
白交 发自 凹非寺
量子位 | 公众号 QbitAI
最新消息,斯隆奖得主、姚班校友马腾宇大模型创业成果,被收购!
收购方是MongoDB,一家开源数据库上市龙头。
而距离他2023年11月官宣创业Voyage AI不到一年半的时间。当时创业阵容十分之瞩目和豪华,李飞飞曼宁等大佬担任顾问。
他们主要是做针对RAG(检索增强生成)专门优化的嵌入模型,为智能 AI 应用程序提供支持。
在这短短一年多时间里,模型更新到了第三个版本,实现了最先进的检索精度和向量存储成本的大幅降低;期间完成了两轮融资,总筹集金额达到2800万美元。
此次收购,具体金额还未透露。
但在马腾宇公司博客中透露了他们选择被MongoDB收购的原因。

简单来说就是,两者强强联合,将AI检索模型直接引入数据库,在更统一的堆栈下带来更高效的开发体验,还能提高AI应用程序的性能和准确性。
不少业内人士,在马腾宇推文底下表示了祝贺。
5年时间做出SOTA嵌入模型
当初创业时,他们曾透露一个重要的创业原因是认为业界对嵌入模型的重视程度远远不够。
嵌入模型与生成式模型有一定相似之处,但更加侧重于语义理解,通过神经网络(通常是Transformer)架构来对语义上下文进行捕获和压缩。
难度上,训练嵌入模型和生成式模型一样困难——训练高质量的嵌入模型需要在架构、数据、损失函数等许多方面进行反复实验。
于是,他们用了5年时间,收集了海量训练数据和预/后处理方法,最终打造出了一款SOTA的嵌入模型。
而在创业之后,模型的迭代还在继续。
Voyage发布了诸多系列模型,包括通用嵌入模型、代码检索嵌入模型、多模态嵌入模型,他们都在过去三个月期间都纷纷升级到了第三个版本。
通用和多语言嵌入模型voyage-3-large:该模型在涵盖 100 个数据集的八个评估领域中排名第一,包括法律、金融和代码,上下文长度为32K。通过俄罗斯套娃表征学习(MRL)和量化感知训练,支持更小的尺寸和 int8 和二进制量化,可显着降低 vectorDB 成本,同时对检索质量的影响最小。
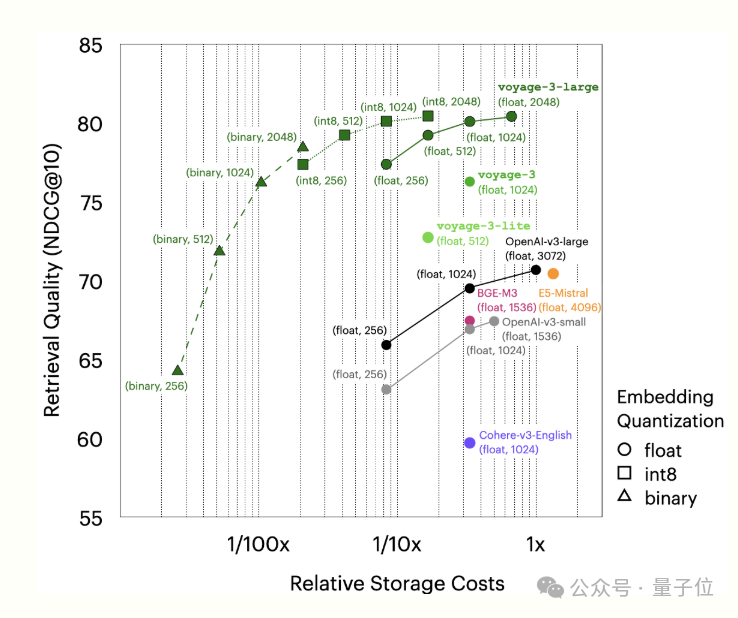
基于代码检索的嵌入模型voyage-code-3。在一组32个代码检索数据集上,它的性能分别比 OpenAI-v3-large 和 CodeSage-large 平均高出 13.80%和16.81%。通过使用 Matryoshka 学习和量化格式(如 int8 和二进制格式)支持更小的维度,voyage-code-3 还能显著降低存储和搜索成本,同时将对检索质量的影响降至最低。
多模态嵌入模型voyage-multimodal-3,可用于包含丰富视觉和文本的文档。与现有的多模态嵌入模型不同,voyage-multimodal-3 能够对交错文本和图像进行矢量化处理,并从 PDF、幻灯片、表格、数字等截图中捕捉关键视觉特征,从而省去了复杂的文档解析过程。在对 3 个多模态检索任务(共 20 个数据集)进行评估时,voyage-multimodal-3 比性能仅次于它的多模态嵌入模型平均提高了 19.63% 的检索准确率。
与此同时,还积累了一众顶尖的合作伙伴,包括AWS、Databricks、Anthropic、Harvry、LangChain、Replit等等知名公司。
此次收购之后,Voyage AI可以MongDB带来什么?
用一张图就可以概括之。
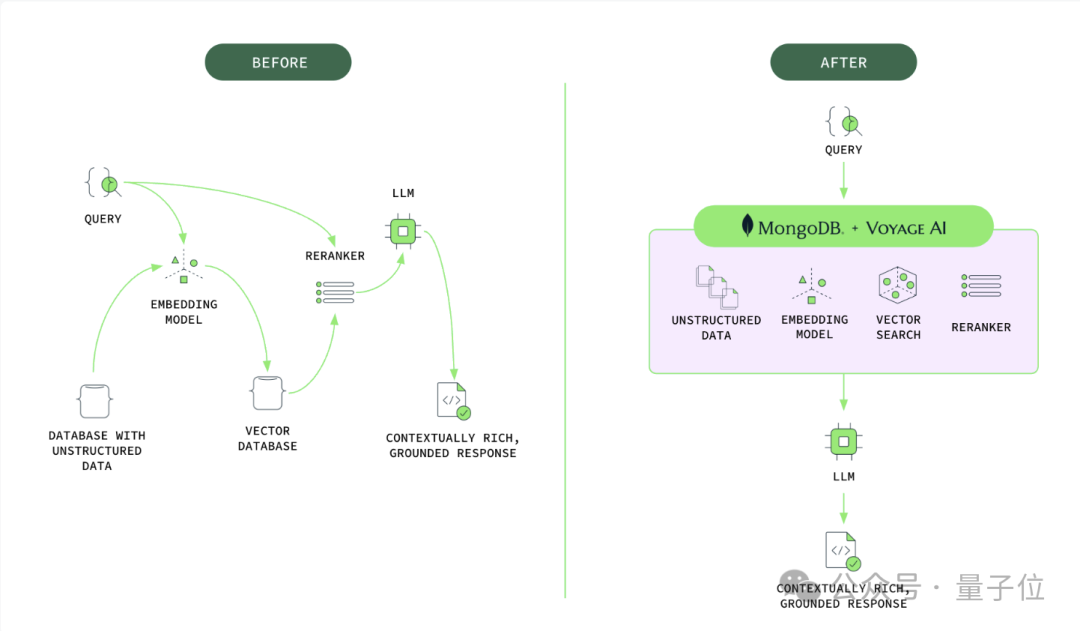
以往开发人员需要依靠各种独立组件来构建AI应用程序,这些组件的次优选择(例如嵌入模型)可能导致数据检索相关性低和生成输出质量低下。这种分散的方法对开发人员来说既复杂又昂贵,效率低下,而且繁琐。
现在,他们无需实施变通方法或管理单独的系统,而是可以从实时操作数据中生成高质量的嵌入、存储向量、执行语义搜索并优化结果 – 所有这些都在 MongoDB 中完成。
对于此次收购,MongDB CEO表示:
AI有潜力改变每个行业,但其应用因“幻觉”可能带来的风险而受到限制。通过将先进的AI驱动搜索和检索能力整合至我们高度灵活的数据库系统中,MongoDB和Voyage AI将帮助企业轻松构建能够创造重大业务影响的可靠AI应用。通过此次收购,MongoDB重新定义了AI时代的数据库。
马腾宇则表示:要使AI应用程序发挥全部潜能,企业必须信任其输出结果,因此需要将检索与操作数据深度集成,以确保其准确性和相关性。加入MongoDB使我们能够将前沿的AI检索技术带给更广泛的受众,并将其无缝集成到关键任务应用中。通过将我们在嵌入和重排序方面的专业知识与MongoDB一流的数据库相结合,我们可以帮助组织构建能够大规模提供更准确、更可靠结果的AI应用,使他们能够自信地将AI应用于高风险用例。
清华姚班校友,和陈丹琦同学
马腾宇,现任斯坦福大学助理教授,研究方向包括机器学习、算法及其理论等多项内容。

