上次的《最全梳理:一文搞懂 RAG 技术的5种范式!》梳理了对 RAG 进行了一个完整的综述。这次带来 RAG 的小白应用教程:介绍如何通过 ragflow 框架把 DeepSeek 接入到自己的个人知识库中,当然其他模型也是类似,可以自由搭配。
ragflow 简介:
RAGFlow 是一款基于深度文档理解的开源检索增强生成(Retrieval-Augmented Generation,RAG)引擎,旨在通过结合信息检索和生成式 AI 的优势,解决现有技术在数据处理和生成答案方面的挑战。
作用
RAGFlow 广泛应用于需要动态生成内容且依赖外部知识库的场景,例如:
-
智能客服:实时从企业知识库中检索相关信息,为客户提供准确、个性化的解答。
-
文档生成与报告分析:从多个数据源中检索信息并生成结构化的文档或摘要,适合大规模内容管理。
-
辅助诊断:医疗专业人员可以通过 RAGFlow 快速查找相关医学文献和病例资料,为诊断和治疗提供参考。
-
文献综述:帮助学生和研究人员快速定位和分析相关的学术文献,高效完成文献综述的撰写。
-
新闻报道与投资分析:记者和金融机构可以利用 RAGFlow 整合和提炼大量素材,生成新闻稿件或投资分析报告。
优势
-
深度文档理解:能够从复杂格式的非结构化数据中精准提取知识,支持多种文档格式(如 Word、PPT、Excel、PDF 等),并自动识别文档布局。
-
降低幻觉风险:提供清晰的关键引用来源,支持文本分块的可视化和人工干预,确保生成答案有据可依。
-
兼容异构数据源:无缝处理多种数据格式,整合不同来源的数据,为用户提供一站式的数据处理和问答体验。
-
自动化工作流:支持从个人应用到超大型企业的各类生态系统,提供易用的 API,便于快速集成到各类业务系统。
-
高效性与成本优化:通过动态优化流程,减少不必要的计算和查询次数,降低运行成本。
-
精准性与可靠性:检索和生成环节相辅相成,确保最终结果的准确性和可靠性。
RAGFlow 的这些特性和优势使其在信息检索和内容生成领域具有广泛的应用前景和显著的竞争力。
