

Only OpenAI Can Do
见证历史了,朋友们
根据 OpenAI 的 System Card,GPT4.5 是 OpenAI 迄今为止最大、知识最丰富的模型,比 GPT-4o 更通用,(当然这是奥特曼自己认为的)
实际上,OpenAI 成了 AI 市最大的小丑,而凌晨熬夜看发布会,老老实实体验了几个小时的我是 Joker King。
直接上结论,
一、还没 GPT4 厉害,预训练的计算量是 GPT4 的10倍,基准测试只比 4o 好 5%。主打是安全性高,有人味
二、能联网搜索,支持文件上传与图片分析,还能通过 Canvas 画布辅助写作或编程。不过目前还无法处理语音、视频或屏幕共享。
三、天价API:百万Token输入$$150。价格是 GPT-4o 的15~30倍,是 DeepSeek V3 的136~272倍。
四、优点是比 Cluade3.7 会取名字
奥特曼可太会带货了,
就这还发布了自己的体验:
GPT4.5 像一位有思想的人,这是第一个给我带来这种感受的模型。它能提供有价值的建议,甚至让我几次靠在椅子上,惊叹于 AI 竟然能给出如此精彩的回答。
简单来说就是 GPT4.5 有情商了。按理来说这是一个很主观的评估标准。
一、情商盲测
具体来说,研究人员引入了一套名为“氛围测试”的新评估体系,重点关注对话的情商表现——包括协作性、语气温度等维度。测试结果显示,GPT-4.5在创意写作、情感支持等场景中,能够生成更贴合人类交流习惯的内容。
PS:后续我还会按照基础能力、事实性问答、编程、安全再给GPT4.5小测一波。(抱着订阅费不白花的决心)
所以 OpenAI 创始团队成员 Andrej Karpathy 在GPT4.5 发布之后进行了一项万人实测:
他一共给出了五道题,每道题都有两个选项,分别是 GPT4.5 和 GPT4 生成的回答,回答被匿名为A和B,然后网友们可以投票,选出他们认为更好的回答
我一比一翻译成中文问题后,又生成了一遍,和大家一起过一版盲测:





马上就要公布答案了,快选快选,
三、二、一
大家选出自己喜欢的模型了吗?
英文版结果:
GPT4.5 以 1:4 小败 GPT4,Andrej Karpathy后面不会被OpenAI拉黑吧。。。
中文版的顺序:
-
图1:左(GPT4.5)右(GPT4) -
图2:左(GPT4)右(GPT4.5) -
图3:左(GPT4.5)右(GPT4) -
图4:左(GPT4)右(GPT4.5) -
图5:左(GPT4)右(GPT4.5)
期待大家在评论区发发自己喜欢的顺序,看看在中文上 GPT4.5 是不是还是惜败。
二、偷掺水分的模型指标
虽然主推是情感能力,但是基础能力你也要有吧,一般来说也就是数学、科学、编程、Other。
数学能力
在AIME2024(美国数学邀请赛)里,GPT4.5得分是36.7%,虽然没得跟o3-mini(high)的87.3%比,但是比起GPT4o(9.3%)涨了27.4个点,但又被实锤了暗搓搓降了4o 的分数(-4.1%).
看来不仅是 GPT4.5 不够强,GPT4o 还负优化了。。。
来到数学题热热身吧:

没有推理模型的思考过程还有点怪不习惯的。不过还是蛮可以的,跟之前横向测试 o1、GLM-Zero、Kimi、R1、QWQ 32B 和 Gemini 2.0 Flash Thinking 的效果对比,GPT4.5一次性就答对,结构化输出的过程很“思维链”。
幻觉降低
在 SimpleQA 数据集上,GPT4.5准确率是62.5%,比o1好上个15.5%,幻觉率(越低越好)37.1%,比o1好上6.9%。
发布会询问的例子是“第一种语言是什么”,GPT-4.5会诚实回答不知道,而不是随便回答。
一起看看 o1 和 GPT4.5 的实际对比:(上面是o1、下面是4.5)

