



代码链接:

简介
当前,序列推荐系统(Sequential Recommender Systems, SRS)广泛应用于电子商务和短视频平台等场景。然而,现有的 SRS 中存在着严重的长尾问题。长尾问题在推荐系统中指大量低流行度(长尾)物品难以被有效推荐的现象,导致用户惊喜度降低、卖家利润减少和系统整体受损。
这种现象主要体现在两个方面:首先,用户难以发现新的、有价值的物品,推荐体验变得单一,无法满足个性化需求;其次,低流行度物品销售量低,卖家收益受损,甚至可能被迫下架,影响整个市场的多样性。
此外,长尾问题还会导致系统整体受损,用户满意度下降,卖家流失,最终影响整个推荐系统的价值。如图(a)所示,柱状图显示了大部分物品的交互频率都很低,呈现明显的长尾分布,但是常用的 SRS 模型 SASRec 对于这些物品的推荐效果较差。
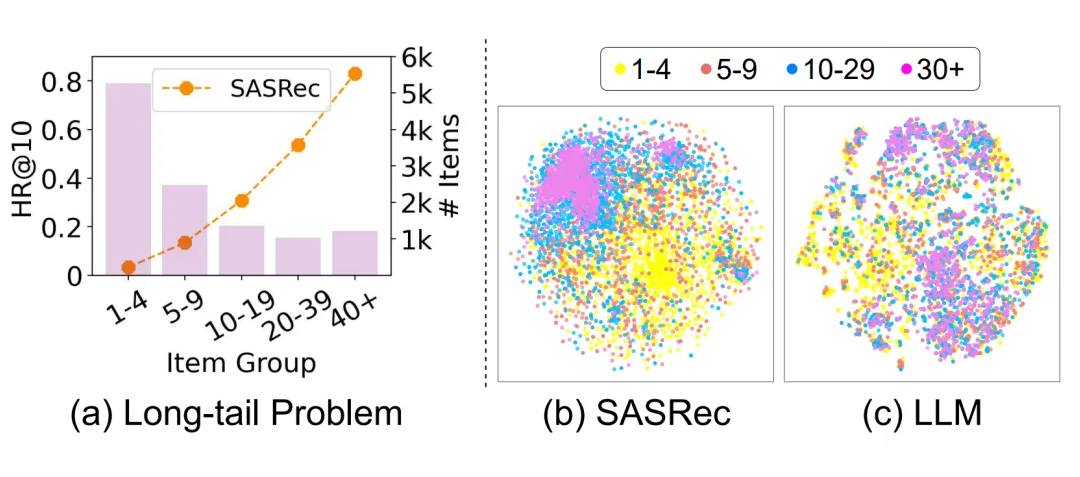
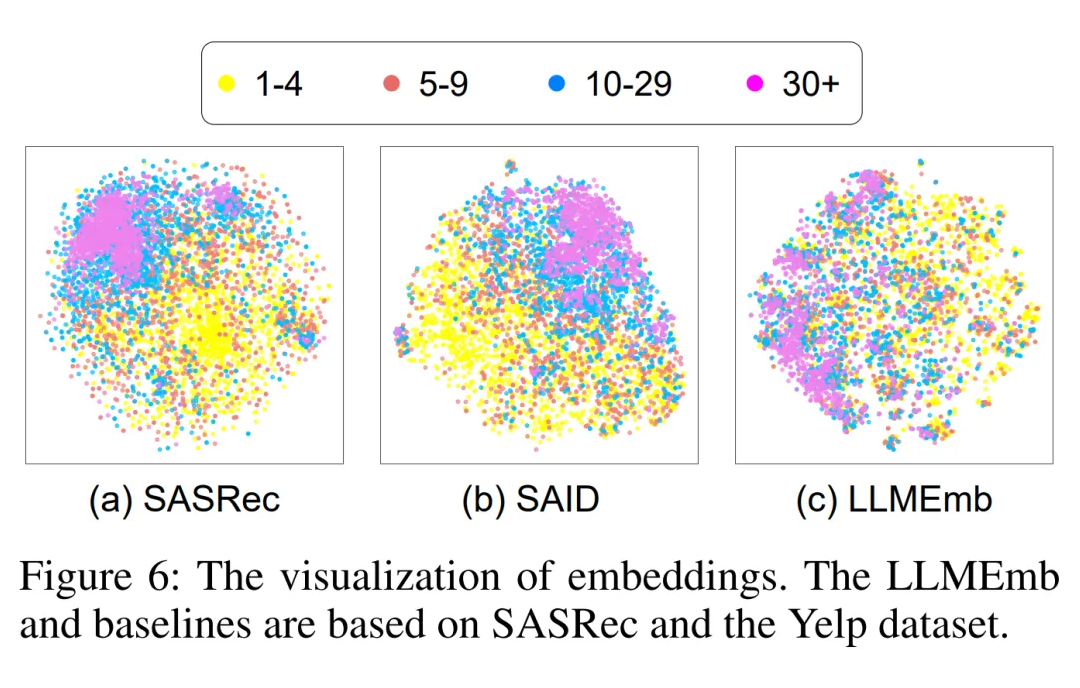
我们发现 SRS 的长尾问题是由其有偏的物品嵌入分布造成的。如图(b)所示,SASRec 中低流行度物品的嵌入点分布稀疏且距离较远,说明其嵌入质量较差。
相比之下,大语言模型(LLM)通过文本特征(如标题)捕捉物品之间语义关系,有希望成为一个无偏的物品嵌入生成器。图(c)显示了 LLaMA 生成的物品嵌入的分布,这些嵌入点更均匀地分布,这促使我们开发一个基于 LLM 的生成器来生成更高质量的嵌入。
