

极市导读
在 DeepSeek 生成的文本中,有 74.2% 的文本在风格上与 OpenAI 模型具有惊人的相似性?这是一项新研究得出的结论。 >>加入极市CV技术交流群,走在计算机视觉的最前沿





-
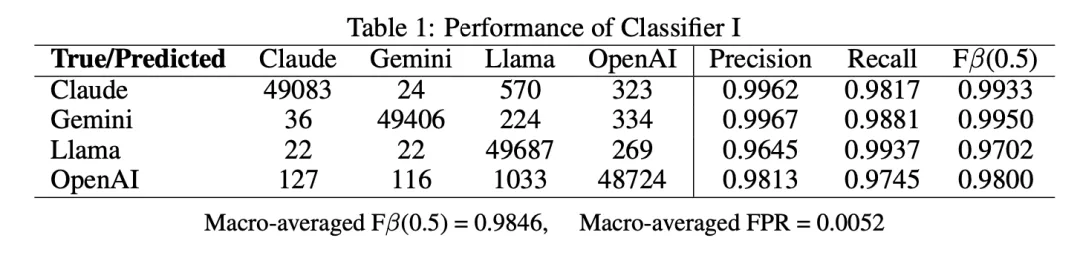
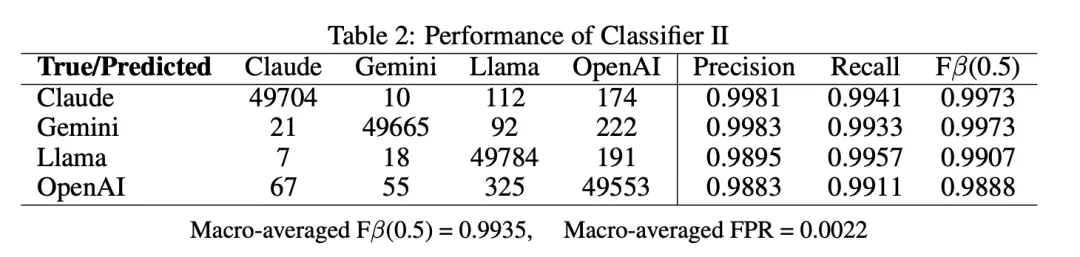
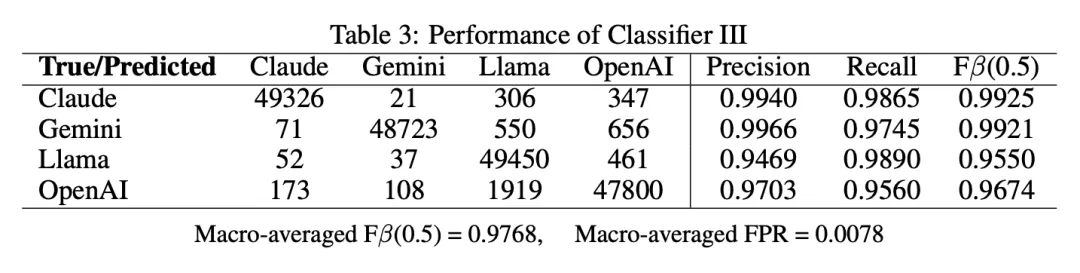
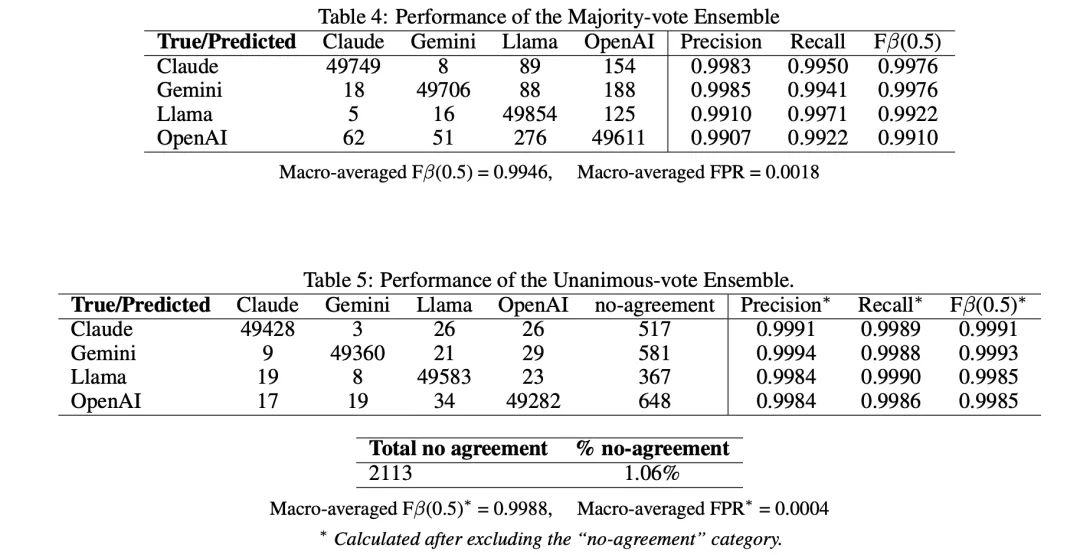
混淆矩阵
-
精确率和召回率
-
F 值
-
总体假阳性率 (FPR)
-
宏平均 F 值 (β=0.5)
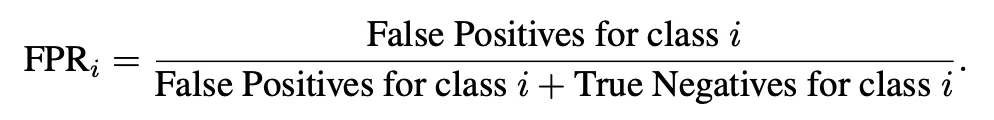
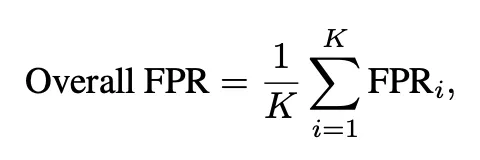


(文:极市干货)
极市导读
在 DeepSeek 生成的文本中,有 74.2% 的文本在风格上与 OpenAI 模型具有惊人的相似性?这是一项新研究得出的结论。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
混淆矩阵
精确率和召回率
F 值
总体假阳性率 (FPR)
宏平均 F 值 (β=0.5)
(文:极市干货)