我的理解呢,ragflow的意义在于它把原本复杂的rag系统开发,处理成了零代码开发模式,方便非计算机背景的人也可以进行rag系统的搭建和维护,而且融入了类似dify的强大的工作流编排功能。
ragflow 本地 windows 部署
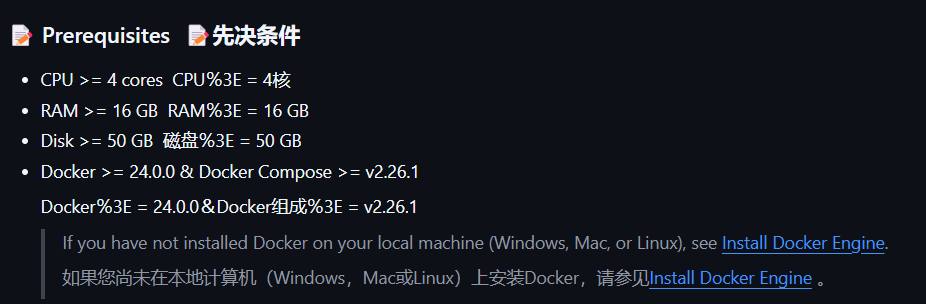
配置要求:ragflow是一个相当“重”的项目,如果你的电脑不满足以下条件,请不要随意尝试
一、软件配置安装
https://www.runoob.com/docker/windows-docker-install.html
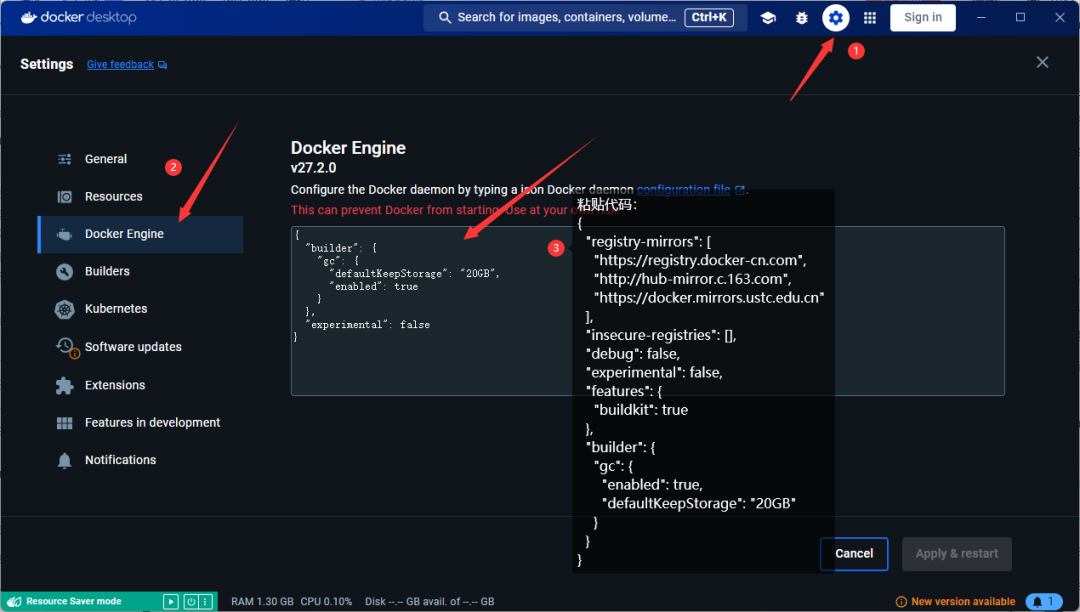
安装好 docker 后启动即可,不用登陆不用设置任何东西,一路跳过。
{
"registry-mirrors": [
"https://registry.docker-cn.com",
"http://hub-mirror.c.163.com",
