
我大部分时间都在构建和改进 Retrieval-Augmented Generation (RAG) 应用。
我相信 RAG 可能是最受欢迎的 AI 应用之一。它无处不在,从聊天机器人到文档摘要。
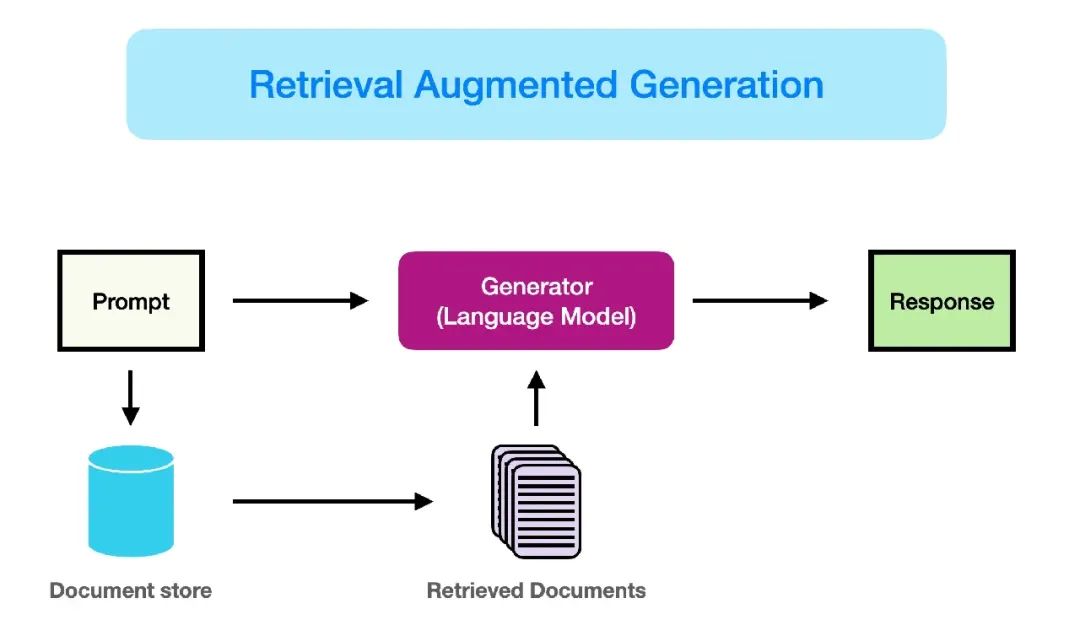
我也相信,由于各种原因,许多 RAG 应用最终未能部署,其中很多并非技术原因。然而,我希望自己早知道一些技术方面的知识,以创建更有效的 RAG。
但这就是我们学习新事物的方式。没有比构建并失败更好的工程学习方法了。
从我的失败中,我学到了一些宝贵的经验教训,这些经验对首次构建 RAG 的人很有帮助。你不必重复我犯过的错误,这样你就能更快前进。
那么,让我们谈谈第一个错误。
如果你对本文感兴趣,请点赞、转发、关注,感谢~~~
向量数据库并非硬性规定
几乎所有关于 RAG 的网络教程都使用向量数据库。如果你搜索过 RAG 相关内容,你会明白我的意思。
基于向量的检索无疑是 RAG 成功的重要因素。向量嵌入非常适合映射文本的语义含义。它们也适用于不同大小的文本。你的查询可能是一句话,但你的文档存储包含整页文章?——向量搜索可以处理。
然而,检索并不仅限于基于向量的检索。
RAG 可以从互联网、关系数据库、Neo4J 中的知识图谱或三者的组合中检索信息。
在许多情况下,我注意到混合方法能带来更好的性能。
对于通用应用,你可以使用向量数据库,但当向量数据库中没有所需信息时,你可以搜索互联网。
对于客户聊天机器人,你可能需要让 RAG 访问部分客户数据库,这可以是关系数据库。
企业的知识管理系统可能会创建一个知识图谱,并从中检索信息,而不是使用向量数据库。
这些都是 RAG 的定义。
然而,选择数据源的过程并非直截了当。你需要尝试各种选项,了解每种方法的优点。接受或拒绝一个想法的理由可能受技术和业务因素的影响。
例如,你可以为每个客户简介信息创建文本版本并进行向量化以供检索。这对于查询来说可能很高效,因为你只处理一个数据库。但它的准确性可能不如运行 SQL 查询。这是技术原因。
然而,让 LLM 运行 SQL 查询可能导致 SQL 注入攻击。这是技术和业务上的问题。
向量数据库在语义检索方面也很高效。但这并不意味着其他数据库不能处理语义检索;几乎所有其他数据库都可以进行向量搜索。
因此,如果你决定在 RAG 中使用某种形式的向量嵌入,这里还有一个建议。
优先选择经过微调的小模型
嵌入模型可以将任何内容转化为向量形式。大型模型的性能通常优于小型模型。
但这并不意味着越大越好。
别管模型大小。所有模型都在公开数据集上训练。它们能区分“苹果”水果和“苹果”品牌。但如果你和朋友用“苹果”作为暗号,嵌入模型无法知道。
然而,我们创建的几乎所有应用都专注于一个小的细分领域。
对于这些应用,大型模型的收益是微不足道的。
这里有一个不同的做法。
为你的领域数据创建一个数据集,并对小型嵌入模型进行微调。
小型模型足以捕捉语言细微差别,但可能无法理解在不同语境中有特殊含义的词。
但仔细想想,你的模型为什么需要理解木星的卫星?
