

极市导读
本文提出了一种名为PolaFormer的新型视觉Transformer架构,通过引入极性感知线性注意力机制,显式建模正负查询-键(query-key)交互,解决了传统线性注意力机制中信息丢失和注意力图熵过高的问题。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本文目录
1 PolaFormer:极性感知的线性注意力机制
(来自哈工大深圳,鹏城实验室)
1 PolaFormer 论文解读
1.1 当前 Linear Attention 技术的特点:非负属性和低熵属性
1.2 非负属性和低熵属性的缺点
1.3 极性感知的注意力
1.4 通过可学习的幂函数降低 Linear Attention 的熵
1.5 ImageNet 分类结果
1.6 COCO 目标检测和实例分割结果
1.7 语义分割结果
太长不看版
Linear Attention 是基于 Softmax 的 Attention 的一种有前途的替代方案。但是,与原始基于 Dot-Product 的 Attention 相比,Linear Attention 中特征映射的非负约束和近似中使用的松弛指数函数导致显著信息丢失,使得熵比较高的注意力图比较少。
为了解决 Query-Key 对中相反值缺失的交互,本文提出了一种极性感知线性注意机制。该机制显式地对相同符号和相反符号的查询键交互进行建模,确保关系信息的全面覆盖。
此外,为了恢复注意力图的尖峰特性,我们提供了理论分析,证明了一类元素函数(具有正一阶导数和二阶导数)的存在,这些函数可以减少注意力分布的熵。
为简单起见,并识别每个维度的不同贡献,我们使用可学习的幂函数进行缩放,允许有效分离强弱注意信号。大量实验表明,所提出的 PolaFormer 提高了各种视觉任务的性能,提高了 4.6% 的表现力和效率。
1 PolaFormer:极性感知的线性注意力机制
论文名称:PolaFormer: Polarity-aware Linear Attention for Vision Transformers (ICLR 2025)
论文地址:
http://arxiv.org/pdf/2501.15061
1.1 当前 Linear Attention 技术的特点:非负属性和低熵属性
Transformer 的核心组件,即带有 Softmax 归一化的 Dot-Product Attention,使 Transformer 能够有效地捕获长距离依赖关系。但是,带有 Softmax 归一化的 Dot-Product Attention 的计算复杂度是 ,导致相当大的计算开销,尤其是在处理长序列视频或高分辨率图像时。这个缺点也老生常谈了,限制了它们在资源受限的环境中的效率,使得这种情况下实际部署变困难。