"https://docker.mirrors.ustc.edu.cn"
],
"insecure-registries": [],
"debug": false,
"experimental": false,
"features": {
"buildkit": true
},
"builder": {
"gc": {
"enabled": true,
"defaultKeepStorage": "20GB"
}
}
}
然后我们需要安装 git:https://cloud.tencent.com/developer/article/2099150
最后我们需要安装 vscode:https://zhuanlan.zhihu.com/p/264785441
二、安装 ragflow
设置安装路径
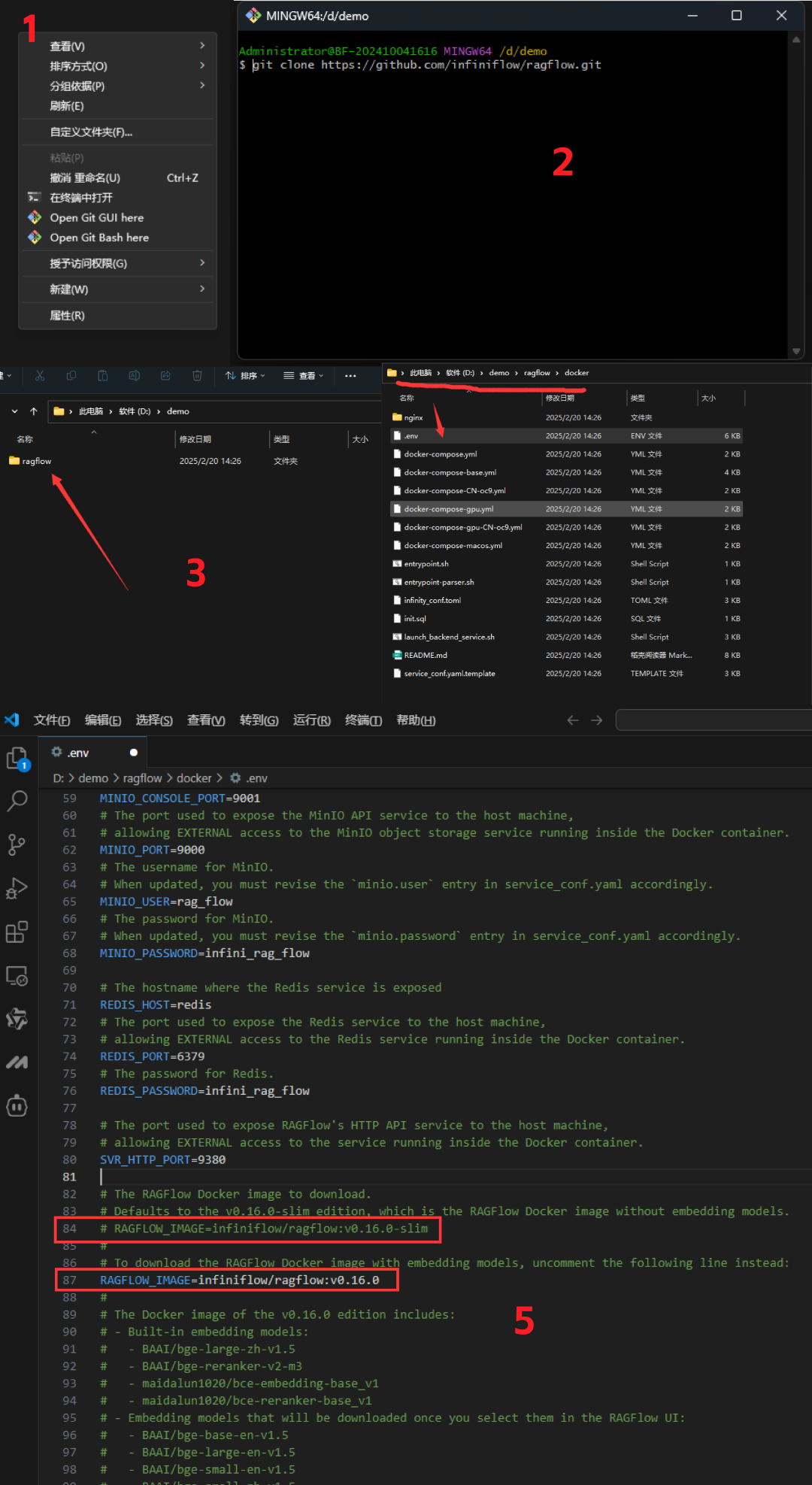
在 c 盘之外的地方打开一个文件夹用来安装 ragflow,鼠标右键,点击 open Git Bash here
