

JourneyBench团队 投稿
量子位 | 公众号 QbitAI
多模态模型在学术基准测试中获得高分,到了真实世界应用时却表现不及预期,该如何分辨?
新的综合性视觉语言理解基准JourneyBench,利用基于diffusion模型提示生成的图像,并采用一种新颖的人机闭环框架,通过五项具有挑战性的任务来评估多模态模型的推理能力:
-
多模态链式数学推理 (Multimodal Chain-of-Thought)
-
多图像视觉问答 (Multi-image VQA)
-
细粒度跨模态检索 (Fine-grained Cross-modal Retrieval)
-
包含幻觉触发的开放式视觉问答 (VQA with Hallucination Triggers)
-
非常见图像的描述 (Unusual Image Captioning)

JourneyBench由哥伦比亚大学、弗吉尼亚理工和加州大学洛杉矶分校的团队提出,是Google Deepmind的多模态(Gemini)团队提出的HaloQuest, ECCV 2024的衍生工作。
HaloQuest的第一作者联合哥伦比亚大学、弗吉尼亚理工和加州大学洛杉矶分校构建了一个综合性的视觉语言理解的训练以及评价基准JourneyBench。

团队认为尽管现有的视觉语言理解的评价基准推动了显著进展,但它们通常包含有限的视觉多样性,并且场景的复杂性低于日常生活中遇到的情况:
-
许多基准因互联网图片的版权限制,将其图像分布限制在像COCO或Flickr这样的平台和资源中。
-
这些基准往往限制于日常常见的物体和场景,而非罕见甚至微抽象的场景。
-
这些基准的过分同质化的数据在模型的预训练中也多有出现,模型很容易通过学习到的偏见在测试中表现优异,但不一定真正理解图像内容。
这种偏见、偏差可能会在学术基准测试中提高分数,但在过渡到真实复杂的世界应用时却会带来显著挑战。
此外,用于评估多模态链式数学推理的基准常常包含冗余的视觉内容(即视觉信息并不需要,模型就可以回答问题的内容)。当前的多模态链式数学推理基准也未能充分解决其他的关键问题,例如幻觉现象和预测一致性。在检索任务的基准测试中,模型的性能接近人类水平,难以区分不同模型。这种性能饱和部分是由于现有检索基准缺乏细粒度的细节,对当今强大的模型缺乏足够的挑战性。
基于diffusion模型的提示生成的图像近些年兴起,这为创造更具挑战性和全面的多模态基准提供了独特的机会。与真实图像不同,这些生成的图像避免了版权问题,并提供了多样化的视觉内容,从而能够设计更具挑战性和注重细微差别的测试场景。
