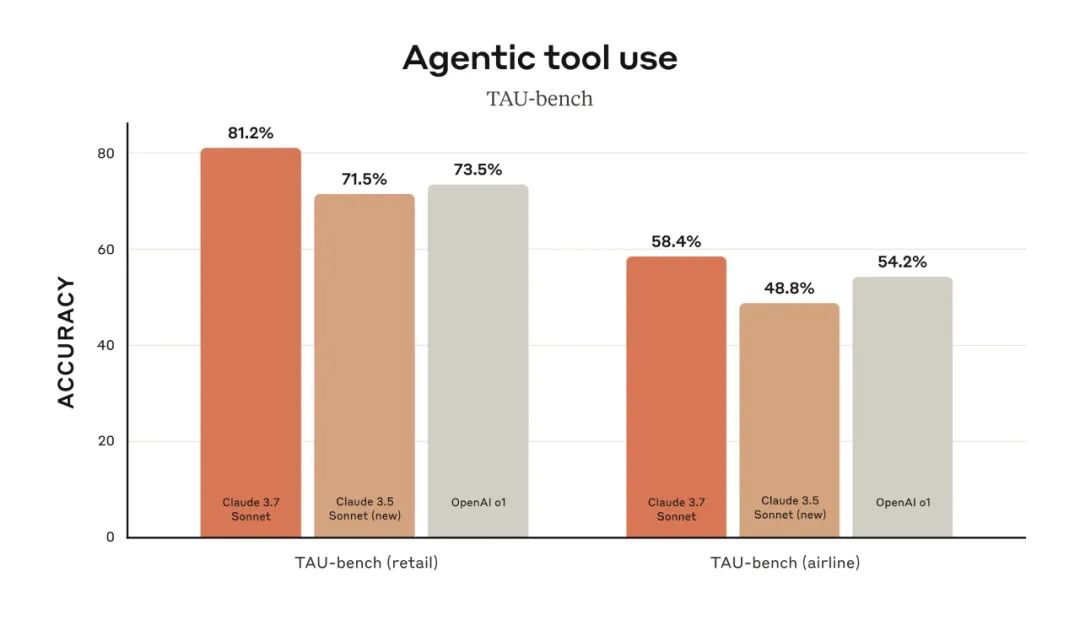
• TAU-bench (智能体工具使用基准测试): Claude 3.7 Sonnet 在 TAU-bench 的 零售 (retail) 和 航空 (airline) 两个场景中,分别取得了 81.2% 和 58.4% 的领先成绩。 TAU-bench 考察的是 AI 智能体在复杂的真实世界任务中,与用户和各种工具进行有效交互的能力。Claude 3.7 Sonnet 在此项测试中再次拔得头筹,印证了其作为智能体工具的卓越性能。为了获得这些分数,Anthropic 使用了 prompt addendum 指导 Claude 更好地利用 “planning” tool,鼓励模型写下思考过程 -
通用benchmark测试
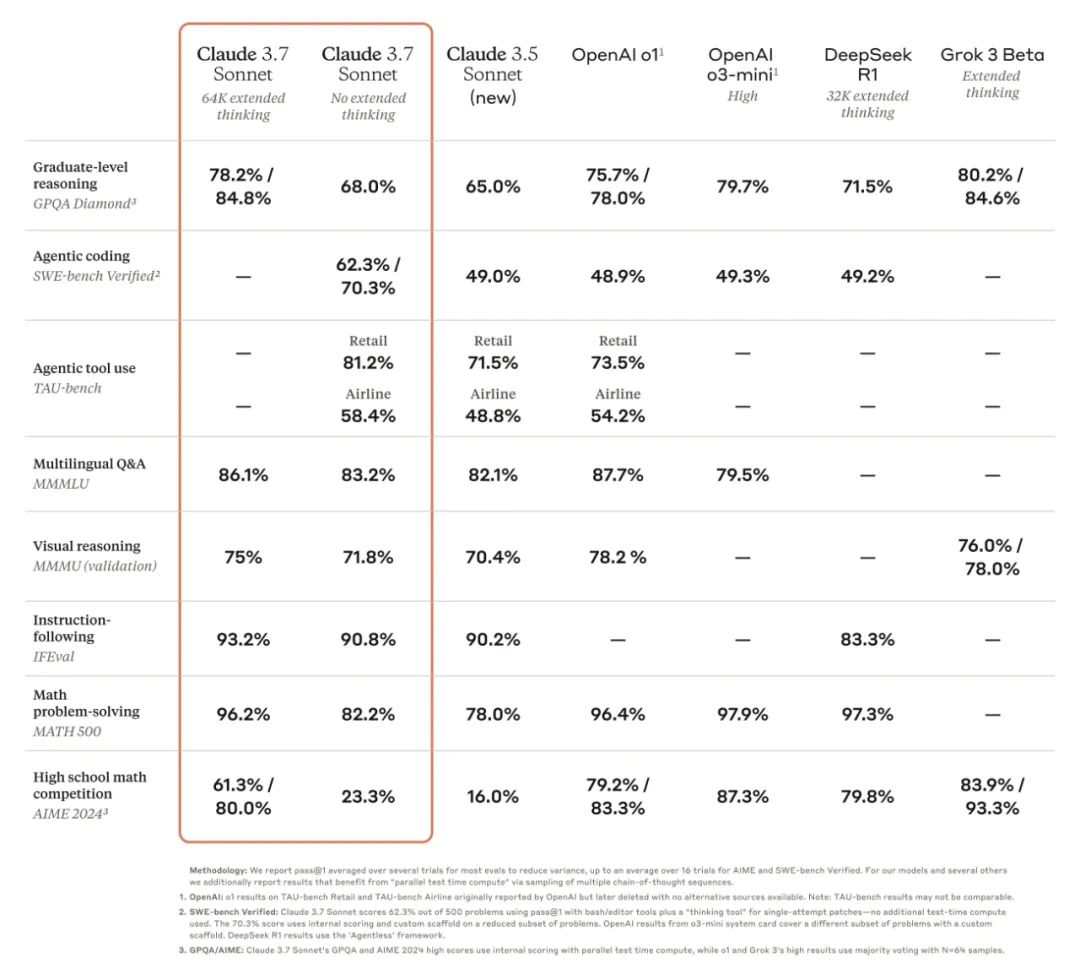
总而言之,Claude 3.7 Sonnet 在 指令跟随、通用推理、多模态能力和智能体编码 等多个关键领域都展现出了卓越的性能,在 数学和科学 方面,扩展思考模式带来了显著的提升但是没有超越deepseek等模型。 在 Anthropic 内部的 Pokémon gameplay tests (宝可梦游戏测试) 中,Claude 3.7 Sonnet 也超越了以往的所有模型
写在最后:
按照Anthropic的说法:Claude 3.7 Sonnet 和 Claude Code 的发布,是在 “构建真正增强人类能力的 AI 系统” 道路上迈出的重要一步。 Anthropic 坚信,凭借其强大的 “深度推理、自主工作和有效协作” 能力,AI 将把我们带向一个更加美好的未来,在那里,AI 将 “丰富和扩展人类所能成就的一切”
Anthropic 也在公告中展望了 Claude 的发展蓝图,描绘了 Claude 从 “助手 (assists)” 到 “合作者 (collaborates)” 再到 “先锋 (pioneers)” 的进化路径,预示着 AI 在未来将扮演越来越重要的角色,最终将能够 “找到突破性的解决方案,解决需要团队数年才能完成的挑战性问题”。

参考:
https://www.anthropic.com/news/claude-3-7-sonnet
⭐
(文:AI寒武纪)