其学生都分布在各个顶尖大厂和机构从事科研探索。

他本科毕业于清华姚班,和陈丹琦是同班同学。随后去到普林斯顿攻读博士学位导师是理论计算机科学家、两届哥德尔奖得主Sanjeev Arora教授。
读博期间,马腾宇获得了理论计算机方向的西蒙斯奖等诸多奖项,被导师夸赞“比自己还聪明”。
博士毕业后,MIT、哈佛、斯坦福等顶尖高校都给了他助理教授的Offer,马腾宇最终选择了斯坦福。
2021年,马腾宇获得了具有“诺奖风向标”之称的斯隆奖,成为继鬲融之后清华姚班又一名获此奖项的校友。
时间来到2023年11月,他官宣创业Voyage。不过创业期间,他始终还在斯坦福进行一些前沿探索。
比如他与Google Brain推理团队创建者Denny Zhou联手证明,只要思维链足够长,Transformer就可以解决任何问题。通过数学方法,他们证明了Transformer有能力模拟任意多项式大小的数字电路,论文已入选ICLR 2024。

而就在月初,他还提出了STP, 一种可以无限猜测和证明的自玩算法,从而实现在有限的数据情况下不断地改进模型。当时他的单位是斯坦福。

至于公司被收购后的下一步产业动向,马腾宇还没有透露。或许接下来还可以期待更多学术成果~
(文:量子位)