


©PaperWeekly 原创 · 作者 | 韩申
单位 | 浙江大学

论文题目:
Uncertainty-Aware Graph Structure Learning
https://arxiv.org/abs/2502.12618

图神经网络(GNN)在处理图结构数据上具有卓越的效果。随着模型架构的不断演变,GNN 的性能也在不断提升。然而这些基于模型架构的方法忽视了图结构自身存在的缺陷。例如,图结构常常会出现错误边和缺失边等数据问题,从而限制模型的效果。
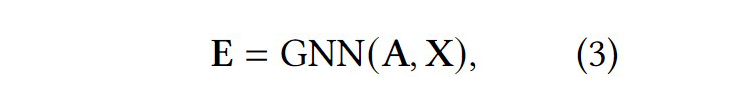

1. 建立连接时只依赖嵌入相似度而忽略了结点的信息质量。
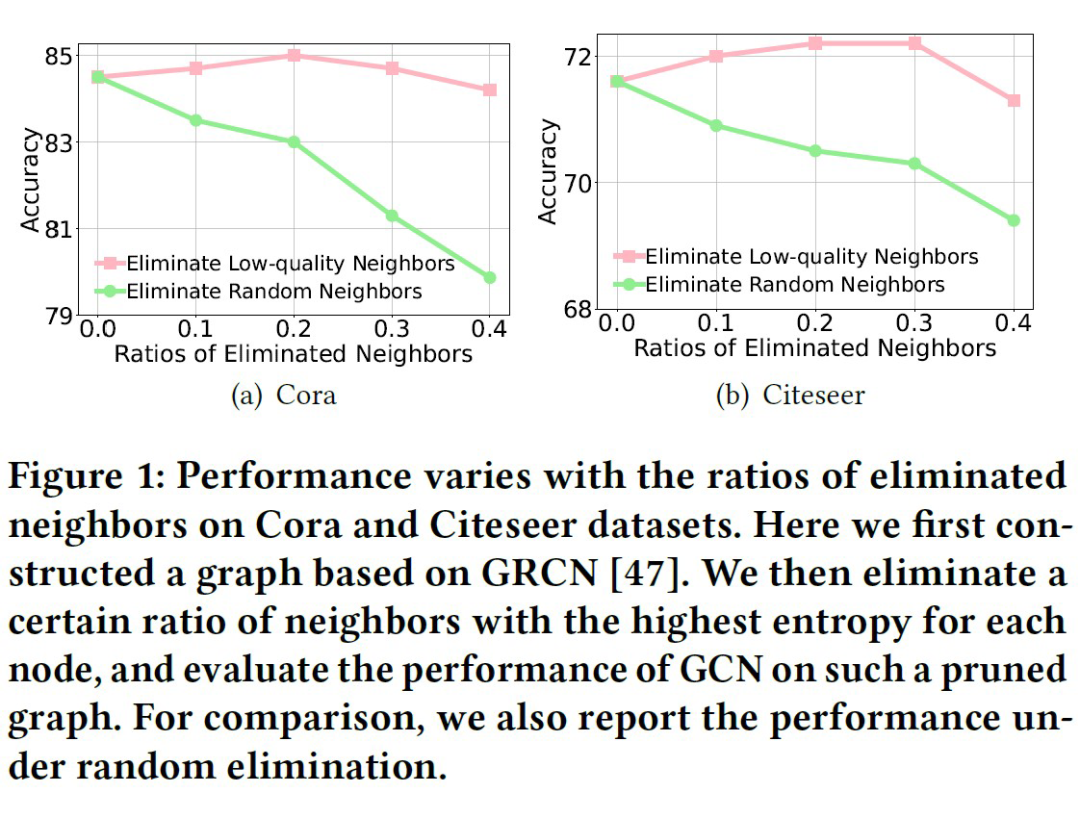

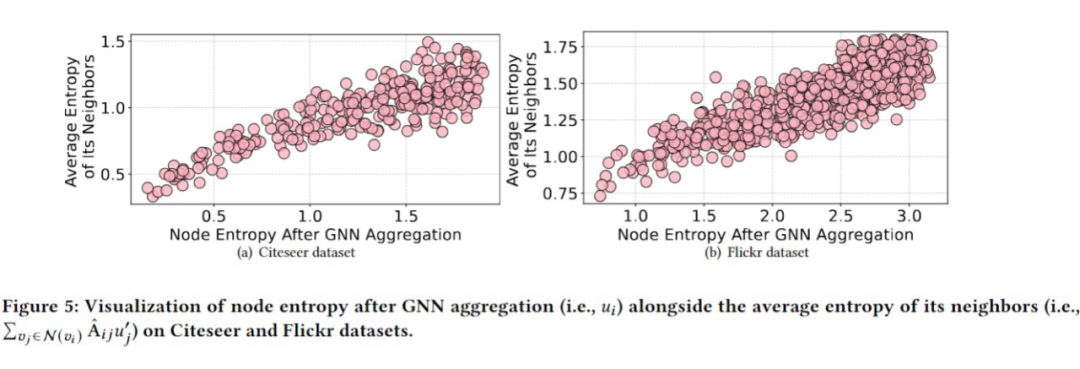
在本文中,我们使用不确定性(信息熵)来衡量结点的信息质量。我们首先通过实验论证:聚合高熵邻居的信息会导致目标结点的熵增大。具体来说,我们在给定的数据集上训练单层 GCN 和线性分类器,并可视化了目标结点的信息熵以及邻居在聚合前的平均熵。
如图所示,我们观察到:结点的信息熵与邻居聚合之前的平均熵存在强正相关。这一发现表明:盲目地连接和聚合来自高熵结点的信息可能会污染目标结点自身的嵌入向量。因此,我们需要在图结构学习中考虑结点的不确定性,以学习合理的非对称结构。