git clone https://github.com/infiniflow/ragflow.git
由于默认配置版本是没有 embedding 模型的,所以我们修改配置为完整版。使用 vscode 打开 .env 文件,修改第 84 行和第 87 行,ctrl+s 保存文件。
拉取 docker 镜像
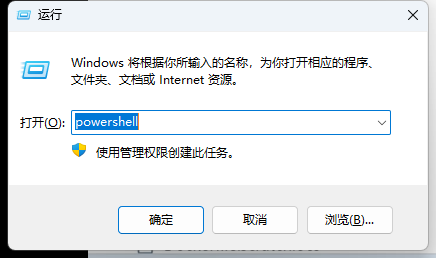
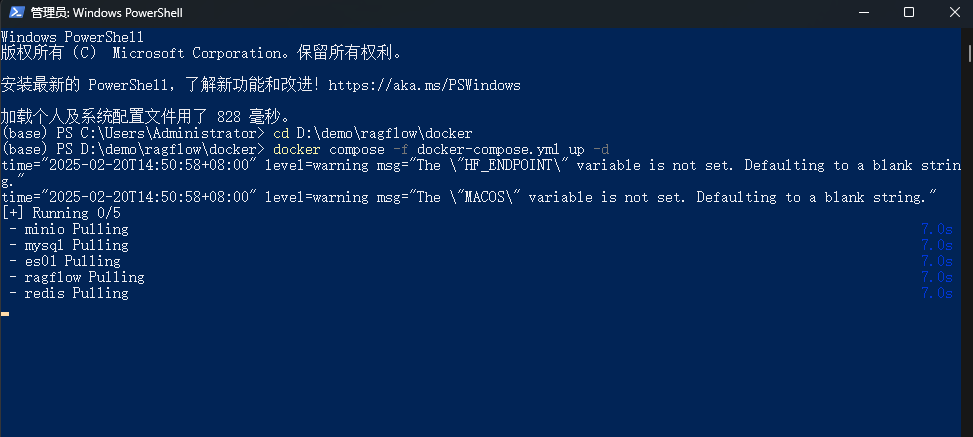
接下来我们开始部署 docker 镜像,按住 win+R 键,输入 powershell,点击回车。之后输入 cd+刚刚下载的ragflow文件夹路径,我这里是cd D:\demo\ragflow\docker按回车,输入docker compose -f docker-compose.yml up -d按回车。之后可以看到正在使用 docker 加载镜像,稍等一会儿加载完毕即可。
