
今天是2025年3月7日,星期五,北京,天气阴。
今天,我们来看AI内容的影响面及R1复现基座的一些解释,并看看多模态语音大模型进行R1的尝试。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、AI内容的影响面及R1复现基座的一些解释
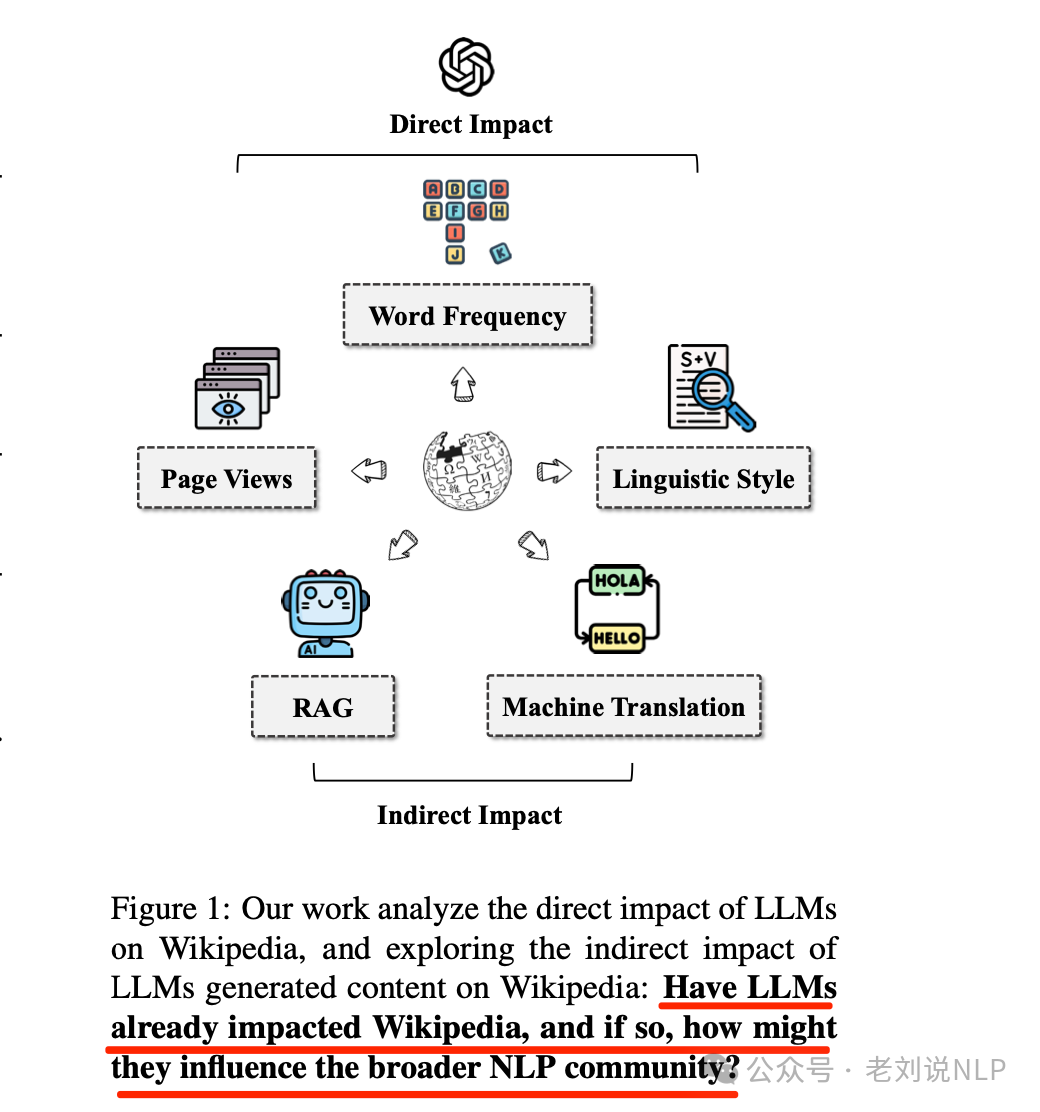
1、AI内容对wikipedia的影响面
看到一个工作,Wikipedia in the Era of LLMs: Evolution and Risks,https://arxiv.org/pdf/2503.02879,评估了LLM如何影响与维基百科相关的各种自然语言处理(NLP)任务,包括机器翻译和检索增强生成(RAG),研究结果和模拟结果表明,维基百科的文章受到了LLM的影响,在某些类别中的影响约为1%-2%。
2、关于R1复现基座的一些解释
deepseek r1发布后,复现过程中很多人发现某些模型(基本都是qwen系列)能够在强化学习(RL)训练中显著提升性能,而有些很难(如Llama系列), 《Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs》,https://arxiv.org/pdf/2503.01307,https://github.com/kanishkg/cognitive-behaviors,分析了原因。
其认为有几种能力:验证能力(系统性检查错误);回溯能力(在检测到错误时明确修订方法);子目标设定能力:(将复杂问题分解为可管理的步骤);反向链式推理能力:(从期望的结果出发,逆向推导初始输入)。
这个实验是很有趣的。
数据上,使用Countdown游戏作为主要测试平台,Countdown是一个数学谜题,要求玩家使用基本算术运算组合一组输入数字以达到目标数字。
实验上,选择两个基础模型Qwen-2.5-3B和Llama-3.2-3B进行对比。使用VERL库和TinyZero实现进行强化学习实验,训练模型使用PPO算法进行250步训练。
样本选择上,训练和评估数据集来自Countdown游戏,包含3位数和4位数的问题,确保试验的多样性和一致性。