然而,现有的基于 LLM 的 SRS 方法存在两个主要挑战:
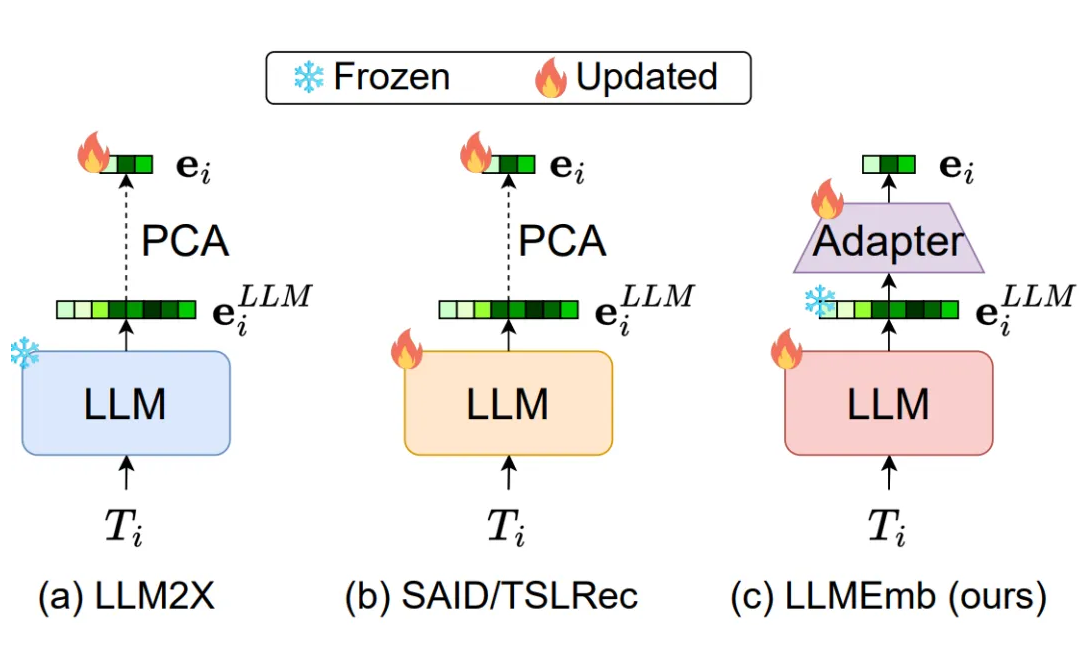
(i)语义差距:LLM2X 采用通用的 LLM 来生成物品嵌入。虽然这些嵌入可以包含语义,但它们并不针对推荐领域。为了解决这个问题,像 SAID 和 TSLRec 这样的方法提出微调开源 LLM,以更好地与推荐任务对齐。然而,这些方法仍然局限于语言建模或类别预测,忽视了推荐领域中用属性区分物品的关键作用。
(ii)语义损失:如图所示,为了将 LLM 嵌入进一步适配协同过滤 SRS 模型,现有方法通过 PCA 等方法进行降维,并降维的嵌入直接使用到 SRS 模型中。然而,大幅度的降维和持续的训练会导致 LLM 嵌入中原始语义丰富性的显著损失,从而限制了它们的有效性,尤其是对于长尾物品。

方法
2.1 Overview
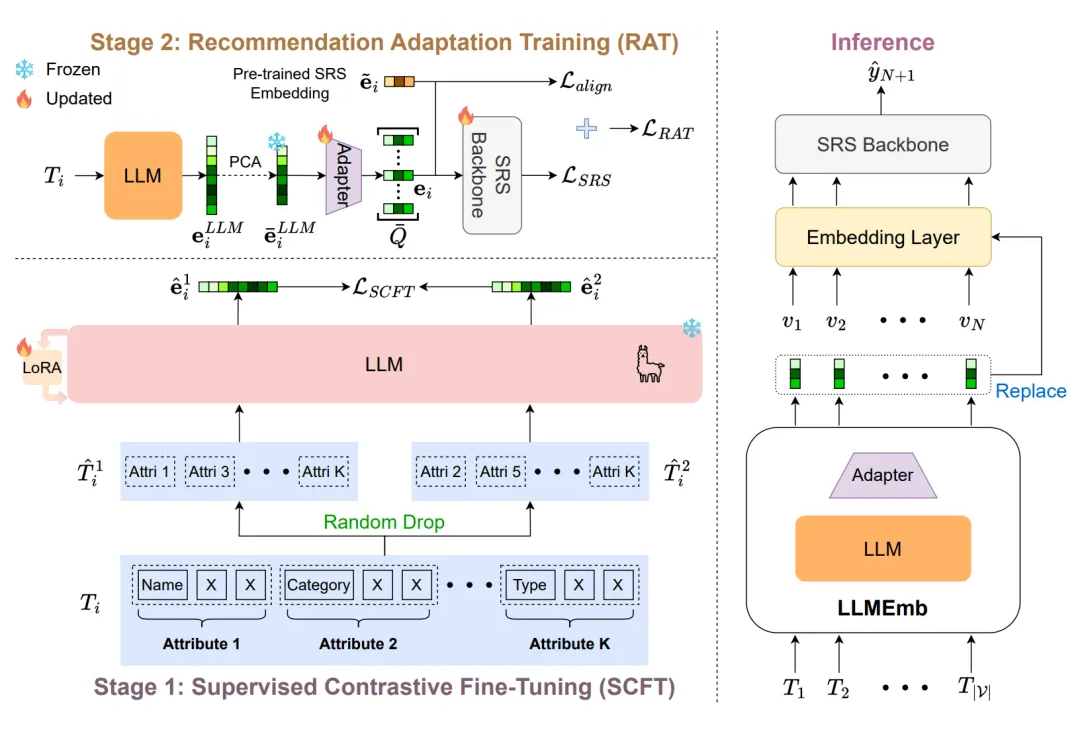
图中展示了我们提出的 LLMEmb 的训练和推理过程,该嵌入生成器由一个 LLM 和一个适配器组成。
对于训练过程,设计了两个阶段分别对 LLM 和适配器进行训练。第一阶段称为监督对比微调(SCFT),目标是微调通用 LLM,以提高其根据不同属性区分物品的能力。具体来说,一个物品的文本提示由其属性组成,通过随机删除一定比例的属性将其增强为成两个副本。