我们提出 UnGSL(Uncertainty-aware Graph Structure Learning),一种可以无缝整合至现有 GSL 模型的轻量级插件。该方法利用可学习的结点阈值来自适应区分低熵邻居和高熵邻居,并根据它们的熵等级调整边权重。这种方法不仅提高了图结构的灵活性,还能有效过滤掉低质量的结点信息。
如何使用 UnGSL 呢?首先,预训练给定的 GSL 模型来获得分类器,并计算结点的熵,将其转化为 0 到 1 之间的置信度分数。

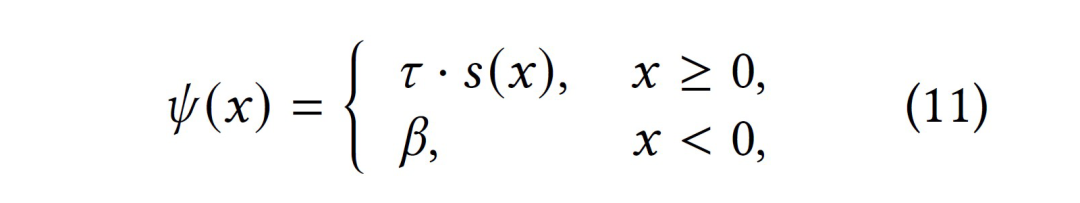
即插即用:UnGSL 利用结点的不确定性来优化学习到的邻接矩阵 。本质上,UnGSL 只是将邻接矩阵的计算从公式(4)替换为公式(10)。因此,UnGSL 可以无缝整合到现有的 GSL 方法中,进一步提升它们的图学习能力。
轻量级:UnGSL 仅包含 n 个可学习参数,只优化给定图的现有边,而不生成新的边。UnGSL 引入的额外运算的复杂度为*O(n+m)*,其中 n 和 m 分别表示图中的结点和边的数量。因此,UnGSL 对原 GSL 模型施加的计算成本较小,使得 UnGSL 可以高效率的提升模型性能。
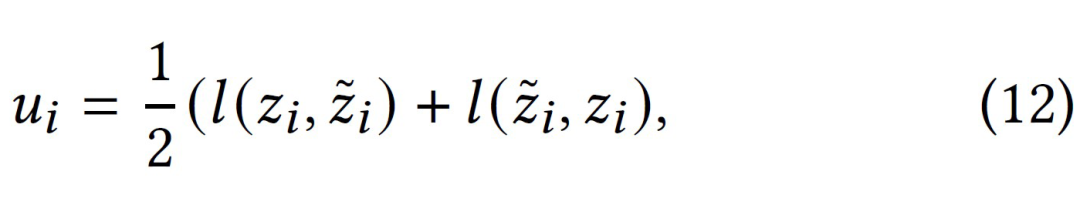
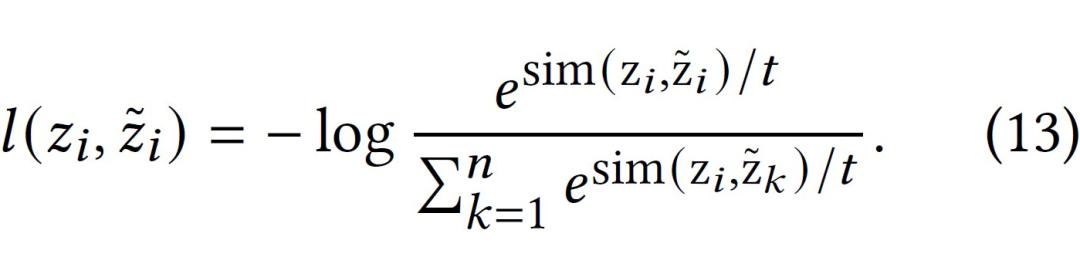