为了缓解这一挑战,Linear Attention 将 Dot-Product Attention 中的 Softmax 操作替换成基于 Kernel 的特征,从而将时间和空间复杂度从 降低到 ,其中 表示特征图的维度。线性注意的最新进展集中在设计 2 个关键部分:
-
非负特征映射,如 ELU +1[1]和 ReLU[2] -
核函数,包括 Gaussian Kernel[3],Laplace Kernel[4]和 Polynomial Kernel[5],以保持原始 Softmax 函数的核心属性,同时提高计算效率。
定义 为 Softmax Kernel 函数,Linear Attention 使用 来逼近 。因此,第 行注意力输出 可以重写为:
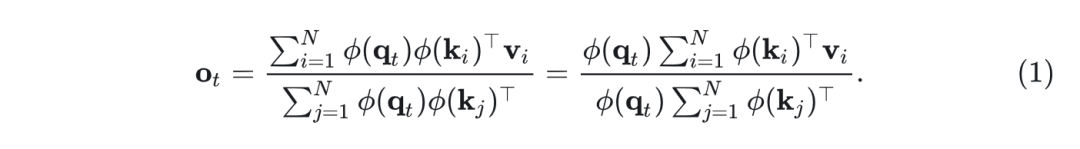
利用矩阵乘法的结合律,每个头的复杂度降低到 ,与序列长度呈线性关系。
尽管效率有所提高,但与基于 Softmax 的 Attention 相比,Linear Attention 在表达能力上仍然不足:如图 1 所示,它通常会在 Query-Key 对上产生更均匀的注意力权重,从而导致特异性降低。例如,在查询鸟类翅膀等特定区域时,线性注意力倾向于平等地激活来自不相关区域(例如杆子)的关键 token,引入干扰下游视觉任务的噪声。本文的分析确定了这种不足的两个主要原因,两者都源于 Softmax 近似期间的信息损失。各种 Linear Attention 方法的主要区别在于特征图 的选择。考虑到 是一个半正定核函数,所选特征图 必须满足两个属性:
-
非负属性: 为了在 近似中保持非负值,以前的方法利用激活函数,比如 函数,或者 函数。 -
低熵属性:如下图 1 所示,Transformer 中的注意力权重分布往往比 Linear Transformer 更加 "spiky",展示出更低的熵。

1.2 非负属性和低熵属性的缺点
1) 非负属性
Linear Attention 的非负属性使得特征图只保留了 positive-positive 的交互,而关键的 negative-negative 的交互和 positive-negative 的交互完全被丢弃。这种选择性表示限制了模型建模的能力,导致生成的注意力图的表达能力以及辨别力降低。同时,非负性使得 Linear Attention 丢失了原始的负值信息,而负值信息在 Dot-Product 计算中很重要。与标准注意力相比,这会导致线性注意力图中的不连续性。也有一些办法比如 Flatten Transformer[6]手动在所有维度上选择一个固定的范数 ,其中 ,这种固定的 范数在不同的数据集中可能不是最优的。
