
DeepSeek 开源周继续上演!

DeepSeek 开源周已经进行到第三天,这个「小而美」的团队正用实际行动证明:开源的力量不容小觑!
开源周背景
DeepSeek团队在开源周的第0天称:未来一周将开源5个仓库。这些都是他们在线服务中的核心组件,已经过文档化、部署和生产环境的实战检验。

他们的理念很简单:每一行共享的代码都将成为集体前进的动力,加速我们探索AGI的旅程。
这不是什么高高在上的象牙塔,而是纯粹的车库能量和社区驱动的创新!
简要回顾
Day 1:FlashMLA
第一天,DeepSeek开源了FlashMLA——一个为Hopper GPU优化的高效MLA解码内核,专为可变长度序列设计,已在生产环境中使用。

这个项目有哪些亮点?
-
✅ 支持BF16
-
✅ 分页KV缓存(块大小64)
-
⚡ 在H800上实现了3000 GB/s的内存带宽和580 TFLOPS的计算能力
Day 2:DeepEP
第二天的主角是DeepEP——首个开源的EP通信库,专为MoE模型训练和推理设计。

它的实力如何?
-
✅ 高效优化的全对全通信
-
✅ 同时支持节点内和节点间通信(NVLink和RDMA)
-
✅ 为训练和推理预填充提供高吞吐量内核
-
✅ 为推理解码提供低延迟内核
-
✅ 原生支持FP8调度
-
✅ 灵活的GPU资源控制,实现计算-通信重叠
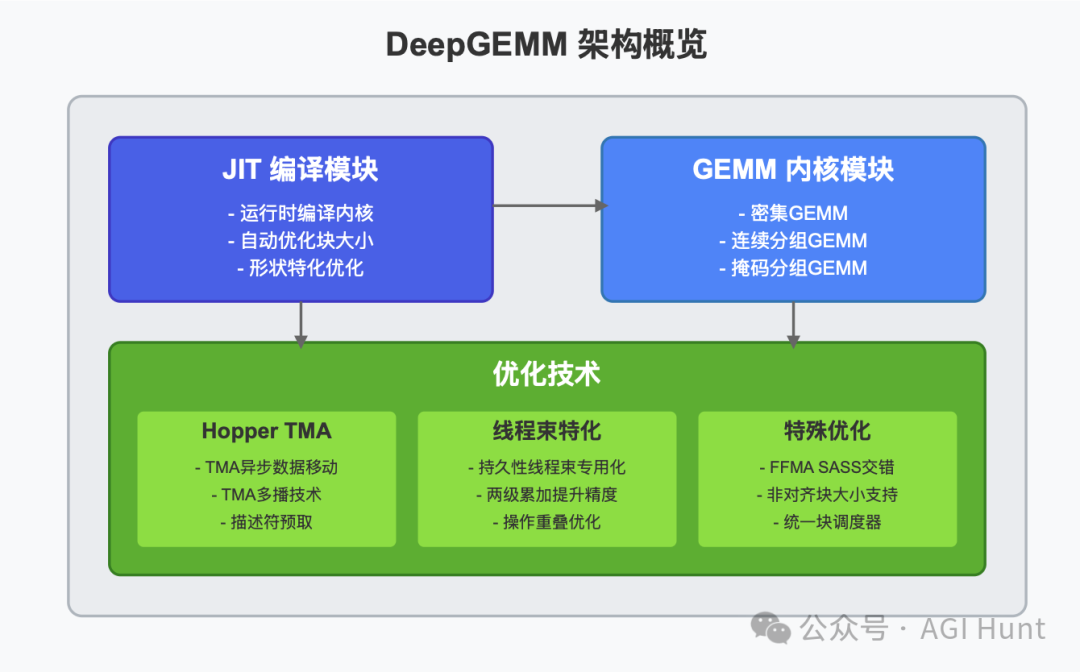
Day 3:DeepGEMM来了!
今天,DeepSeek团队发布了DeepGEMM——一个专为FP8通用矩阵乘法(GEMMs)设计的干净高效库,支持细粒度缩放。

这是什么意思?
简单来说,DeepGEMM可以让你的矩阵运算又快又准!

DeepGEMM的特点
DeepGEMM最大的特点就是简洁高效:
-
支持普通和混合专家(MoE)分组GEMM
-
使用CUDA编写,无需编译即可安装
-
在运行时使用轻量级即时(JIT)模块编译所有内核
-
专为NVIDIA Hopper张量核心设计
-
使用CUDA核心两级累加解决FP8张量核心累加不精确的问题
最令人惊叹的是,虽然借鉴了CUTLASS和CuTe的一些概念,但DeepGEMM避免了过度依赖它们的模板或代数。
而且!
整个库的核心内核函数只有约300行代码!
这让它成为学习Hopper FP8矩阵乘法和优化技术的绝佳资源。
设计轻量,性能却不含糊!
DeepGEMM在各种矩阵形状上的性能与专家调优库相当甚至更好。
性能表现
DeepGEMM在H800上使用NVCC 12.8测试了DeepSeek-V3/R1推理中可能使用的所有形状(包括预填充和解码,但不包括张量并行)。所有加速指标都是与基于CUTLASS 3.6的内部优化实现相比计算得出的。
普通GEMM(非分组)性能
来看数据:
|
|
|
|
|
|
|
|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
最高可达2.7倍的加速!
老黄又一次哭晕在厕所……