参数配置上,使用PPO算法进行训练,设置演员学习率为1e-6,评论家学习率为1e-5,KL系数为0.001,总训练轮数为15。
结论上,其一,Qwen模型在训练过程中自然表现出验证和回溯等推理行为,而Llama模型缺乏这些行为。Qwen在Countdown任务中的表现显著优于Llama;其二,通过预训练数据增强,Llama的性能得到了显著提升,达到了与Qwen相似的水平,这表明通过精心策划的预训练数据可以成功诱导出必要的认知行为。
具体的,如下:
如图1所示,Qwen-2.5-3B和Llama-3.2-3B模型在Countdown(倒计时,可能是一个任务名称)上结合强化学习(RL)的对比分析。

(顶部)(a)两种模型在Countdown任务中的性能得分;(b)在整个强化学习训练过程中响应长度的变化情况。
(中间部分)随着训练步数的增加,Qwen-2.5-3B(左)和Llama-3.2-3B(右)特定推理特征的出现情况。
(左下角)(a)当基础模型用期望推理行为的合成数据集进行预训练时在Countdown任务中的表现;(b)强化学习对经过预训练的Llama3.2-3B推理行为的不同影响:回溯和验证的增强与反向链接和子目标设定的抑制形成对比。
(右下角)通过在精心策划的OpenWebMath数据集上进行微调来教授推理行为的比较效果,表明通过对Llama进行有针对性的训练可以使其推理能力提高到与Qwen相当的水平。
二、关于R1用于音频领域工作Audio-Reasoner
关于R1用于多模态领域,这次是用于音频领域。
之前的工作包括链式推理(CoT)在多模态模型中的应用,如Visual-CoT、LLaVA-Reasoner和MAmmoTH-VL等,主要用于大规模数据集和多模态推理在图像和视频任务,但在音频领域,CoT的应用仍处于起步阶段,现有方法在复杂查询上的表现不佳。
例如,音频语言模型(LALMs)如Audio Flamingo、SALMONN和Qwen2-Audio在某些方面取得了进展,但这些模型在复杂推理任务中仍然存在局限性,主要是由于现有音频数据集的简单性。