-
生成图像可以结合罕见的概念,例如“马卡龙上的大象”,这在传统数据集中极为罕见,但对于评估模型对视觉概念的真实理解至关重要。例如,COCO中包含的对象关系在常识数据库ConceptNet中占68%,而我们收集的生成图像中仅占6%。
-
此外,随着生成图像变得越来越逼真,并在网上大量涌现,将其纳入基准以评估模型理解和解释多样化视觉场景的能力将变得日益重要。
-
通过利用基于提示生成的图像,可以克服现有基准的局限性,提供更好的可控性和视觉内容多样性。这种方法能够严格测试模型的幻觉倾向、一致性,以及在各种不可预测环境中有效运行的能力。

数据介绍
JourneyBench用五项多模态理解任务测试模型在罕见场景中的推理应用能力:
非常见图像的描述 (Unusual Image Captioning)
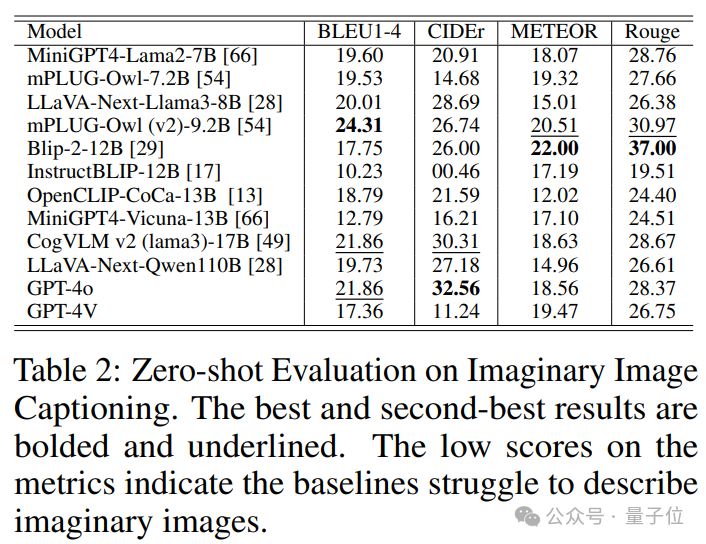
图像描述是VLU基准测试中的标准任务,JourneyBench旨在测试模型理解和描述虚构图像的能力。为了利用基于提示生成的图像进一步推动 VLU 评估的边界,并测试现有模型在之前评估工作中被忽略的能力,JourneyBench特别关注虚构图像。被测试模型需要生成一句话的图像描述,突出使其成为虚构图像的元素。
细粒度跨模态检索 (Fine-grained Cross-modal Retrieval)
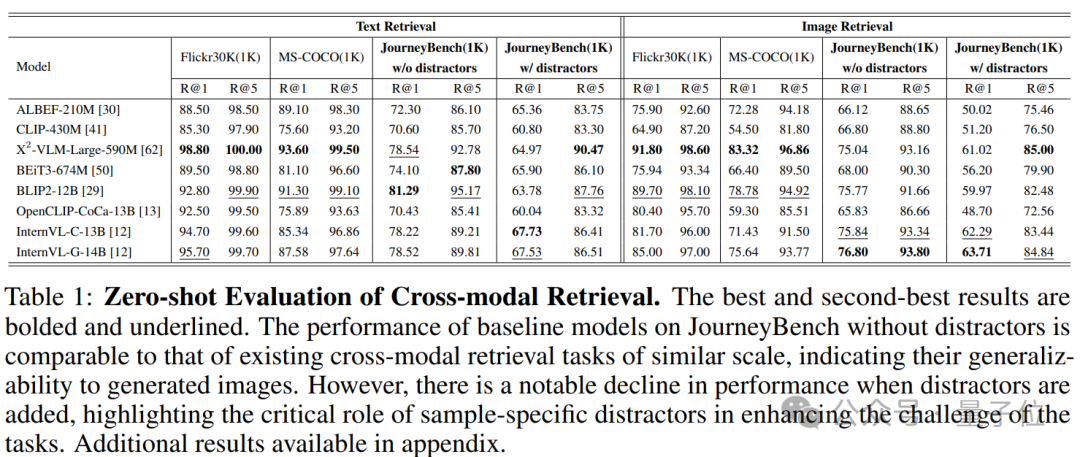
跨模态检索是许多基准中包含的一项基础性多模态理解的任务。给定一张图像,其目标是检索匹配的文本,反之亦然。然而现在有的扩模态检索缺乏样本为中心的干扰选项,致使模型只需关注图像之间的整体不同而非object-level的细粒度的不同。
多模态链式数学推理 (Multimodal Chain-of-Thought)
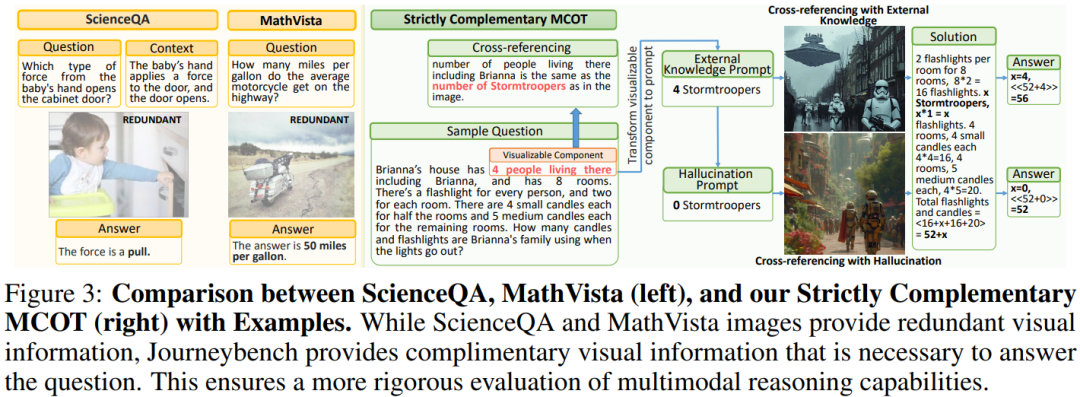
在多模态链式数学推理任务中,输入由一张图像和一个问题组成,两个模态的信息绝不重合并且强制互补,要求模型整合来自两种模态的信息来进行链式的数学推理。JourneyBench不单单检测最终答案的准确性,也会评审答题思路的准确性。
多图像视觉问答 (Multi-image VQA)