代码能力
GPT4.5模型推理速度太慢,API 天价,还不是推理模型。基本上没必要用来当常规编程模型。
API的输出速度也是非常抽象,@赛博禅心测试出来是 6.94 tokens/s,堪称龟速。
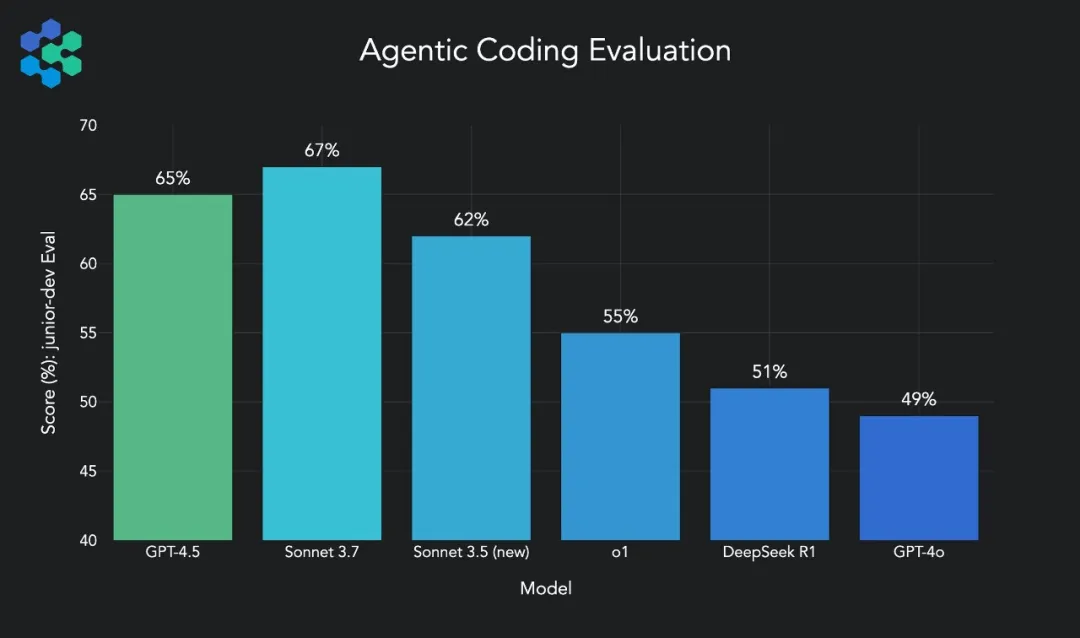
不过还是简单跑跑物理小球案例:
再看看其他四个模型:
不出意料,Claude3.7 还是强,还有推理模式,我都想不出理由不选它。
安全能力
之前不是还提到除了人情味儿,GPT4.5的安全能力还是相当出色的。
在禁止内容测试里,GPT4.5,跟GPT4o和o1在标准拒绝评估和挑战性拒绝评估中表现相当,但在 WildChat(人与AI的抽象对话)和 XSTest(容易引起误解的话)评估中表现略好。
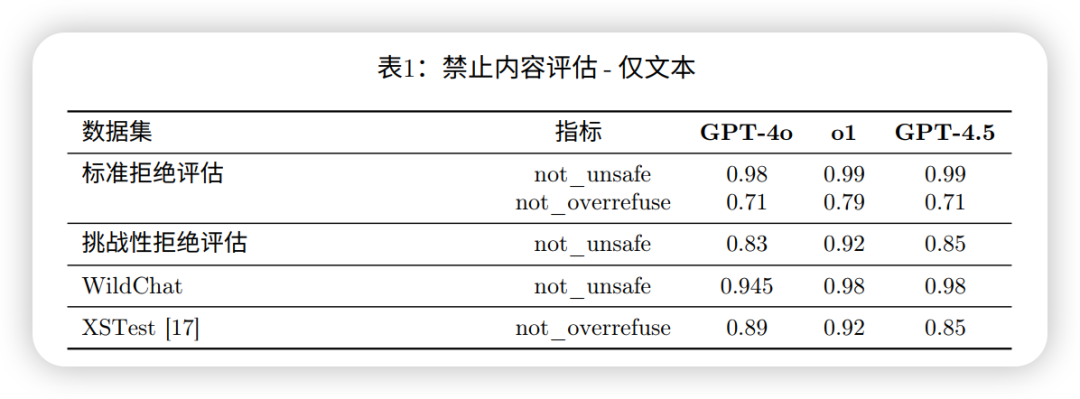
在安全指令测试中,

不过这一点的话,普通用户在使用过程中体感可能不是非常明显。
写在最后
发布会连直播评论都不敢开是有多心虚……
从某个角度看,可能整个地球上的预训练模型天花板就是这个了。
我也会不禁产生疑问:
GPT4.5会不会就是难产的GPT5?
AI 长期依赖的Scaling Law(规模定律),正在走向终点吗?
或许大家心中已经有了答案。
即使靠着“激进”使用了低精度训练,预训练阶段跨多个数据中心完成,维持了GPT4.5的诞生,
也无法避免的让它成为了AI史上最昂贵的过渡品。
但换个角度,GPT4.5的平庸也许会成为破晓前的启明星,
既宣告着过去几代模型的一生,
也昭示着后训练和推理模型时代的黎明。
所以,下一次的突破,
我们还要等到GPT-5 吗?
@ 作者 / 卡尔 & 阿汤 @ 动手学AI知识库 / learnprompt.pro
(文:卡尔的AI沃茨)