然后,通过对比不同物品的嵌入来微调 LLM。微调过后的 LLM 能够生成更适合推荐任务的 LLM 嵌入,包含物品的语义信息。第二阶段称为推荐适应训练(RAT),涉及训练一个适配器,将 LLM 嵌入转换为最终的物品嵌入,使其适合推荐模型。
最后,这些物品嵌入被输入到 SRS 模型中,并通用的推荐损失函数进行训练。在推理阶段,LLMEmb 将提前生成所有物品嵌入。这些预先计算好的嵌入将替换 SRS 模型的原始嵌入层,从而避免了推理过程中 LLM 带来的巨大推理开销。
2.2 SCFT
SCFT 主要通过对比微调 LLM,使其具有通过识别属性的语义来区分物品的能力。该过程主要包含三个关键的步骤:Prompt 构建、数据增强和对微调
Prompt 构建:我们将物品的每一个属性都使用文本形式表示,比如 “Attribute is value”。我们将这一段文本作为一个 meta prompt,那么每个物品的 prompt 就是由这样的多个 meta prompt 构成的。
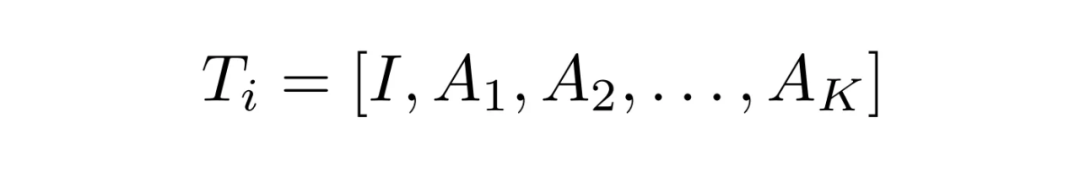

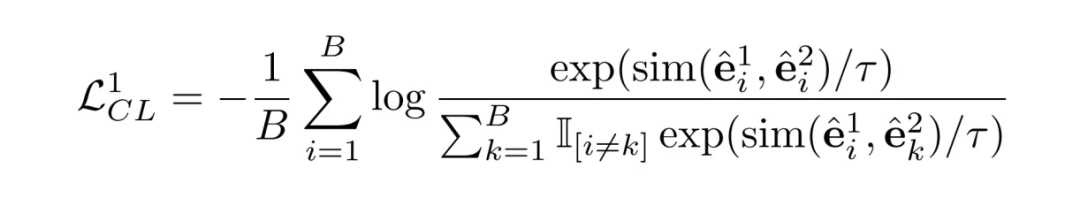
2.3 RAT