该任务要求模型在视觉问答中对多张图像进行推理。然而,由于真实图像资源有限,现有数据集主要测试模型的基本能力,例如颜色匹配、图文匹配和物体计数。相比之下,JourneyBench 评估三个特定的能力且延伸到更有挑战性的推理类别,比如:第一次提出多图片的多模态算术推理、将外部知识应用于视觉推理以及识别多模态因果关系。这是目前最大的多图片视觉问答数据资源。
包含幻觉触发的开放式视觉问答(VQA with Hallucination Triggers)
基于之前HaloQuest的工作,JourneyBench也包含了容易从三种模态(文字,图片和外部知识)来触发模型进行幻觉的问题。这些问题都围绕着基于diffusion模型提示生成的各种非常见图像。该任务包含三个类别的问题,对应着三种触发模态,旨在触发模型的幻觉:带有错误前提的问题(幻觉触发存在于语言模态)、询问挑战性视觉细节的问题(幻觉触发存在于视觉模态)和最后缺乏足够上下文以进行准确解释的问题(幻觉触发存在于外部知识)。
数据样本如下图所示:

非常见图像的描述 (Unusual Image Captioning)
图像描述是多模态理解基准测试中的标准任务,JourneyBench测试模型对非常见图像的理解和描述能力。
为此,我们要求模型生成一句话的图像描述,突出点出使该图像显得非常见甚至虚构的元素。非常见甚至虚构的图像与现有基准中的真实图像有很大不同,JourneyBench将其定义为描述不寻常视觉组合或现实中不可能存在的虚构场景的生成图像。如果我们分析视觉元素和关系在ConceptNet中的存在比例,COCO数据集中的对象和关系在ConceptNet中有68%的匹配率,而JourneyBench的生成图像中这一比例仅为6%。
细粒度跨模态检索(Fine-grainedCross-modalRetrieval)
在MS-COCO和Flickr30K等流行的跨模态检索基准上。这些基准主要涉及真实图像,且重点是整体区分图像和文本的配对。然而,为了使模型能够准确检索相关内容,能够在细粒度层面区分图像-文本配对至关重要。为了挑战模型在类似图像中进行细粒度区分的能力,JourneyBench用对抗性人机闭环框架,为每个查询样本创建特定的干扰项,即需要细粒度辨别才能克服的难负样本。
JourneyBench通过多轮注释和一致性检查进行质量保证,以防止出Falsepositive报或Falsenegative。目前领域中常用的数据集通常面临诸如不一致、FP/FN、模糊性等问题,如下图所示。这主要源于从原始描述数据集中抽样的过程。尽管已经有一些努力试图纠正这些准确性问题,但这些尝试却无意中引入了原始数据集中不存在的误报。JourneyBench的标注过程以及生成图片自身的多样性使得上述问题极少存在于样本中。更高质量的数据使得JourneyBench对模型性能的测试更准确。

