

邮箱|yokyliu@pingwest.com
3月6日,中国大模型领域同时发生了两个上热搜的AI话题:
一边是AI Agent产品Manus,另一边则是阿里巴巴全新开源的通义千问QwQ-32B模型。
前者引发的讨论中,不少人把它称为DeepSeek级别的“炸裂”成果,并称“硅谷因它一夜无眠”。不过有趣的是,在国际AI社区中,真正引起广泛讨论的其实是后者。
凌晨正式发布模型后,QwQ-32B当天即登顶HuggingFace的开源模型榜单。
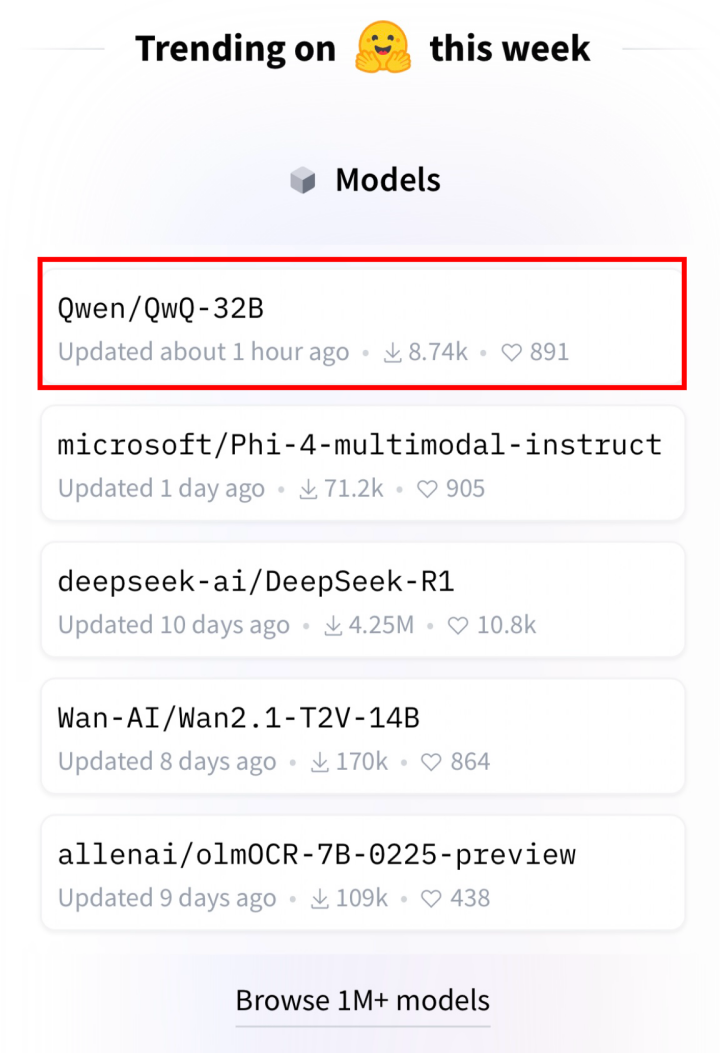
这款模型以32B的相对精简参数规模,却实现了与目前最强开源模型DeepSeek-R1相匹敌的性能,击败了老对手OpenAI o1 mini。
这对于开源社区的开发者吸引力巨大。HuggingFace联合创始人Vaibhav Srivastav几乎成了Qwen系列的忠实粉丝,每次发布都不缺席,成了点赞专业户。

甚至有人开始玩起了新梗,当遇上OpenAI和QwQ 32B的分岔路口,向左还是向右?

“性能惊人,尺寸小能量大,运行快。”Reddit的讨论开始还真有点“炸裂体”的味。
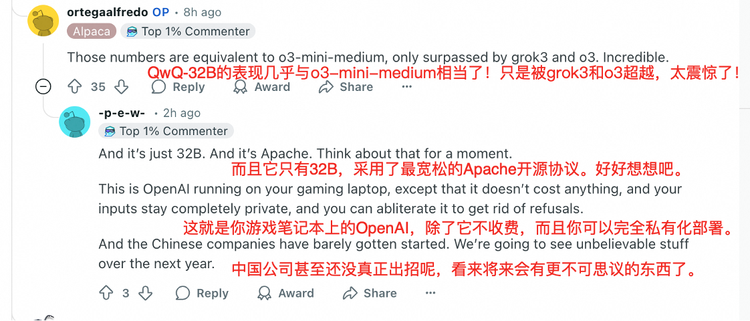
还有开发者开始像分享对一款现象级消费产品的评测一样,分享调用它的最佳设置。