推荐适配训练 RAT 的目的是使 LLM 生成的物品表征能够学习到推荐的协同过滤信号。其次,由于 LLM 嵌入的维度过大,也需要将其转换适合 SRS 维度的嵌入。因此 RAT 包含了三个步骤:嵌入转换、适配训练和协同对齐。
嵌入转换:之前的方法通常直接使用 PCA 对 LLM 嵌入进行降维,但是这一做法会显式损害原本 LLM 嵌入中含有的语义信息。因此本文提出使用一个可微调的转换器,将 LLM 嵌入转换为最终的物品嵌入。
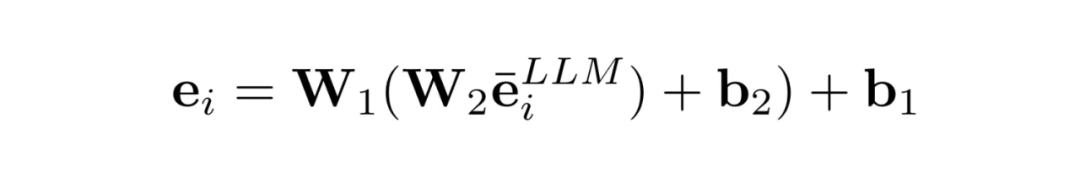
适配微调:这一步为了将协同过滤信号注入到生成的嵌入当中,使用正常的SRS损失函数对适配器进行进一步的训练。
协同对齐:由于在适配微调中只有一小部分的参数是可训练的,容易造成过拟合的问题。因此提出将生成的物品嵌入与一般的 SRS 嵌入进行对齐,缓解训练上的困难。
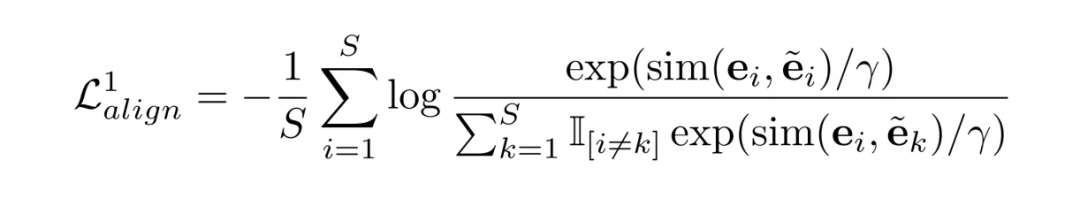

实验
3.1 实验设置
我们在实验中使用了数据集 Yelp,Beauty 和 Fashion 数据集。

为了验证方法的通用性,我们结合了三个常用的 SRS 模型进行实验:GRU4Rec,SASRec 和 Bert4Rec 此外,我们广泛地对了长尾序列推荐和基于 LLM 的序列推荐模型:MELT, LLM2X, SAID 和 TSLRec。
3.2 整体实验结果
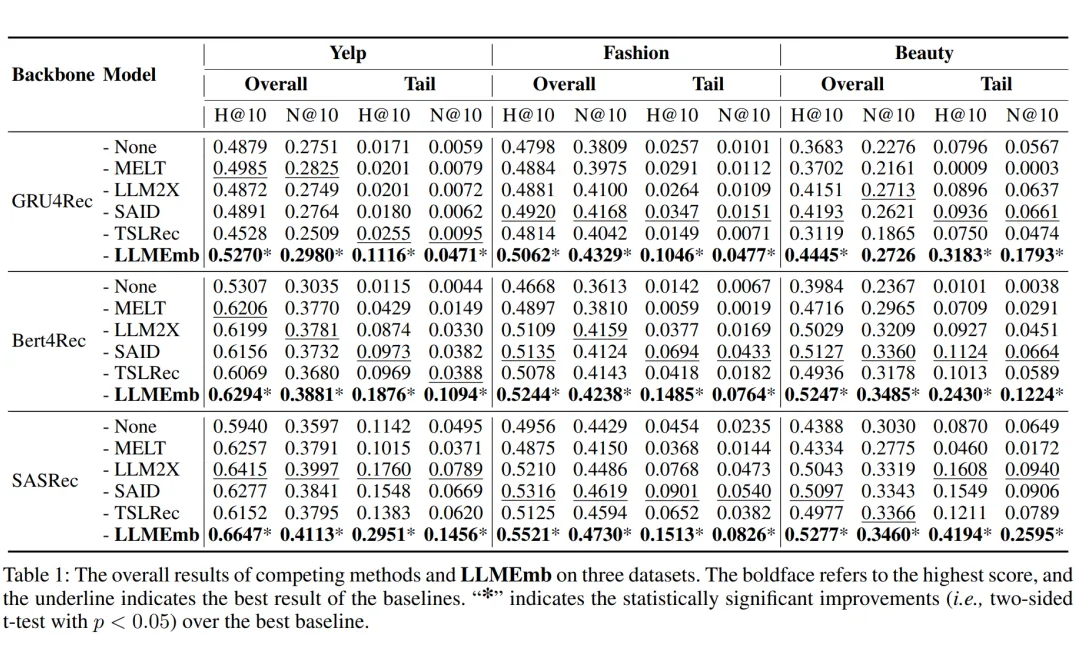