所以,可以看一个工作,R1结合语音领域 **《Audio-Reasoner: Improving Reasoning Capability in Large Audio Language Models》(https://arxiv.org/abs/2503.02318)**, https://github.com/xzf-thu/Audio-Reasoner,https://xzf-thu.github.io/Audio-Reasoner/
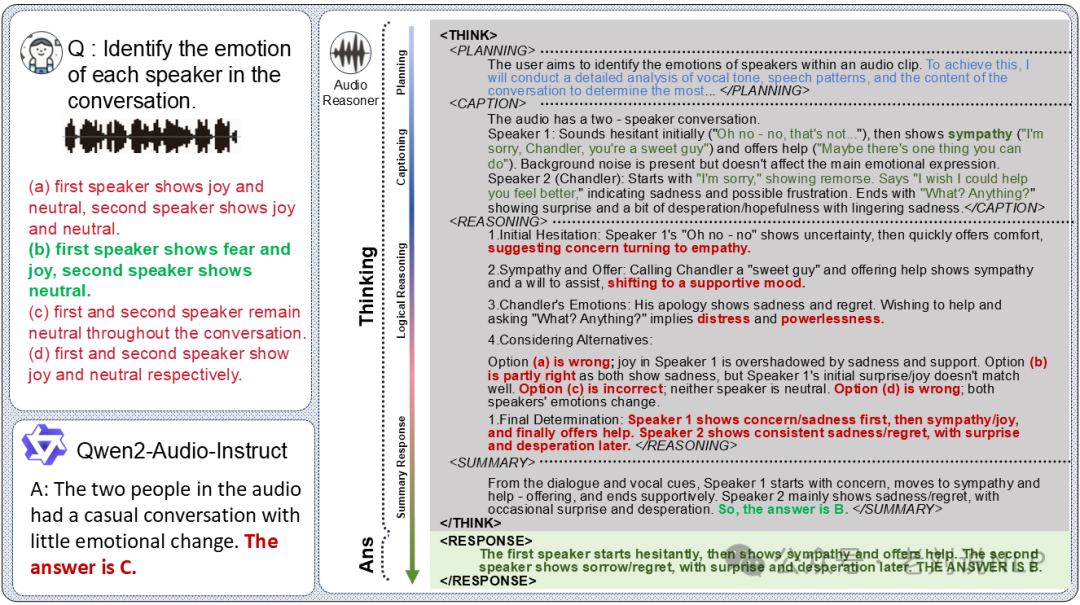
先看数据构成,这个基于推理能力,包括如下几个:
基于声音的问题回答,模型识别和分析声音特征,将其置于用户查询的背景中,以得出经过推理的回应;
基于言语的问题回答,模型识别说话者的音色,转录言语内容,并逐步处理问题以确定合适的答案;
语音情感识别(SER)和语音转文字翻译(S2TT), 这些专门任务要求模型将语音识别与情感分析和语言翻译相结合,形成一个结构化的推理过程;
基于音乐的问题回答, 由于音乐高度抽象,模型首先分析基本属性,如音调、节奏和情感,然后根据用户的查询进行流派分类和更深入的推理。
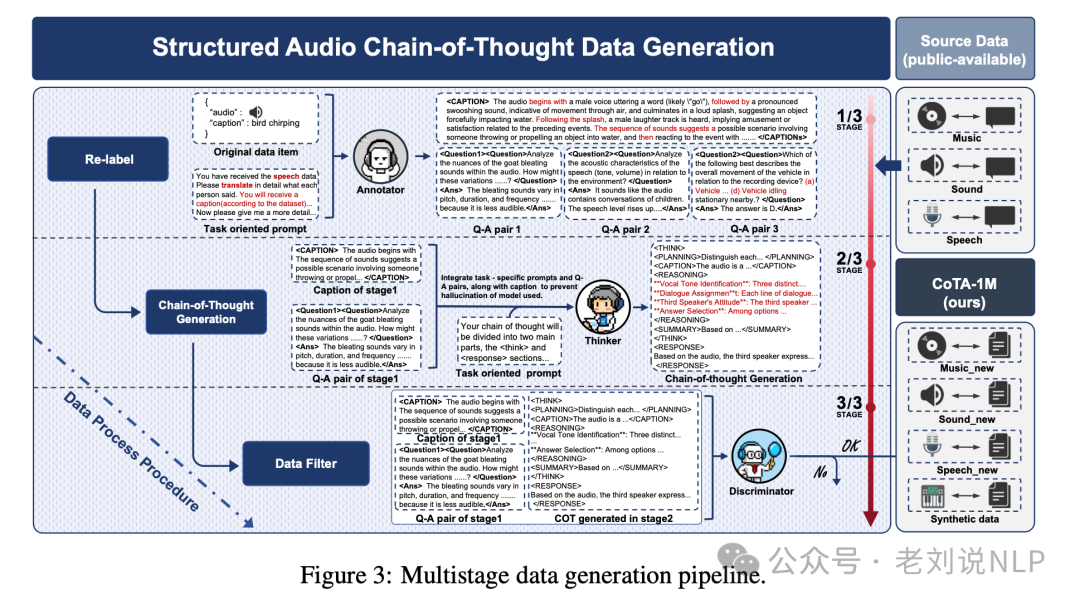
再看训练构成,模型的训练框架包括四个步骤: 规划(Planning):分析查询,识别关键问题组件,并制定推理步骤->标题提取(Captioning):从输入中提取相关的多模态内容,以丰富推理过程->推理(Reasoning):基于提取的内容,执行系统化的逐步推理->总结(Summary): 将推理过程合成为简洁、上下文相关且精确的最终响应。
模型输入包括音频信号和文本查询,输出包括结构化推理过程(CoT)和最终响应,模型的训练目标是最小化生成CoT和最终响应的概率分布的对数似然损失函数。
Audio-Reasoner基于Qwen2-Audio-Instruct,总共包含84亿参数。训练过程使用了ms-swift框架,采用监督微调和全参数调整,使用了最大学习率为1e-5,并在整个CoTA数据集上对模型进行了单次迭代训练。
参考文献
1、https://github.com/xzf-thu/Audio-Reasoner
2、https://arxiv.org/pdf/2503.02879
3、https://arxiv.org/pdf/2503.01307
(文:老刘说NLP)