
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
今早10点,DeepSeek开启了第四天技术分享,开源了三个优化并行策略。
分别是DualPipe,一种用于 V3/R1 训练中计算与通信重叠的双向流水线并行算法;EPLB,针对 V3/R1 的专家并行负载平衡器;用于分析 V3/R1中的计算-通信重叠。

开源地址:https://github.com/deepseek-ai/DualPipe
https://github.com/deepseek-ai/eplb
https://github.com/deepseek-ai/profile-data
DualPipe是一种创新的双向流水线并行算法,曾首次在V3版本中使用过。与传统的1F1B和ZB1P方法相比,DualPipe大幅减少了流水线气泡,同时仅增加了1倍的激活内存峰值。
DualPipe核心思想是在一个正向和反向传播的块对中重叠计算和通信。每个块被细分为四个部分:注意力机制、全网通信的分发(dispatch)、多层感知机(MLP)以及全网通信的合并(combine)。对于反向传播块,注意力机制和MLP进一步被拆分为输入的反向传播和权重的反向传播两部分。
还有一个流水线通信组件,通过重新排列这些组件,并手动调整GPU流处理器(SM)在通信与计算之间的分配比例,DualPipe能够在执行过程中完全隐藏全网通信和流水线通信。

这种重叠策略不仅适用于计算密集型的场景,即使在通信负担较轻的情况下,DualPipe依然展现出显著的效率优势。
此外,DualPipe采用了双向流水线调度策略,从流水线的两端同时喂入微批次(micro-batch),并通过计算与通信的重叠,确保了在模型进一步扩展时,只要保持恒定的计算与通信比例,就可以在跨节点的情况下使用细粒度的专家,同时实现近乎零的全网通信开销。
为了进一步优化DualPipe的性能,研究者们还开发了高效的跨节点全网通信内核,以充分利用InfiniBand(IB)和NVLink的带宽。通过限制每个token最多只能发送到4个节点,减少了IB的流量,并确保token在到达目标节点后能够通过NVLink快速转发到特定的GPU上,从而实现了IB和NVLink通信的完全重叠。
在内存优化方面,DualPipe通过重新计算RMSNorm和MLA上投影操作来减少内存占用,避免了持续存储这些操作的输出激活值。同时,将模型参数的指数移动平均(EMA)存储在CPU内存中,并在每次训练步骤后异步更新,从而在不增加额外内存或时间开销的情况下保持EMA参数。
在传统的MoE模型中,专家负载的不平衡会导致计算资源的浪费,尤其是在专家并行(EP)的场景下,这种不平衡会进一步加剧通信开销。而EPLB通过动态调整每个专家的负载,确保在训练过程中专家之间的负载保持平衡。

EPLB为每个专家引入了一个偏置项(bias term),这个偏置项被添加到专家的亲和力分数(affinity score)中,用于决定每个token的路由(routing)。在训练过程中,EPLB模块会监控整个批次的专家负载,并根据负载情况动态调整偏置项。如果某个专家的负载过高,偏置项会减少,反之则增加。这种动态调整机制使得模型能够在训练过程中保持专家负载的平衡,同时避免了因强制负载均衡而导致的性能下降。
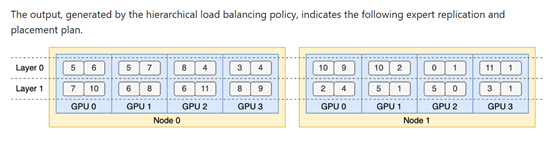
此外,EPLB模块还引入了一个互补的序列级负载均衡损失,以防止在单个序列中出现极端的负载不平衡。这个损失函数的权重被设置为一个非常小的值,以确保它不会对模型的整体性能产生显著影响。
通过这种无辅助损失的负载均衡策略,可帮助模型在训练过程中能够有效地利用计算资源,同时保持模型性能的稳定。
(文:AIGC开放社区)