
DeepSeek在开源周最后一天发布的萤火文件系统 (3FS) ,在2019年幻方的官方博客上有三篇博文详细介绍了其应用场景和设计思路,感兴趣的可以读一下。
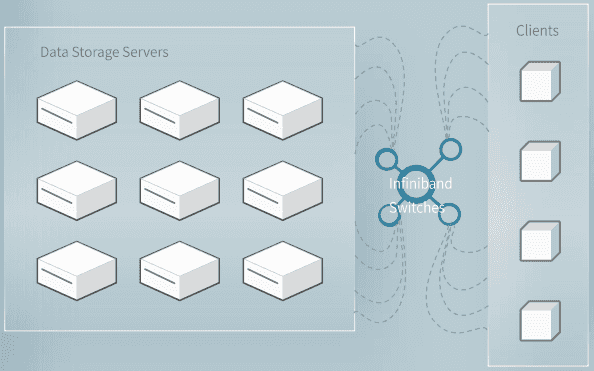
3FS 是一个比较特殊的文件系统,因为它几乎只用在AI训练时计算节点中的模型批量读取样本数据这个场景上,通过高速的计算存储交互加快模型训练。这是一个大规模的随机读取任务,而且读上来的数据不会在短时间内再次被用到,因此我们无法使用“读取缓存”这一最重要的工具来优化文件读取,即使是超前读取也是毫无用武之地。 因此,3FS的实现也和其他文件系统有着比较大的区别。
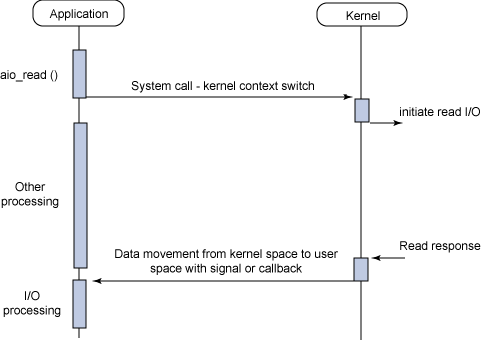
本文介绍了幻方AI在设计3FS文件系统时,针对服务端优化的一些思考。我们采用 Direct IO 和异步对齐的读取方式,让服务端的数据加载更符合模型训练的使用场景,从而获得更好的读取性能。
采用 Direct IO 和 RDMA Read 的读取方式,让服务端的数据通过网卡直接加载到用户态内存中,减少内存带宽的占用,让模型训练在样本读取部分只用极小的CPU和内存开销,就可以获得超高的读取带宽,从而无需再训练过程中等待加载数据,更充分地利用GPU的计算性能。

参考文献:
[1] 幻方力量 | 高速文件系统 3FS:https://www.high-flyer.cn/blog/3fs/
[2] 3FS优化 01 | 服务端优化:https://www.high-flyer.cn/blog/3fs-1/
[3] 3FS优化 02 | 客户端内存使用优化:https://www.high-flyer.cn/blog/3fs-2/
[4] https://github.com/deepseek-ai/3FS
(文:NLP工程化)