以及,那个每次必不可少的,一直以来的疑问:

所以到底怎么发音?
32B参数,以小搏大,重构游戏规则
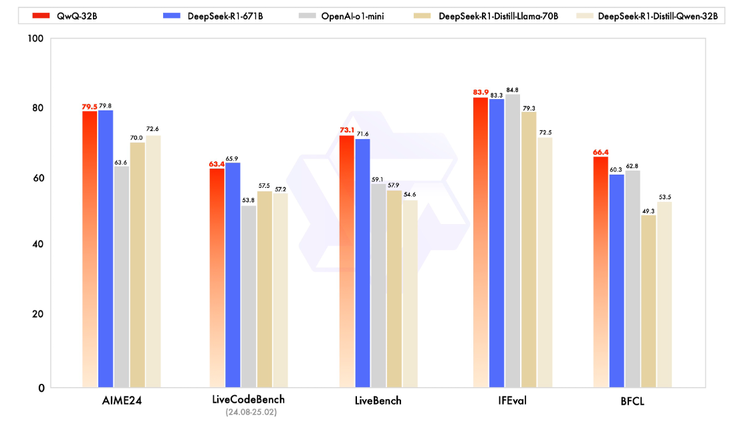
根据官方报告,在一系列权威基准测试中,千问QwQ-32B 模型表现异常出色,几乎完全超越了OpenAI-o1-mini,比肩最强开源推理模型DeepSeek-R1:
在测试数学能力的AIME24评测集上,以及评估代码能力的LiveCodeBench中,千问QwQ-32B表现与DeepSeek-R1相当,远胜于o1-mini及相同尺寸的R1蒸馏模型;在由Meta首席科学家杨立昆领衔的“最难LLMs评测榜”LiveBench、谷歌等提出的指令遵循能力IFEval评测集、由加州大学伯克利分校等提出的评估准确调用函数或工具方面的BFCL测试中,千问QwQ-32B的得分均超越了DeepSeek- R1。
这些只是最基础的能力展示。而更多的热议来自开发者自己的需求和体验。
最让开发者感到兴奋的是,当参数变小但性能不变时,一台消费级显卡的硬件上,就能完成部署!
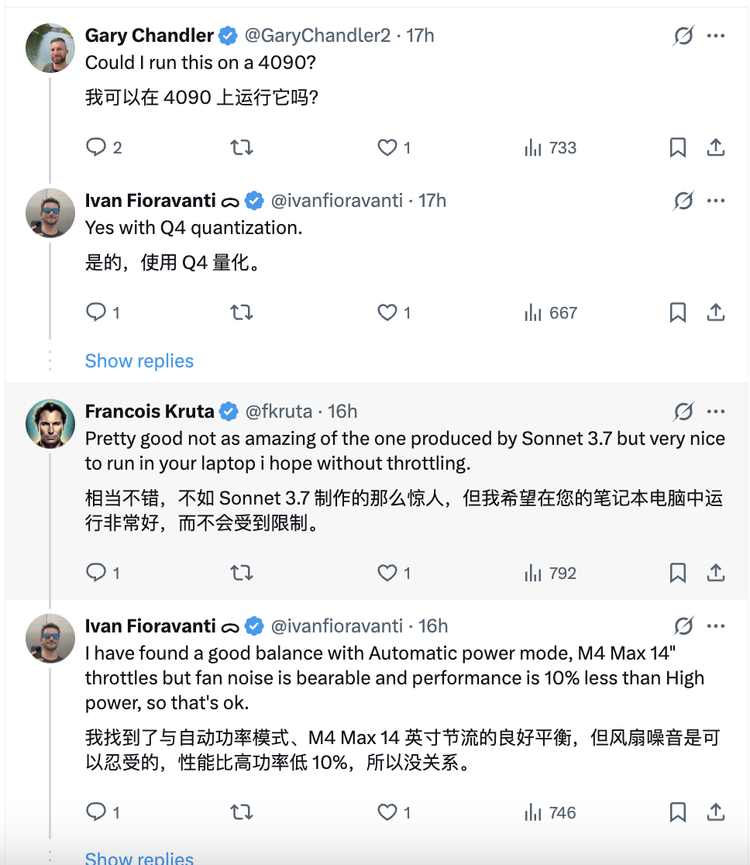
苹果的ML工程师Awni Hannun也第一时间体验了模型,他发文展示了QwQ-32B在配备MLX(专门为苹果芯片设计的开源框架)的M4 Max芯片电脑上的运行速度很快,并公开了它的一些思考片段。
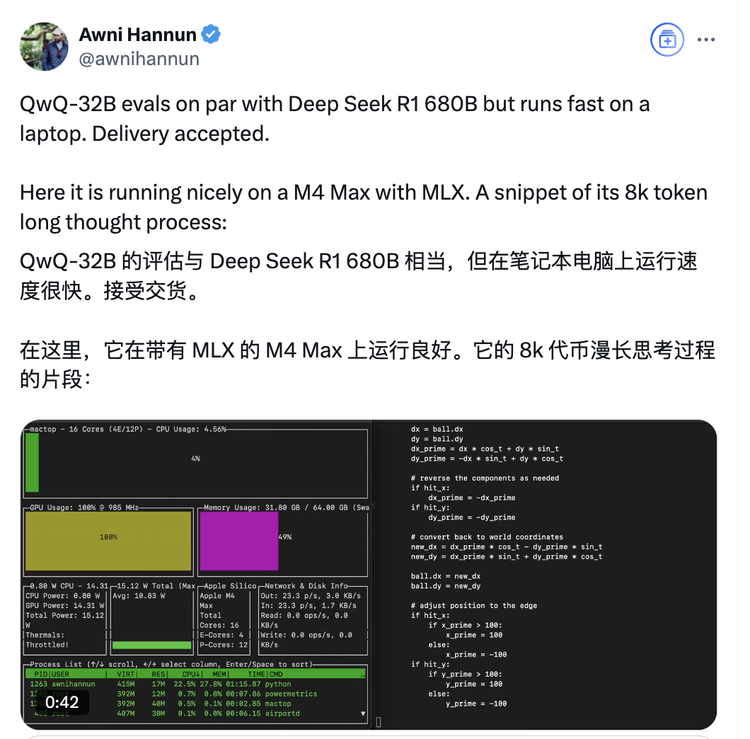
多位开发者实测证实,QwQ-32B可在MacBook M系列芯片设备上流畅运行,其量化版本(q4_K_M)甚至在仅有16GB内存的设备上实现了每秒40 token的推理速度。这一表现远超同规模模型的部署要求,大幅降低了硬件门槛。

