
在AI领域,OpenAI 一直是霸主,但现在,一个中国AI公司 DeepSeek 站了出来,不仅推出了全新的强大推理模型 DeepSeek-R1,还直接免费开放给所有人使用!没错,完全免费,无门槛,人人都能玩!这是不是有点炸裂?
更狠的是,DeepSeek 还推出了精简版蒸馏模型,这意味着即使你的设备性能一般,也能享受到顶级AI的推理能力。不管你是AI开发者、研究员,还是想要尝试训练自己的专属AI,现在都可以轻松入门!
今天,我们就来带你一步步玩转 DeepSeek-R1,不仅介绍它的牛逼之处,还手把手教你如何在 医疗推理数据集 上进行 微调(Fine-Tuning),让AI为你所用!💡

DeepSeek-R1 到底有多强?
DeepSeek 这次放出的 DeepSeek-R1 和 DeepSeek-R1-Zero 直接对标 OpenAI o1 模型,在数学、编程、逻辑推理等任务上表现惊人,甚至部分场景下能直接对飙 OpenAI!
🔹 DeepSeek-R1-Zero:靠强化学习(RLHF)从零开始训练,自己摸索推理方式,虽然有点聪明过头容易啰嗦,但思维路径极其清晰,适合需要深度推理的任务。
🔹 DeepSeek-R1:在 Zero 的基础上增加了冷启动数据,补足了前者的短板,使得输出更具可读性,适合广泛应用。
简单来说,DeepSeek-R1 既聪明又能说人话,逻辑推理能力强,还不乱输出废话。
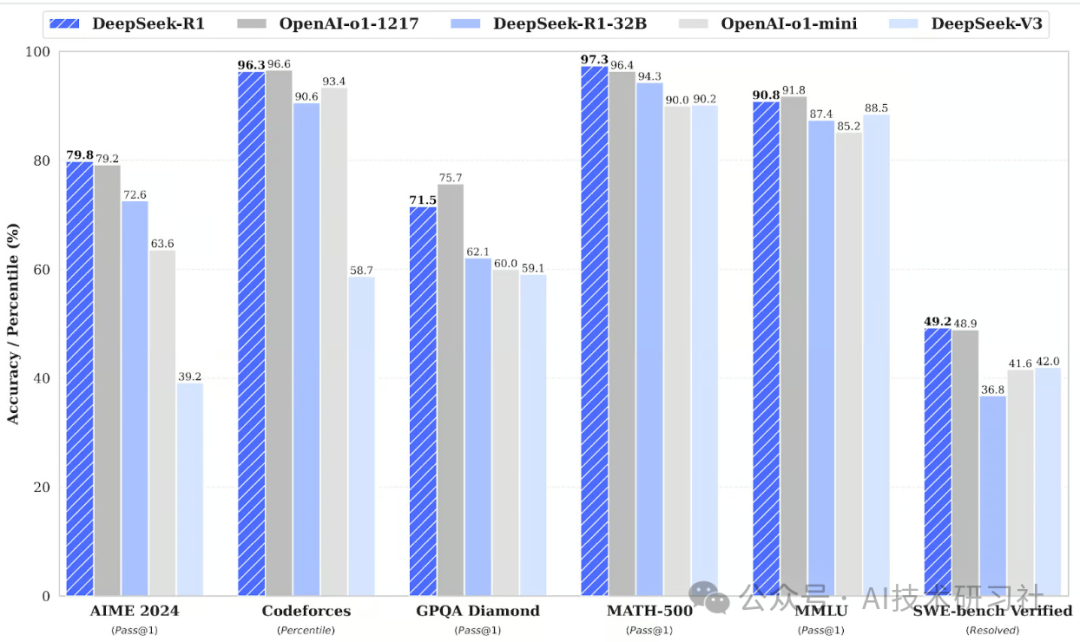
当然,除了这些大型模型,DeepSeek 还贴心地推出了 蒸馏版(Distill) 模型,比如 DeepSeek-R1-Distill-Qwen-32B,不仅性能不输 OpenAI o1-mini,而且运行效率更高,适合部署到本地或小型服务器。
那么问题来了,这么强的AI,我们能不能让它变得更懂我们?答案是:可以!微调(Fine-Tuning)就是关键!