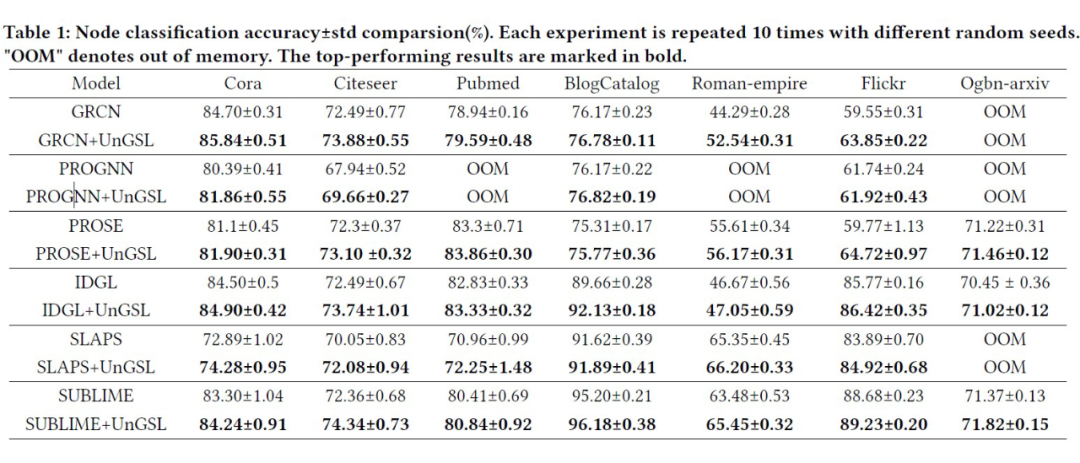
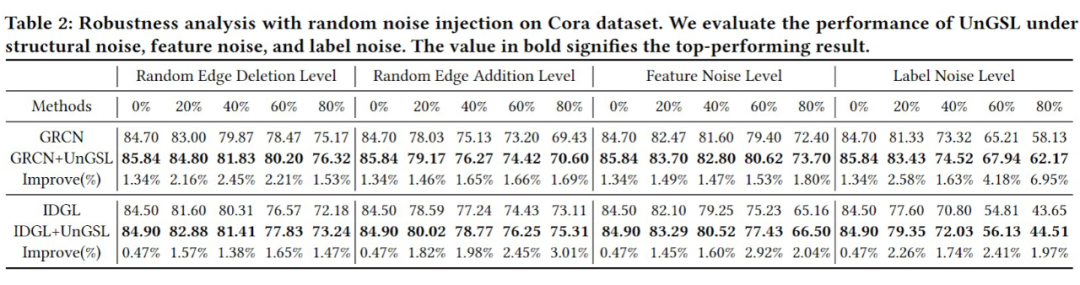
为了综合评估 UnGSL 在精度、鲁棒性、效率方面的性能,我们将 UnGSL 策略运用在 6 个先进的 GSL 模型,并在 7 个数据集上进行实验验证,结果如下:
-
准确性(Table 1):UnGSL 全面优于基础 GSL 模型,平均精度提升为 2.07%。尤其在 GRCN 模型上的提升达到了 5.12%。 -
鲁棒性(Table 2):分别引入结构化噪声、特征噪声和标签噪声进行测试,UnGSL 可以持续的提升 GSL 模型的精度。且随着噪声强度的增加,UnGSL 可以实现更大的相对提升,证明了 UnGSL 对于不同噪声的鲁棒性。 -
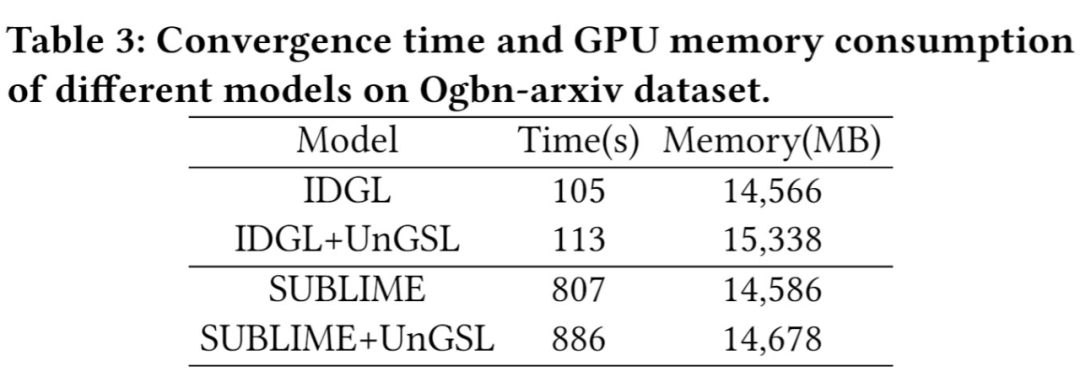
效率(Table3):对比原 GSL 模型和 UnGSL + GSL 模型在大尺寸数据集 OGBN-Arxiv 上的效率,UnGSL 仅增加了 8.71% 的收敛时间和 2.97% 的 GPU 空间。

(文:PaperWeekly)