经过开发者测算,QwQ-32B对比DeepSeek-R1的671B参数,显存需求从1500GB降至24GB VRAM,“小参数+强优化”路径,验证了中等规模模型突破性能瓶颈的可能性。
在性能方面,QwQ 32B延续了强化学习提高模型性能的路径,在冷启动基础上,阿里通义团队针对数学和编程任务、通用能力分别进行了两轮大规模强化学习,在32B的模型尺寸上获得了令人惊喜的推理能力提升,在一系列权威基准测试中,几乎超越了o1 mini,比肩DeepSeek R1,尤其在数学和代码能力方面,远胜于同尺寸的推理模型。

Reddit用户为了进一步验证QwQ的推理能力,为QwQ32B设置了一道物理原理推导任务,能够完整演示从牛顿定律到最小作用量原理的数学推导过程,该用户调侃的说2026应该不会为ChatGPT Pro付费了。

Anthropic的投资机构Menlo Venture的投资人,也第一时间密切关注,对比了QwQ-32B和DeepSeek R1的推理成本,发现前者仅为后者的1/10的token成本,但效果能够达到DeepSeek-R1与o3-mini之间的性能水平。

目前,阿里已采用宽松的Apache2.0协议,将千问QwQ-32B模型向全球开源,所有人都可免费下载及商用。
此前企业部署顶级AI模型通常需要投入大量资金购置高端GPU集群,并面临复杂的分布式部署挑战和持续的电力成本压力,这意味着,企业不再需要构建复杂的GPU集群和高带宽网络来支持模型运行,能够在更低的算力环境下部署推理模型,避免大参数模型所需要的并行通信开销,同时单机部署也能够大幅降低运维门槛,使得中小企业也能负担得起高性能AI模型的落地应用。
同时,用户也将可通过通义APP免费体验最新的千问QwQ-32B模型。
Qwen成了硅谷最爱的开源基座
除了QwQ-32B模型本身,一个围绕着Qwen的开源生态,也在渐渐成型。
在发布模型的过程中,Qwen的负责人林俊旸不停转发各种主流开源工具对QwQ的快速适配,除了发布模型本身,他似乎更着力于邀请大家通过不同的工具对QwQ-32B进行体验和二次开发。