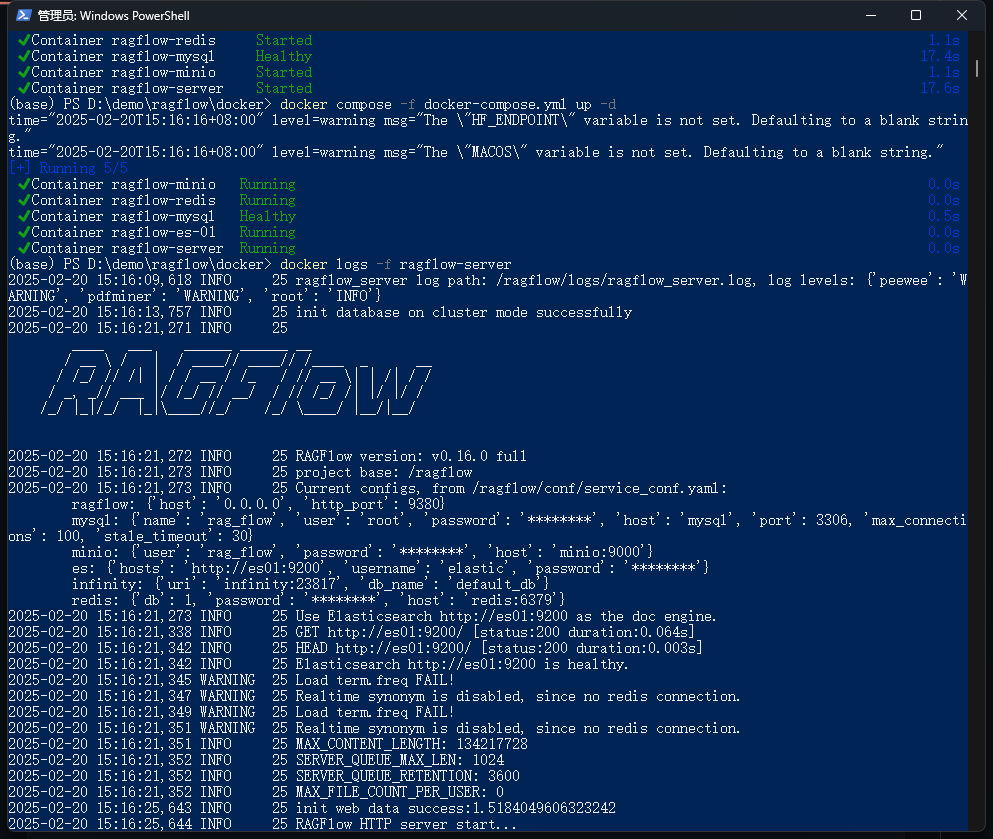
大概 15 分钟后镜像加载完毕就部署完毕了。最后我们输入docker logs -f ragflow-server,出现 RAGFLOW 字体就代表后端服务启动成功了。
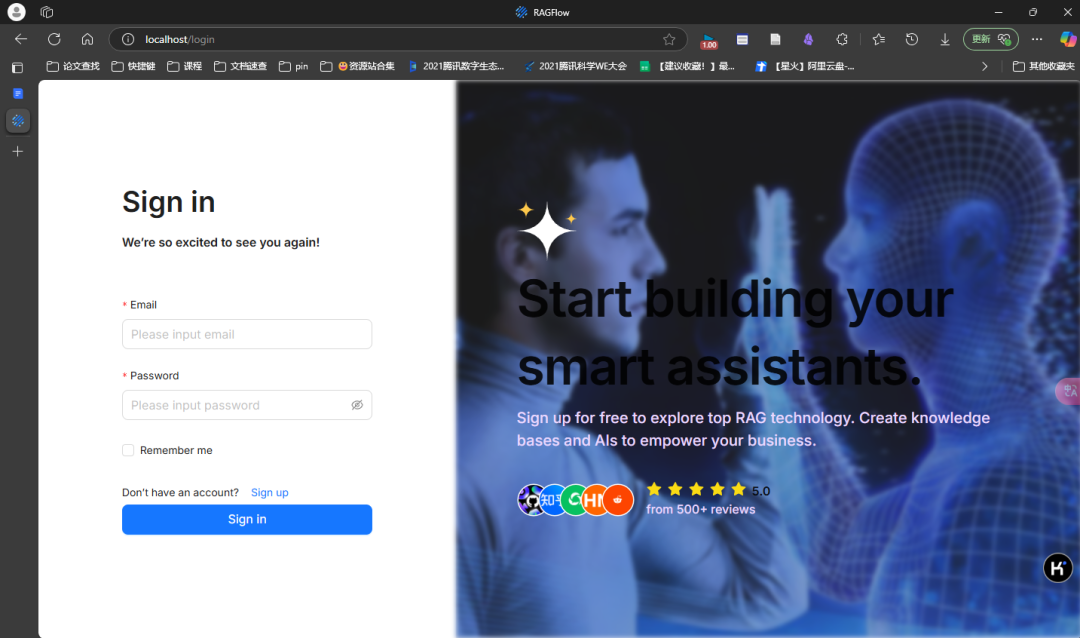
之后我们在浏览器地址栏输入:localhost:80即可打开ragflow登录页面。登录页面可以随便输入一个邮箱账号(随便编一个符合邮箱格式的就可以),全部是保存在你本地电脑上的,不用担心数据泄露。但是要注意第一个注册的默认是管理员,所以还是要注意保存一下你注册的邮箱信息。之后点击登录就可以使用ragflow了。
三、简易使用教程
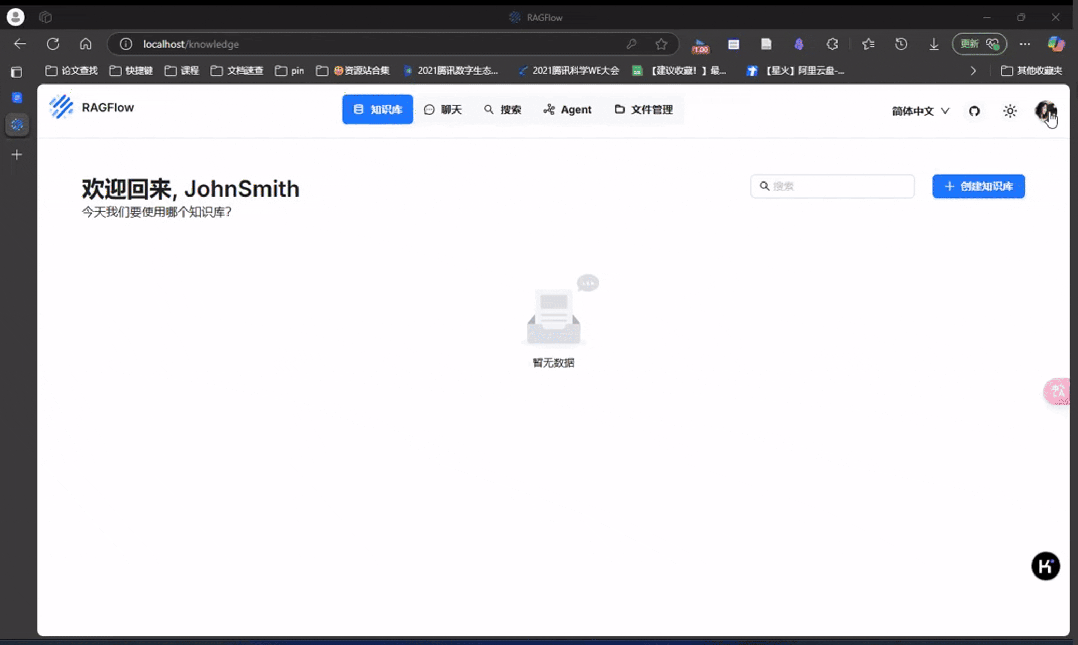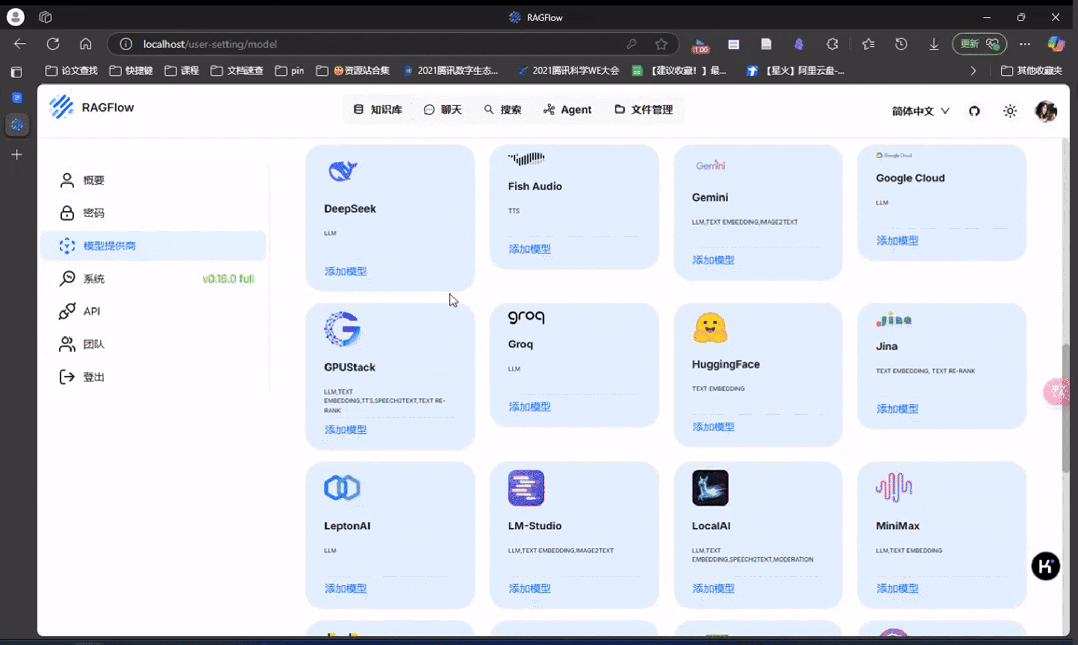