
大模型训练

OpenAI帝国的真相与幻象——496页「Empire of AI」中文版电子书分享!

OpenAI由理想主义转向商业帝国的故事被深入剖析,揭示其背后的资本-算力-数据三角关系及全球南方国家的隐形成本。Karen Hao的新书《Empire of AI》揭示了AGI时代的技术霸权和数字殖民史。

独家|AI芯片巨头将在中国成立合资公司?英伟达发言人:我们拒绝发表评论

美国限制英伟达H20芯片对华出口之际,英伟达启动’B计划’在中国设立合资企业。这一调整旨在应对地缘政治紧张局势中的生存之战,但传闻存在不确定性。
【企业案例征集】大报告《AI共潮生——2025人工智能产业30条判断》征集代表性企业|

甲子光年将于4月28日举办大会发布《AI共潮生:2025人工智能产业30条判断》,征集各赛道代表性企业,涵盖L1-L4四个阶段。
聊聊强化学习发展这十年

本文通过四阶段的发展分析了强化学习的演变过程,强调了其从早期的经典在线RL到当前涵盖广泛的应用场景(如offline model-free RL, model-based RL等),以及概念扩展带来的深远影响。

成本驱动的精细系统优化,蚂蚁技术专家解密大模型推理优化秘籍|ML-Summit 2025

蚂蚁集团在AI模型训练技术上取得突破,结合’专家混合机器学习’方法提升性能和降低成本。李龙飞将分享蚂蚁集团的探索实践,包括优化推理架构、网络架构,并使用国产芯片实现降本增效。
怎么自定义一个数据集?自定义数据集面临哪些问题?
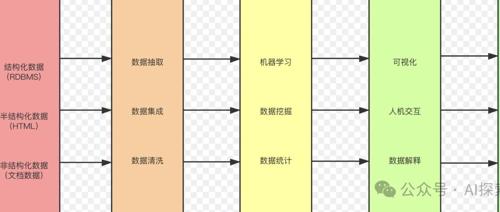
在神经网络应用中,数据集是关键问题。企业通常选择使用开源模型进行训练和微调,但数据仍是主要挑战之一。自定义数据集需要明确任务目标、收集数据、清洗数据、标注数据、预处理数据,并划分为训练集、验证集和测试集。