2) 低熵属性
Linear Attention 的低熵属性导致更均匀的权重分布和较低的熵。这种一致性削弱了模型区分强 Query-Key 对和弱 Query-Key 对的能力,削弱了它对重要特征的关注,降低了需要精细细节的任务的性能。
1.3 极性感知的注意力
本文提出了一种**极性感知注意力机制 (polarity-aware attention)**,包括一个可学习的 dimension-wise 幂函数,动态重新缩放相同和相反符号分量的大小,可以有效减少 Linear Attention 的熵。
极性感知注意力机制的关键思想是解决现有 Linear Attention 机制的局限性,即从负分量丢弃有价值的信息。作者首先将向量 和 做 element-wise 地分解为正负分量:
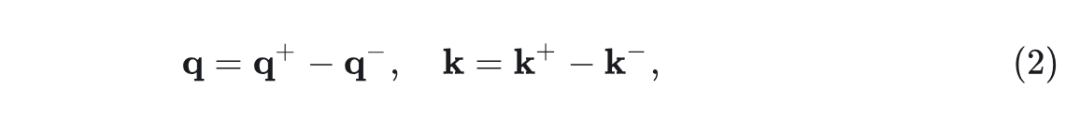
其中, ,表示 的正负部分。 也做同样处理。
将这些分解代入 和 的内积,将得到:
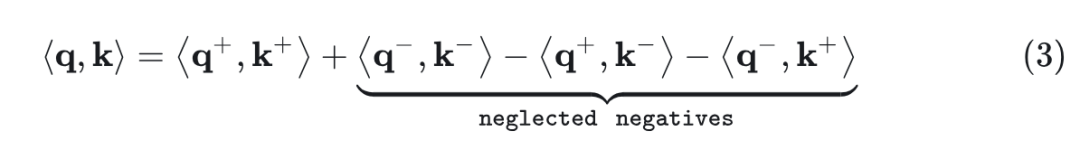
前两项捕获了相同符号组件之间的相似性,后两项捕获了相反符号组件之间的交互。以前的 Linear Attention 方法,例如基于 ReLU 的,将负分量映射到零来消除负分量,从而在逼近查询键点积时产生了显著的信息损失。
为了解决这个问题,极性感知注意力机制根据它们的极性分离 Query-Key 对,独立计算它们的交互。注意力权重计算如下:
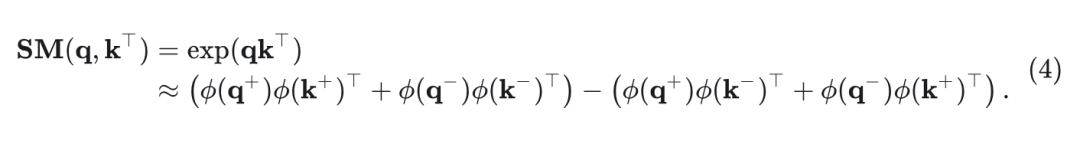
这个式子保持了正负组件中的信息。
可学习的极性感知混合 (Learnable Polarity-aware Mixing)
虽然这个公式捕获了由相同符号和相反符号组件携带的关键信息,但直接减去 (Query 和 Key) 相反符号的项,可能会违反非负约束,导致训练不稳定和性能次优。为了避免减法运算的缺陷,作者为相同符号的项和相反符号的项认为添加了一个可学习的 Gate,权衡相同符号和相反符号的贡献。
具体而言,作者将每个值向量 沿 维分成两半,分别处理相同和相反符号的响应,即 ,其中 和 的维度均为 。然后将输出注意力计算为:
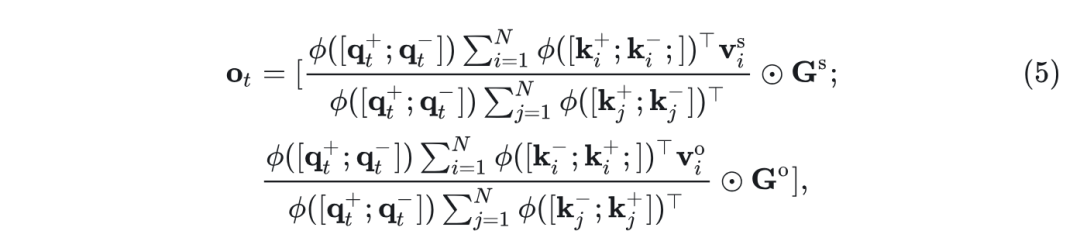
其中, 表示 concatenation 操作。 和 是两个可学习的极性感知系数矩阵,并应用元素乘法,这个操作期望学习到相同符号值和相反符号值之间的互补关系。