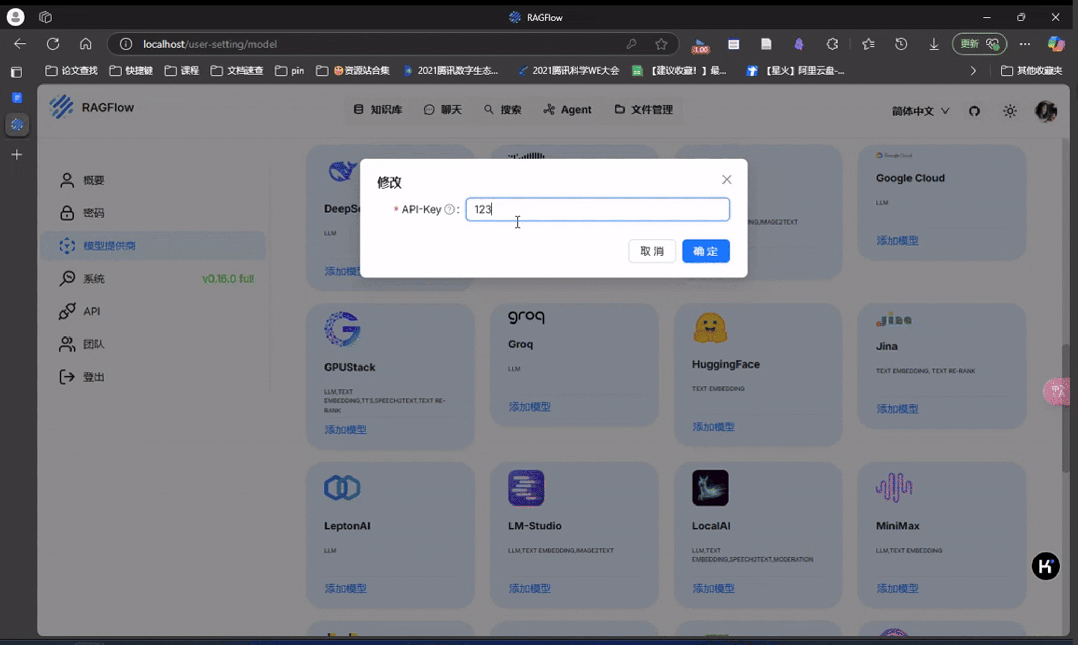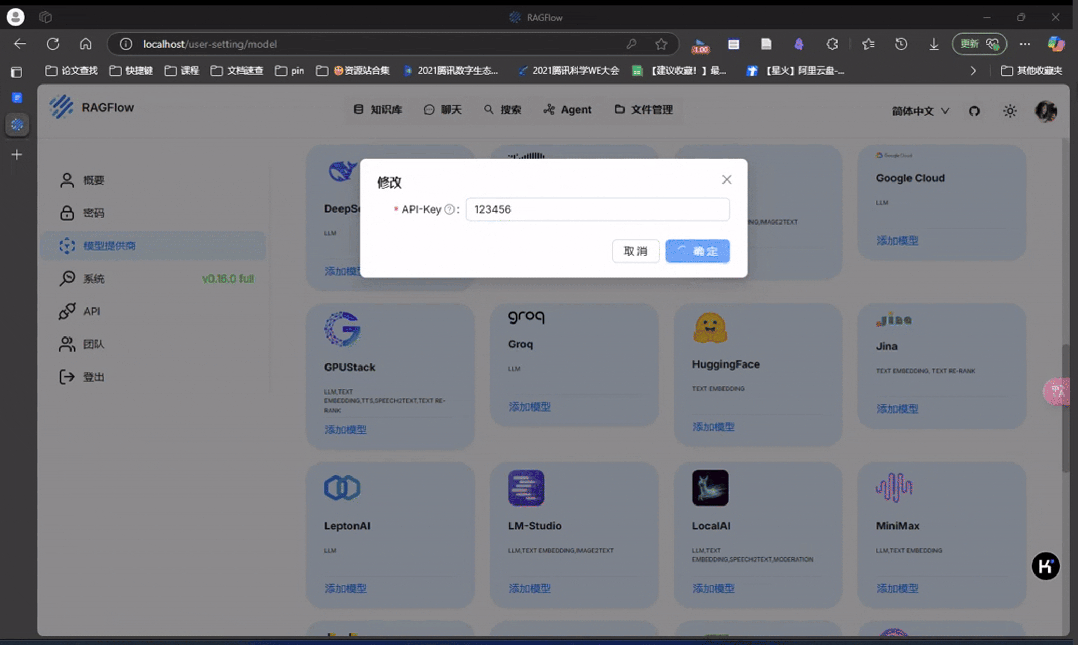
首先我们配置一下 deepseek 模型服务,api-key 可以从 https://platform.deepseek.com/api_key 申请获取(官网已经恢复充值)。
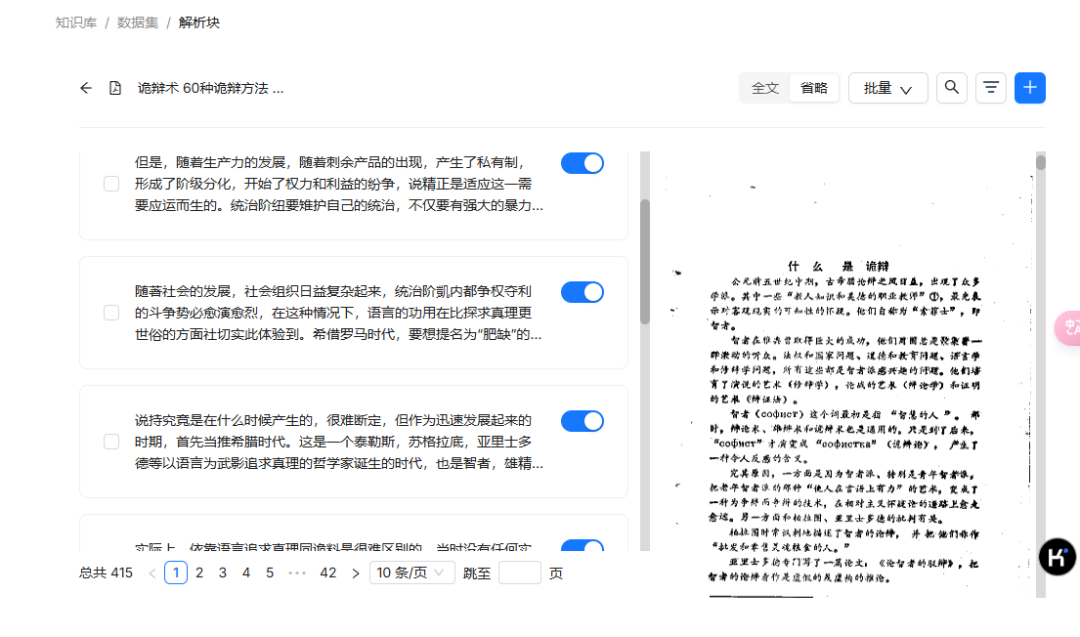
之后我们上传资料创建一个本地知识库就可以啦。可以看到上传的资料支持多种格式,扫描版的 pdf 文档也是可以的。

上传文件之后需要等待文档解析完成,可以看到文档解析的效果还是不错的
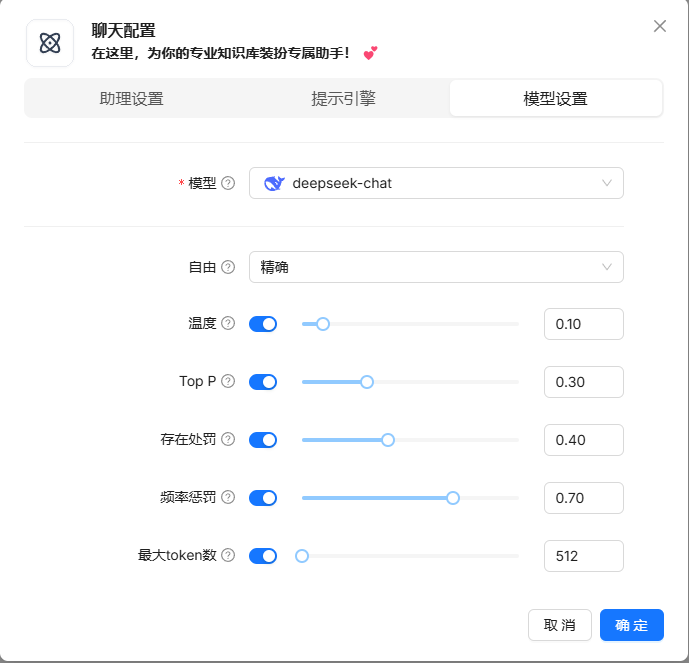
创建对话助理后,就可以对话啦,注意在模型设置里把模型替换为 deepseek-chat
四、启动与关闭 ragflow 程序:
关闭 ragflow 程序:
关掉 powershell 窗口,退出 docker 进程即可。