多模态链式数学推理(Multimodal Chain-of-Thought)
现有的多模态链式数学推理数据资源(如MathVista和ScienceQA)通常包含冗余的视觉信息,使得模型仅通过语言输入就能回答问题。与MathVista和ScienceQA等多模态推理数据不同,在JourneyBench的多模态数学推理中,视觉信息和文本信息是严格确认没有任何重叠信息的,而且是互补的,以确保模型在链式数学推理过程中必须从两种模态中获取信息才能够正确解题。
多图像视觉问答(Multi-imageVQA)
最近,有少数多图像视觉问答基准被提出,要求模型在VQA视觉问答中对多张图像进行推理。然而,由于真实图像资源的有限性,现有数据集主要测试基本能力,例如颜色匹配、图像-文本匹配和物体计数。相比之下,JourneyBench的多图像VQA任务拓展了三个具体且更具有挑战性的推理类别:多图片算术推理、多图片的将外部知识应用于视觉的推理,以及多图片的因果关系的识别。
包含幻觉触发的开放式视觉问答(VQAwithHallucinationTriggers)
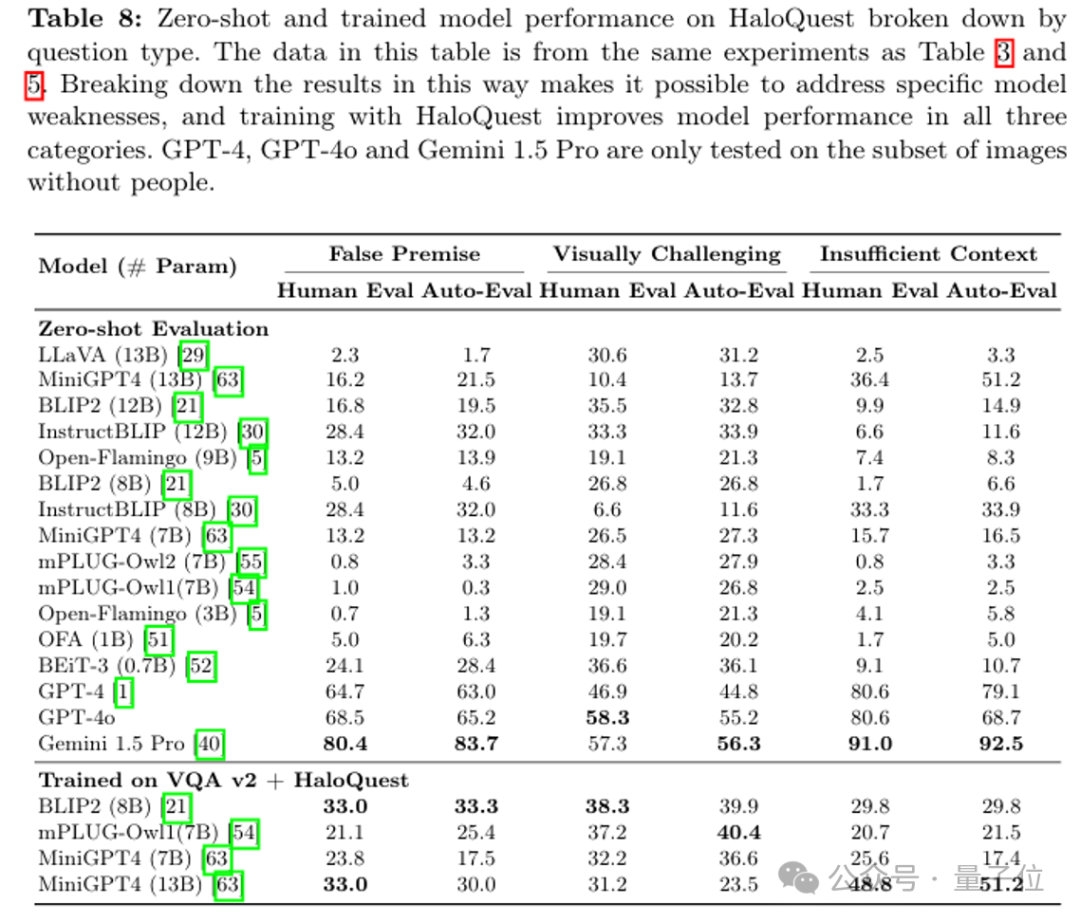
基于Haloquest,JourneyBench也包含了包含幻觉触发的开放式视觉问答。这个任务是第一次在多模态理解和推理任务重系统的分析了幻觉的触发形式,特别是很横跨文字、视觉和外部知识三个模态,找到了对应的三种幻觉触发模型。这个任务也利用了人机闭路方法收集了问题以及非常见甚至虚幻场景的图片。为了让这个任务更有通用性,它结合GoogleDeepmind开发了一款开放性的VQA视觉问答的评价机制,并且证明了其和人体评价的相似性。这个任务第一次提出了用diffusion模型生成的图片来帮助模型进行挑战性的评价甚至训练的范式,并且通过实验证明了这个范式的可行性。其工作进一步证明了,HaloQuest的训练数据配合着instructiontuning也能有效的改善现有大模型的幻觉行为。
实验与分析
研究选取了共21个多模态模型用以不同任务的实验分析,其中包括:
-
跨模态检索模型:ALBEF、CLIP
-
开源通用模型:MiniGPT4、mPLUG
-
开源多图像模型:VILA、Idefics2、Mantis