手把手教你微调 DeepSeek-R1
既然 DeepSeek-R1 这么猛,我们当然想让它更懂我们的需求,比如医疗领域、金融领域,甚至某些超具体的任务。今天,我们就用一个 医疗推理数据集 来教大家如何微调 DeepSeek-R1-Distill-Llama-8B。
第一步:环境配置
既然要微调,首先你得有个好用的开发环境。这里我们推荐 Kaggle,因为它提供免费的 GPU 资源,比 Google Colab 还要香!
1️⃣ 在 Kaggle 创建一个新的 notebook。
2️⃣ 在 Add-ons 选项卡里,选择 Secrets,添加你的 Hugging Face 和 Weights & Biases 令牌。
3️⃣ 安装 Unsloth(一个能让 LLM 训练效率翻倍的库):
pip install unslothpip install --force-reinstall --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.git4️⃣ 登录 Hugging Face API 和 Weights & Biases 以便后续训练监控。
from huggingface_hub import loginfrom kaggle_secrets import UserSecretsClientuser_secrets = UserSecretsClient()hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")login(hf_token)第二步:加载模型
我们用的是 DeepSeek-R1-Distill-Llama-8B,而且会加载 4-bit 量化 版本,以减少显存占用,让训练更顺畅。
from unsloth import FastLanguageModeltokenizer = FastLanguageModel.from_pretrained(model_name="unsloth/DeepSeek-R1-Distill-Llama-8B",max_seq_length=2048,load_in_4bit=True,token=hf_token,)第三步:看看原始模型表现
在微调之前,先让模型来回答一个医学问题,看看效果如何。
question = "61 岁女性,长期在咳嗽或打喷嚏时不自主漏尿,但夜间无问题。做了妇科检查和 Q-tip 测试,膀胱测压检查可能会发现什么?"prompt = """### Instruction:你是一名医疗专家,擅长临床推理和诊断,请回答以下问题。### Question:{}### Response:""".format(question)inputs = tokenizer([prompt], return_tensors="pt").to("cuda")outputs = model.generate(input_ids=inputs.input_ids, max_new_tokens=1200)response = tokenizer.batch_decode(outputs)print(response[0])模型会给出一个相对合理的医学推理,但可能啰嗦、格式混乱,因此我们需要微调它,让它更符合我们的预期。
第四步:准备训练数据
我们选用 Hugging Face 上的医疗推理数据集,并对格式进行处理,让它符合模型的训练需求。
from datasets import load_datasetdataset = load_dataset("FreedomIntelligence/medical-o1-reasoning-SFT", "en", split="train[0:500]")def format_data(examples):text = f"### Question:\n{examples['Question']}\n\n### Response:\n{examples['Response']}"return {"text": text}dataset = dataset.map(format_data)第五步:微调模型
现在,我们开始对模型进行 LoRA 适配,并设置训练参数。
model = FastLanguageModel.get_peft_model(model, r=16, target_modules=["q_proj", "k_proj", "v_proj", "o_proj"],lora_alpha=16, lora_dropout=0, use_gradient_checkpointing="unsloth")然后,开始训练!
from transformers import TrainingArguments, Trainertraining_args = TrainingArguments(output_dir="./results", per_device_train_batch_size=2, num_train_epochs=3,save_strategy="epoch", logging_dir="./logs")trainer = Trainer(model=model, args=training_args, train_dataset=dataset)trainer.train()训练结束后,你的 DeepSeek-R1-Distill 模型就会变得更聪明、更贴合你的任务需求啦!
DeepSeek-R1模型的发布引发了全球AI领域的广泛关注。这款开源模型在推理能力上与OpenAI的o1模型相当,且完全免费开放,体现了AI技术的民主化趋势。其创新架构和训练策略使其在性能和成本上实现了突破,显著降低了AI应用的门槛。
微调技术(Fine-Tuning)使得AI模型能够更好地理解特定任务需求,开发者可以利用Kaggle平台提供的免费GPU资源进行模型的微调训练,即使是初学者也能轻松上手。
掌握了这些方法,您就能打造属于自己的高性能AI助手。
赶紧去试试吧!
您还想了解哪些AI玩法?请在评论中告诉我们!
(文:AI技术研习社)