LMEmb 在三个数据集上的整体和长尾性能均优于所有竞争者,尤其是在长尾物品上表现突出。TSLRec 通常表现不佳,因为它在使用 LLM 时仅采用物品 ID 而不是文本信息。
尽管 SAID 和 LLM2X 也能为所有 SRS 模型带来提升,但它们仍然逊色于 LLMEmb,尤其是在长尾物品上。这种比较表明,LLMEmb 可以更好地保持原始 LLM 嵌入中的语义关系。
3.3 消融实验
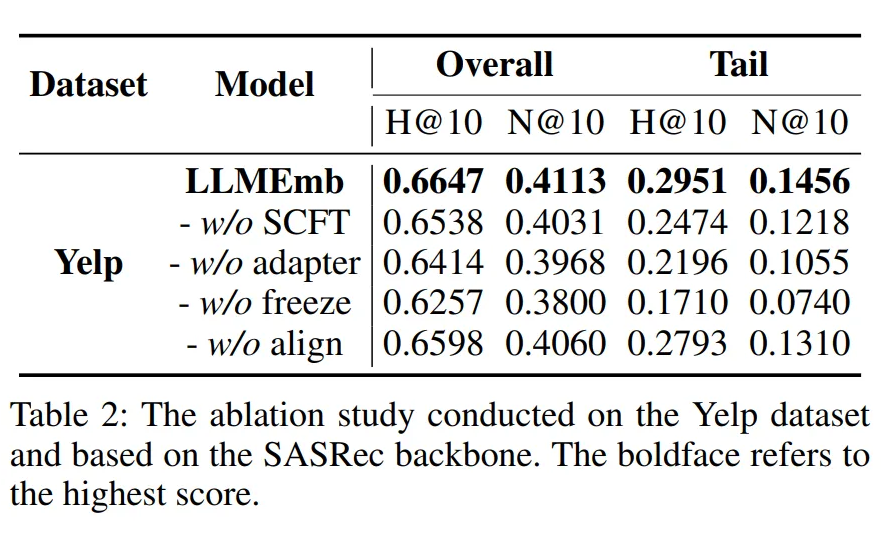
消融实验验证了 LLMEmb 各个设计模块的有效性:未进行微调的 LLM 生成的嵌入性能较差,证明了弥补通用 LLM 与推荐任务之间语义差距的必要性。移除可训练的 Adapter 后性能下降,表明 Adapter 在转换 LLM 嵌入维度方面的有效性。移除协同对齐损失后性能下降,证明了协同对齐在优化过程中的有效性。
3.4 嵌入可视化

总结
LLMEmb 是一种新颖的基于 LLM 的生成器,用于为序列推荐生成物品嵌入。为了使 LLM 具备识别物品的能力,我们设计了一种监督对比微调方法。然后,为了避免语义损失并注入协同信号,我们提出了推荐适应训练来更新可训练的 Adapter。最后,训练好的 LLM 和 Adapter 构成了 LLMEmb,可以生成最终的物品嵌入。
我们在三个真实世界数据集上进行了实验,并验证了 LLMEmb 的有效性。
(文:PaperWeekly)