-
闭源模型:GPT-4V、GPT-4o
研究发现:
1. 模型在区分细粒度视觉细节方面存在困难。在JourneyBench中的检索分数低于MS-COCO和Flickr30k,表明模型在从我们数据集中检索文本和图像时面临更大的挑战。
2. 模型对非常见以及虚构的视觉场景并不适应。大多数模型在JourneyBench上的表现远逊于在其他图像描述数据集上的表现,其中大部分模型的CIDEr得分低于30。
3. 跨模态算术推理中具有挑战性。除GPT和LLaVA外,大多数其他模型得分低于10%。值得注意的是,GPT-4V和GPT-4o在包含众多物体的视觉环境中,在一致性、幻觉和跨模态方面表现不佳。
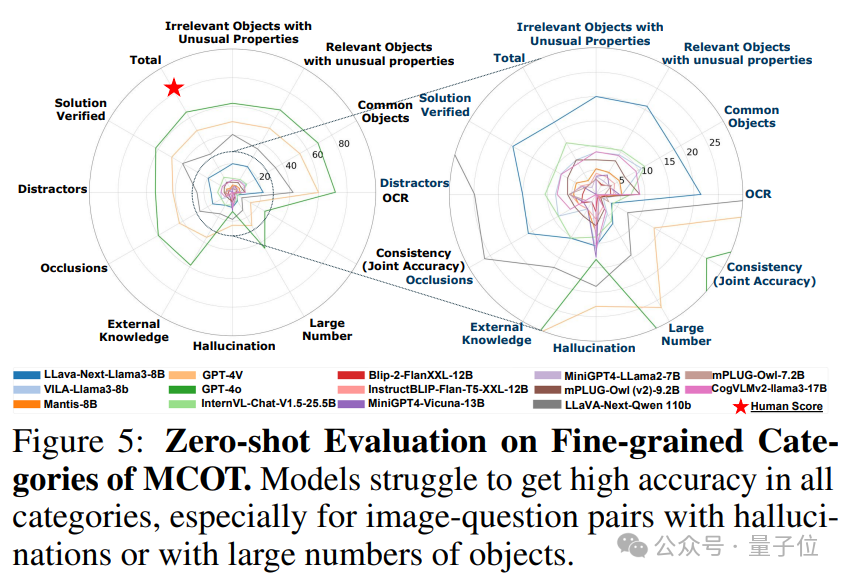
4. 多张图像的跨模态问答极具挑战性。总体来看,各种模型在JourneyBench中跨多张图像问答时遇到了极大的困难,特别实在多图像的夸模态数学推理,外部知识的推理问答和因果关系的判别。
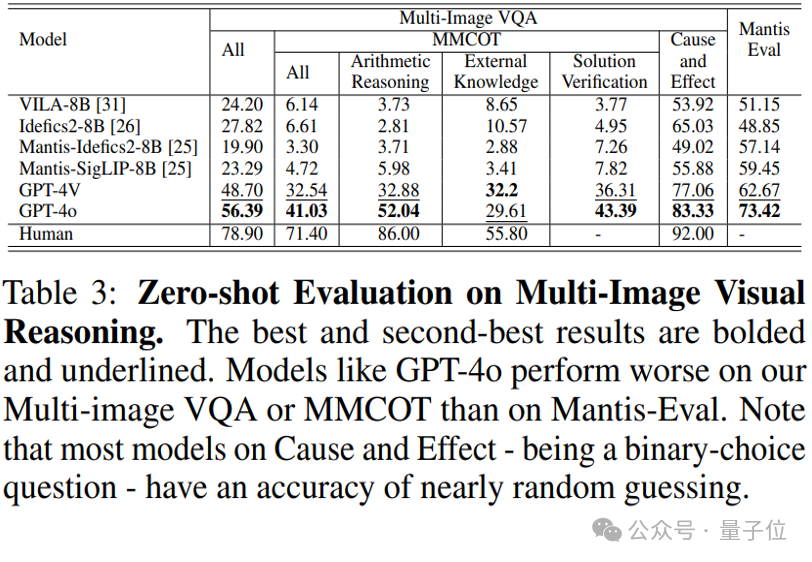
现有的VLMs视觉和语言的多模态模型在幻觉问题上表现不佳,显示出较高的幻觉率。这一结果表明模型能力存在显著不足,并突出了需要有效的幻觉缓解方法。此外,模型规模的增加并不一定代表能提高其对幻觉的抵抗能力。
结论
JourneyBench是一种全新的多模态理解和推理的基准,用于测试模型在各种任务中对不寻常或虚构图像的理解能力,包括多模态链式数学推理、多图像VQA视觉问答、非常见和虚幻图像的描述、侧重幻觉的视觉问答以及细粒度的跨模态检索。JourneyBench的任务使之前所有测试过的高评分模型在评估中得分持续较低,突显出其不寻常或虚构图像的主题、策略性设计的干扰项、引发幻觉的问题以及需要跨模态共指的问题所带来的挑战。这使得JourneyBench成为评估先进多模态视觉和语言模型MM-LLMs能力的理想工具,推动这些模型在理解和解释能力上的极限。
https://journeybench.github.io/
学术投稿请于工作日发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉我们:
你是谁,从哪来,投稿内容
附上论文/项目主页链接,以及联系方式哦
我们会(尽量)及时回复你

一键关注 👇 点亮星标
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
(文:量子位)