

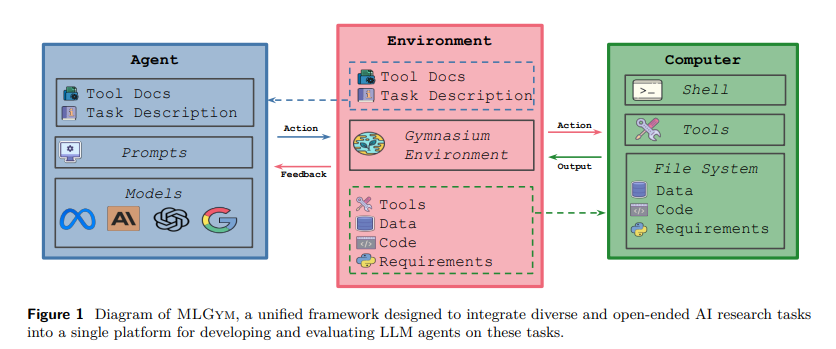
论文概述:本文创新性地提出了 MLGym 框架和 MLGym-Bench 基准,首次为 AI 研究Agent构建了 Gym 环境和多样化开放式任务基准,并通过对前沿 LLM 的评估揭示了当前模型在改进基线任务上表现出色,但在产生新颖科学贡献方面仍存在局限性的反直觉结果,强调了构建完善评估体系和探索强化学习等方法对于提升 AI 研究Agent自主性的重要意义。
参考文献:
[1] MLGym: A New Framework and Benchmark for Advancing AI Research Agents:https://arxiv.org/abs/2502.14499
(文:NLP工程化)