分组GEMM(连续布局)性能
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
技术亮点
DeepGEMM采用了多种优化技术,其中有些是CUTLASS中没有的:
-
持久性线程束专用化
-
实现数据移动、张量核心MMA指令和CUDA核心提升的重叠 -
Hopper TMA特性
-
使用张量内存加速器(TMA)进行更快速、异步的数据移动
-
TMA加载LHS、LHS缩放因子和RHS矩阵
-
TMA存储输出矩阵
-
TMA多播(仅限于LHS矩阵)
-
TMA描述符预取
-
通用细节优化
-
使用
stmatrixPTX指令 -
针对不同线程束组的寄存器计数控制
-
尽可能重叠操作,例如重叠TMA存储和非TMA RHS缩放因子加载
-
统一优化的块调度器
-
一个调度器适用于所有非分组和分组内核
-
使用栅格化提高L2缓存重用
-
完全JIT设计
-
所有内核在运行时使用轻量级JIT实现编译
-
GEMM形状、块大小和流水线阶段数被视为编译时常量
-
自动选择块大小、线程束组数量、最佳流水线阶段和TMA集群大小
-
完全展开MMA流水线,为编译器提供更多优化机会
-
非对齐块大小
-
支持如112这样的非对齐块大小,使更多的SM能够工作 -
FFMA SASS交错
-
修改编译二进制文件中的
FFMA指令 -
翻转
yield位和reuse位 -
通过创造更多机会来重叠MMA指令和提升
FFMA指令,提高性能

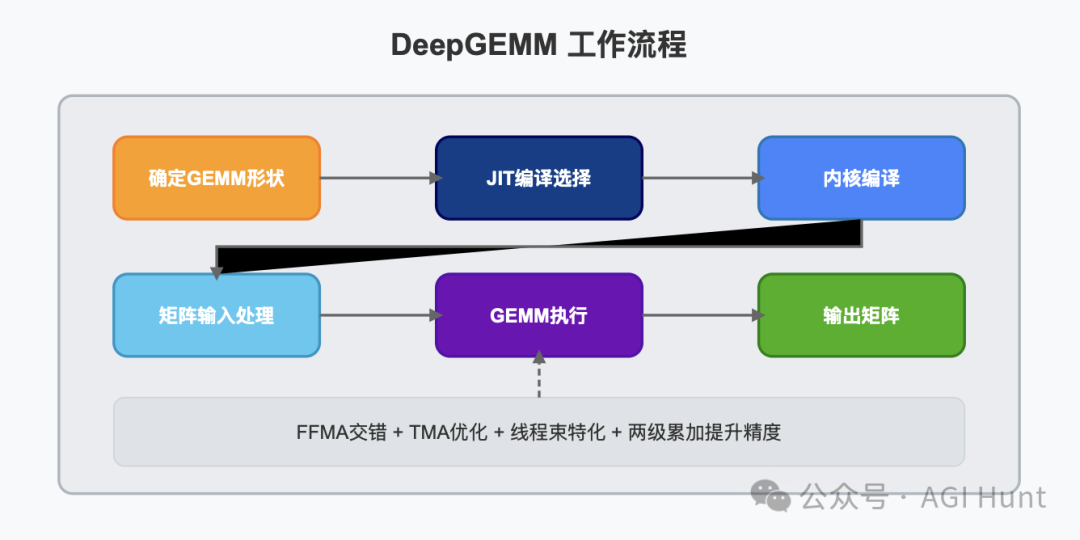
使用方法
安装要求
-
Hopper架构GPU,必须支持
sm_90a -
Python 3.8或更高版本
-
CUDA 12.3或更高版本(强烈推荐12.8或更高版本以获得最佳性能)
-
PyTorch 2.1或更高版本
-
CUTLASS 3.6或更高版本(可通过Git子模块克隆)
安装命令
python setup.py install然后在你的Python项目中导入deep_gemm,就可以使用了!
接口说明
DeepGEMM提供了几种不同类型的GEMM操作:
-
普通密集GEMM(非分组)
-
使用 deep_gemm.gemm_fp8_fp8_bf16_nt函数 -
分组GEMM(连续布局)
-
与传统CUTLASS中的分组GEMM不同,DeepGEMM仅对M轴进行分组,而N和K必须保持固定
-
使用
m_grouped_gemm_fp8_fp8_bf16_nt_contiguous函数 -
分组GEMM(掩码布局)
-
在启用CUDA图的推理解码阶段使用
-
使用
m_grouped_gemm_fp8_fp8_bf16_nt_masked函数
库还提供了一些实用功能:
-
deep_gemm.set_num_sms:设置要使用的最大SM数 -
deep_gemm.get_num_sms:获取当前的SM最大数量 -
deep_gemm.get_m_alignment_for_contiguous_layout:获取分组连续布局的组级对齐要求 -
deep_gemm.get_tma_aligned_size:获取所需的TMA对齐大小 -
deep_gemm.get_col_major_tma_aligned_tensor:获取列主TMA对齐张量
DeepGEMM 的重要性
在极其吃算力的AI 大模型时代,高效的矩阵运算是性能的关键。
DeepGEMM通过优化FP8 GEMM操作,可以显著提高模型的训练和推理速度,同时保持高精度。
特别是对于像DeepSeek-V3这样的大型模型,DeepGEMM可以提供最高2.7倍的性能提升,这意味着更快的推理速度和更低的计算成本。
更重要的是,DeepGEMM的开源为整个AI社区提供了宝贵的资源。它的简洁设计使开发者能够更容易地理解和学习FP8矩阵乘法和优化技术,从而将推动整个领域的进步。
GitHub地址:https://github.com/deepseek-ai/DeepGEMM
DeepSeek的开源周仍在继续,期待接下来两天还会有什么惊喜!
会不会是 R2?
或者……AGI?
(文:AGI Hunt)