启动 ragflow 程序:
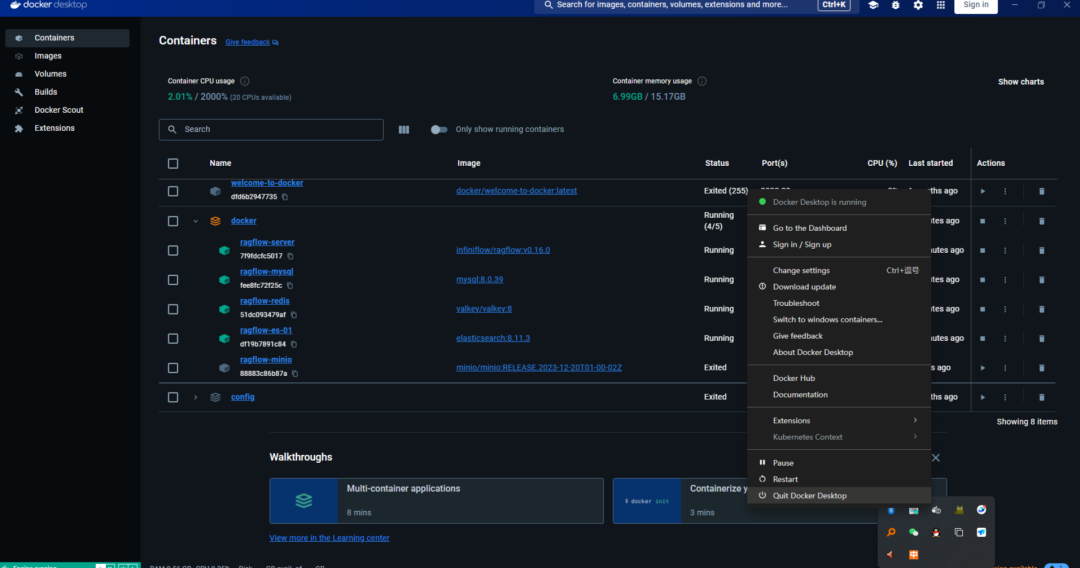
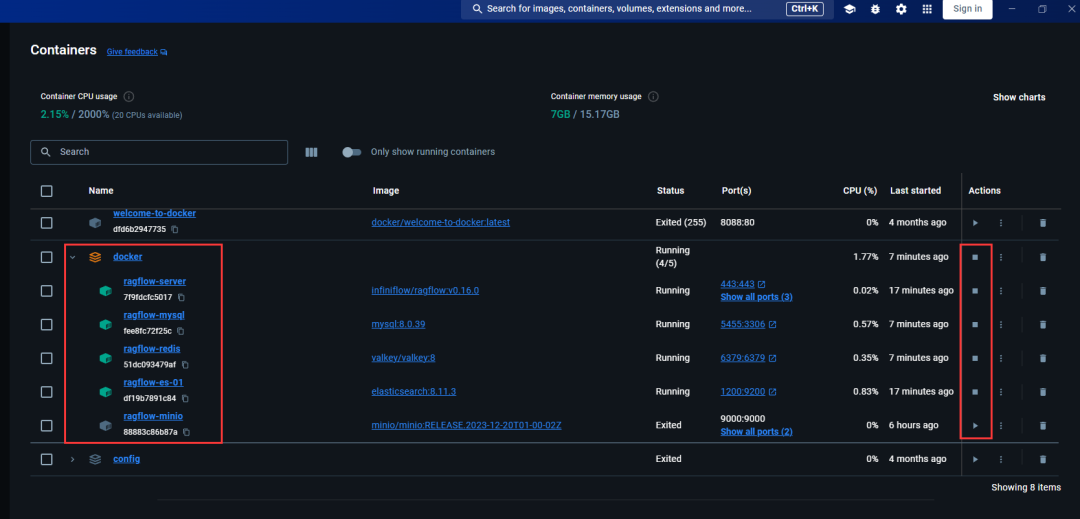
打开 docker 软件,按下 win+R 打开 powershell,输入docker logs -f ragflow-server回车,就启动了后端服务了。!!检查一下 docker 软件,看一下 ragflow 是否全部启动,也就是下图中的几个服务全是运行状态:
如果都在运行中,此时可以在浏览器输入localhost:80即可启动前端界面,愉快的使用 ragflow 啦!
本教程主要参考以下两篇官方文档撰写:
1. https://github.com/infiniflow/ragflow?tab=readme-ov-file
2. https://ragflow.io/docs/dev/
 一起“点赞”三连↓
一起“点赞”三连↓
(文:Datawhale)