小型模型更高效。它们速度快,成本低。
为了弥补模型在领域知识方面的不足,你可以对其进行微调。
这两个建议可以优化索引部分以实现高效检索。然而,检索过程也可以进一步优化。
检索过程可以更高级
最直接的检索过程是直接查询。
如果你使用向量数据库,可以对用户输入进行语义搜索。否则,你可以使用 LLM 生成 SQL 或 Cipher 查询。
必要时你还可以调用 HTTP 端点。
但直接查询方法很少能产生可靠的上下文。
你可以以更高级的方式查询数据源。例如,你可以尝试查询路由技术来决定从哪个数据源获取数据。具有良好推理能力的 LLM 可以用于此目的。你还可以在小型模型上进行指令微调,以节省成本并降低延迟。
另一种技术是链式请求。对于初始查询,我们可以从数据源获取信息。然后,根据获取的文档,我们可以获取后续文档。
分块是 RAG 中最具挑战性且至关重要的部分
当上下文包含无关信息时,LLM 容易出现幻觉。
防止 RAG 幻觉的最佳方法是分块。
现代 LLM 可能支持更长的上下文长度。例如,Gemini 2.5 Pro 支持高达 200 万个 token,足以容纳两到三本大学级别的物理教科书。
但对于基础力学问题,你很少需要量子物理的上下文信息。
如果你将教科书分解成较小的部分,可能每个部分只讨论一个主题,你就能只获取回答问题所需的相关信息。
这里的挑战在于分块技术有很多种。每种技术都有其优缺点。适合你领域的技术可能不适用于其他领域。
递归字符分块可能是最简单的,也是我的默认选择。然而,它假设文本中每个主题的讨论长度相等,这很少是事实。尽管如此,这是最好的起点。

你甚至可以尝试主题聚类和代理分块。
尝试重新排序
最后但同样重要的是,重新排序。
事实证明,相关分块的位置是高质量 LLM 响应的关键因素。
然而,常规向量搜索甚至数据库查询的排序方式并不智能。LLM 可以做到。
因此,我们使用专门的大型语言模型 (LLM) 作为重新排序器,重新排列获取的上下文并进一步过滤,找出最相关的分块。
这种二级重新排序在某些应用中有帮助,但在其他应用中未必。但你可以使用一些技术来改进重新排序的结果。
其中之一是获取大量初始结果。宽松定义初始标准会拉取一些无关上下文,但会增加获取正确内容的概率。
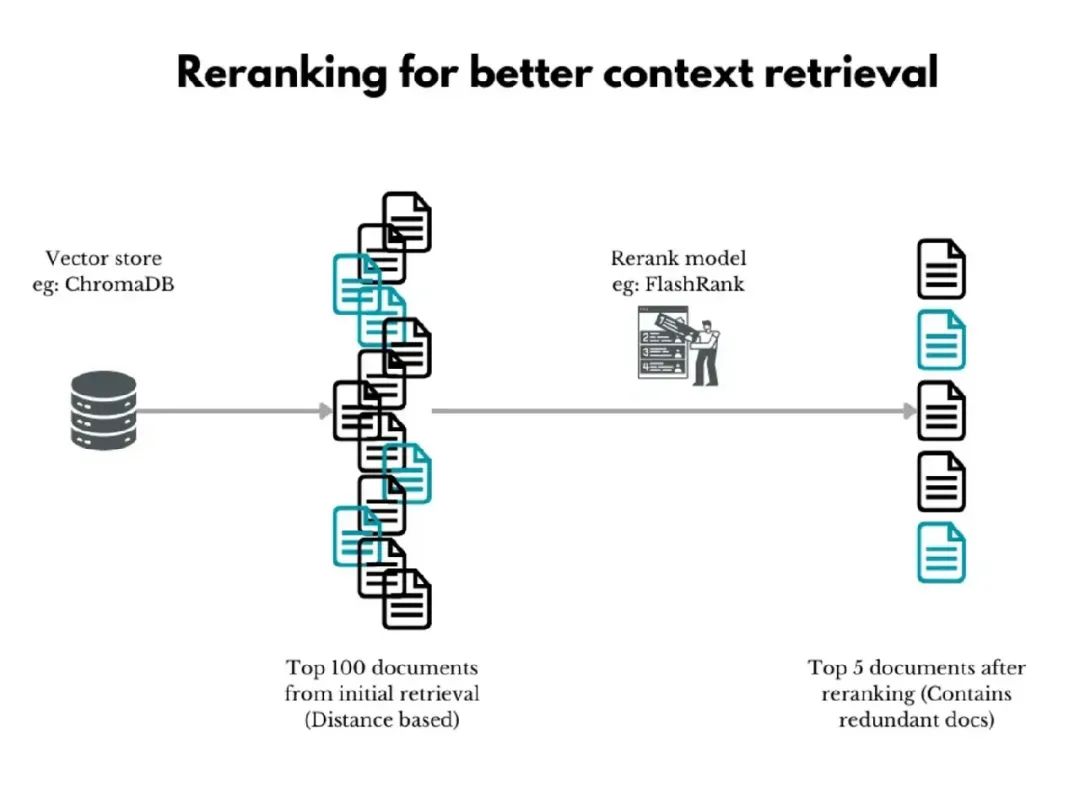
重新排序器现在可以处理这个大型集合并过滤出更相关的部分。
最终思考
构建 RAG 已成为任何 LLM 应用的必备。即使是 200 万 token 的上下文窗口也无法挑战它。
我们开发的原型通常未能部署。部分原因归于业务决策,但也有可以解决的技术原因。
本文是我在构建 RAG 方面的经验总结。
虽然这不是一个全面的列表,但考虑这五个方面将确保你开发出更持久的 RAG。
如果你之前构建过 RAG,你会添加什么?欢迎留言区讨论~~~
(文:PyTorch研习社)