跳至内容

文| 林文琪
开源热潮卷到了视频大模型。2月25日晚,阿里云深夜抢先开源旗下视觉生成基座模型万相2.1(Wan)。2月18日,昆仑万维开源其旗下面向AI短剧创作的视频生成模型SkyReels-V1、中国首个SOTA级别基于视频基座模型的表情动作可控算法SkyReels-A1。近期“AI大模型六小龙”中一向低调的阶跃星辰官宣将在3月开源图生视频模型。
据悉,阿里云此次开源采用最宽松的Apache2.0协议,14B和1.3B两个参数规格的全部推理代码和权重全部开源,同时支持文生视频和图生视频任务,在权威测评中,万相2.1也已经超越了Sora、Luma、Pika等国内外模型。
2023年7月,通义万相图像生成大模型首次亮相。在2024年云栖大会上,阿里云CTO周靖人宣布通义万相全面升级,并发布全新视频生成模型,可生成影视级高清视频,应用于影视创作、动画设计、广告设计等领域。
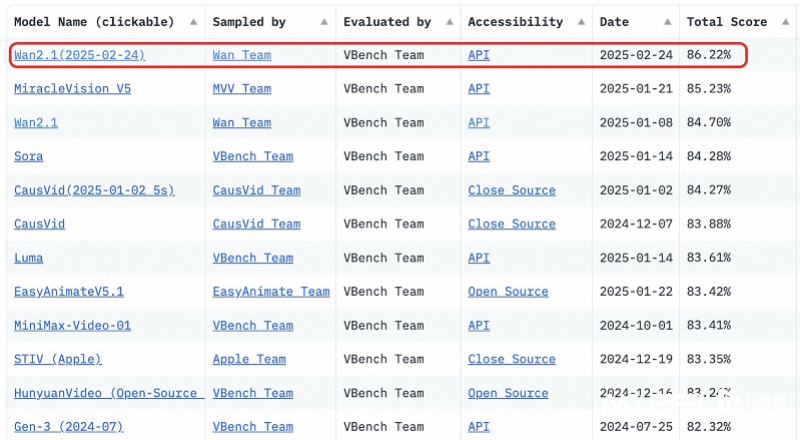
早在今年1月,万相就宣布推出升级版2.1版本模型,其在视频生成、图像生成两大能力均有显著提升。据介绍,此次开源的14B万相模型在指令遵循、复杂运动生成、物理建模、文字视频生成等方面表现突出,在权威评测集VBench中,万相2.1以总分86.22%的成绩超越Sora、Luma、Pika等国内外模型。
万相2.1以总分86.22%的成绩居VBench榜单第一。
另外,万相模型1.3B版本测试结果不仅超过了更大尺寸的开源模型,甚至还接近部分闭源模型,同时能在消费级显卡运行,仅需8.2GB显存就可以生成高质量视频,适用于二次模型开发和学术研究。
在算法设计上,据悉万相基于主流DiT架构和线性噪声轨迹Flow Matching范式,研发了高效的因果3D VAE、可扩展的预训练策略等,目前万相大模型可以实现无限长1080P视频的高效编解码,另外该模型通过将空间降采样压缩提前,在不损失性能的情况下进一步减少了29%的推理时内存占用。
值得一提的是,在蛇年春晚上阿里云视觉生成基座模型万相已“小露一手”,比如在莫文蔚与毛不易合唱的《岁月里的花》节目中,阿里通义万相利用图像风格化和首尾帧视频生成技术,生成了沉浸式的油画风舞美效果。
万相团队的实验结果显示,在运动质量、视觉质量、风格和多目标等14个主要维度和26个子维度测试中,万相均达到了业界领先表现,并且斩获5项第一。根据阿里展示的案例,用户输入:“以红色新年宣纸为背景,出现一滴水墨,晕染墨汁缓缓晕染开来。文字的笔画边缘模糊且自然,随着晕染的进行,水墨在纸上呈现‘福’字,墨色从深到浅过渡,呈现出独特的东方韵味。背景高级简洁,杂志摄影感”的指令。
通义万相2.1模型可以根据要求,输出具有中国特色及浓郁的新年风格的视频素材,且该段视频素材中完整准确地将中文字“福”字呈现。南都记者以同样的提示词输入国内其他视频生成模型,尚未有效果更好的视频生成模型。
由DeepSeek引发的开源热正在席卷行业。近期,百度宣布百度文心大模型4.5将开源,月之暗面也首次在其关于注意力机制的论文中公布了相关代码。自2月24日起,DeepSeek接连开源5天5个代码库,截至目前已发布涉及GPU使用场景的效率优化、用于MoE模型训练和推理的开源EP通信库等代码库。
在DeepSeek引发的开源潮下,近期不少厂商除了开源自己的基础大模型,也将开源的视野放在了难度更高的视频生成模型上。2月18日,昆仑万维开源其旗下面向AI短剧创作的视频生成模型SkyReels-V1、中国首个SOTA级别基于视频基座模型的表情动作可控算法SkyReels-A1。
其中,SkyReels-V1可实现影视级人物微表情表演生成,支持33种细腻人物表情与400+种自然动作组合,高度还原真人情感表达;另外昆仑万维还开源了SOTA级别的基于视频基座模型的表情动作可控算法SkyReels-A1,SkyReels-A1支持视频驱动的电影级表情捕捉,实现高保真微表情还原。
另外就在2月21日,在“AI大模型六小龙”中一向低调的阶跃星辰在上海举办首届Step UP生态开放日,阶跃星辰创始人、CEO姜大昕在大会上也官宣阶跃星辰将在3月份开源图生视频大模型。
(文:AI前哨站)