另一位Qwen的核心团队成员Hui binyuan特意提到,欢迎大家在Qwen的基础上开发更有意思的东西。

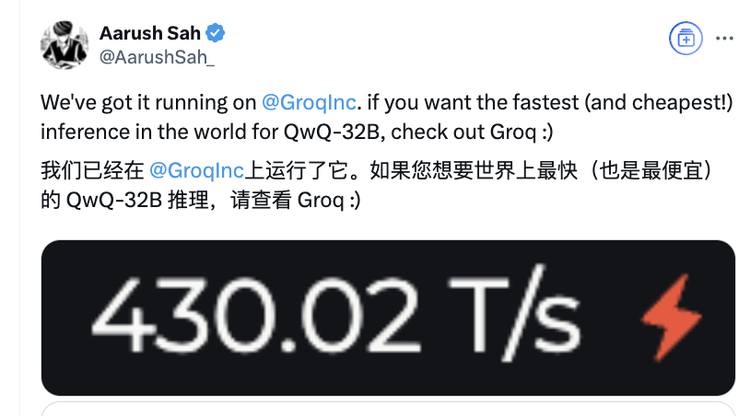
在一众快速适配QwQ的厂商中,一个有意思的案例来源于Groq。
它在QwQ-32B发布的第一时间即完成GroqCloud部署,实现400 token/s推理速度。得益于Groq LPU架构的确定性执行特性,与QwQ-32B的密集模型设计形成互补,并以每百万输入代币 0.29 美元,每百万输出代币 0.39 美元的超低价格提供服务。

这家硅谷明星的AI Infra公司,号称要做到“最快的推理平台”,目前已经吸引了百万开发者,平台已经渐渐与开源模型包括LLma、DeepSeek、Qwen模型系列深度绑定。
而且,它是一个拥有自己芯片产品的公司。Groq 创始人是谷歌专用芯片NPU 发明者之一Jonathan Ross。它创办的Groq,设计了与GPU不同的LPU (语言处理单元),专为AI推理所设计的新型端到端处理单元系统,借助这种自己掌握的软硬件结合优势,它提供的模型的部署服务总是最快的之一。
因此它的很多动作基本成为了开源的重要风向标之一,哪个模型上了Groq,意味着开发者对它的需求够高,而它提供的极速的体验,又会帮助这些模型让更多人了解其性能。这是一个开源和语言模型上下游生态的典型正向循环机制。
在不到两年的时间里,Qwen正在成为向往开放开源的模型世界的开发者的首选之一。目前,海内外开源社区中Qwen的衍生模型数量已突破10万,超越Llama系列衍生模型,通义千问Qwen稳居世界最大的生成式语言模型族群。根据Huggingface2025年2月10日最新的全球开源大模型榜单,排名前十的开源大模型全部是基于通义千问Qwen开源模型二次开发的衍生模型。
同时,越来越多的学术界知名研究机构和学者,基于Qwen系列模型展开研究。李飞飞等斯坦福大学和华盛顿大学研究人员基于阿里通义千问Qwen2.5-32B-Instruct开源模型为底座,仅使用16块H100 GPU,通过26分钟的监督微调,便打造出了性能卓越比肩OpenAI的o1和DeepSeek的R1等尖端推理模型的s1-32B模型。
近期,伯克利的计算实验室在QwQ-preview的基础上,花费了450美元创建了数据集,训练出了o1级的自有推理模型。

据统计,从2023年至今,阿里通义团队已开源200多款模型,包含大语言模型千问Qwen及视觉生成模型万相Wan等两大基模系列,开源囊括文本生成模型、视觉理解/生成模型、语音理解/生成模型、文生图及视频模型等「全模态」,覆盖从0.5B到110B等参数「全尺寸」,并在多个榜单中斩获冠军。
最近阿里巴巴连续开源了多个模型,每一个都会在海外社区引发广泛关注,有开发者感慨并剧透到,QwQ-32B是其中一个,而它可能还不是Qwen系列此轮会发布的最强的那个。
通义的大招也许还在后面。


(文:硅星人Pro)