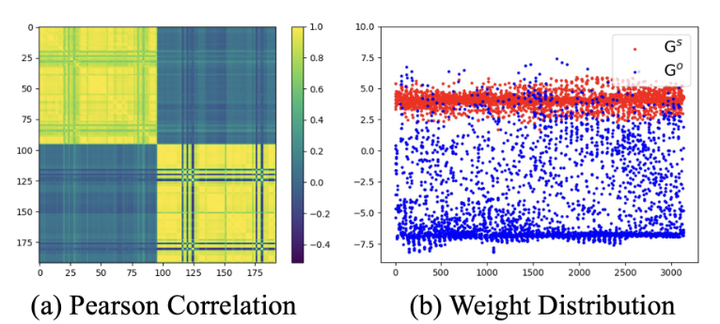
如图 3 所示, 和 学习到的权值之间存在明显的负相关和值差异。
1.4 通过可学习的幂函数降低 Linear Attention 的熵
与基于 Softmax 的注意力相比,Softmax-free 的 Linear Attention 通常表现出更高的熵,导致值向量注意力不那么尖锐,这不利于需要精确注意力的任务。为了恢复基于 Softmax 的注意力中观察到的低熵特征,作者将 中的每一行重新解释为广义非归一化正序列 ,并使用本文提出的正序列熵(PSE)度量分析其熵,定义为:
定义 1:(正序列熵(Positive Sequence Entropy,PSE))。定义序列 ,其中 和 。那么这个正序列的熵定义为:
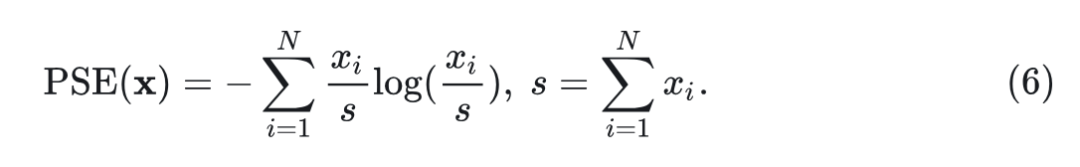
使用定义的 ,现在寻求一个函数 ,该函数可以逐元素应用 和 ,使得 Linear Attention 第 行的 PSE 降低。
Theorem 1: 令 (对于 ),令 是一个满足以下条件的可微函数:对所有的 有 。然后,存在这样的函数 使得转换后的序列的 PSE 严格小于原始序列的 PSE:
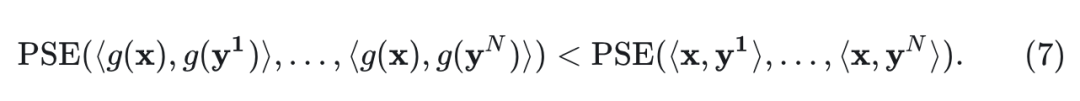
为了选择合适的函数 g ,存在满足这些条件的各种函数 g 。然而,为了模型的简单性和效率,作者选择了最直接的选择:指数大于 1 的幂函数。此外,由于不同的维度可能对相似度计算的贡献不相等,作者设计了可学习的指数来捕捉每个维度的不同重要性:
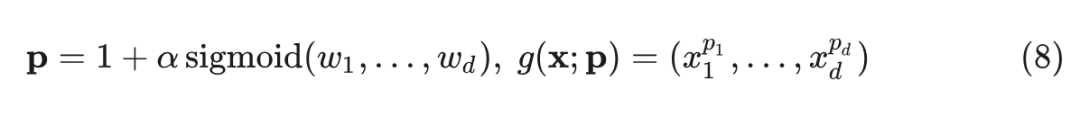
其中, 是超参数缩放因子, 是可学习的参数。因此,线性注意力中的特征图可以表示为 和 ,其中, 指的是 q 或k。
Theorem 1 证明:
第 1 步证明 Lemma 1,即:
Lemma 1:假设 函数是一个和 函数有关的函数 ,且满足对所有的 有: ,定义为:
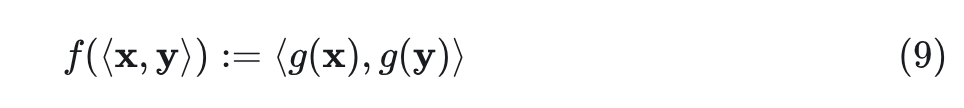
其中, .,则对于所有的 有:
证明:
考虑维度为 的 Element-wise 的函数 :
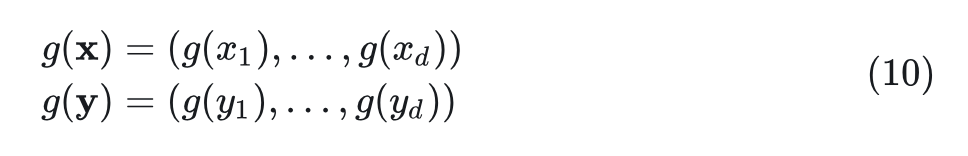
然后, 和 之间的可以通过下式算出:

由于维度之间的独立性,应用 Jensen 不等式,利用 和 ,有:
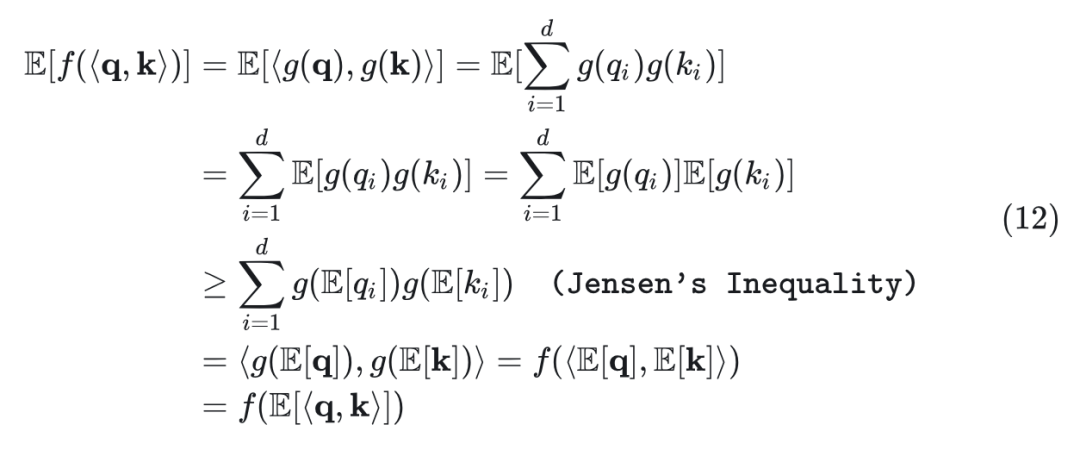
其中 表示向量。因此,有以下结果:
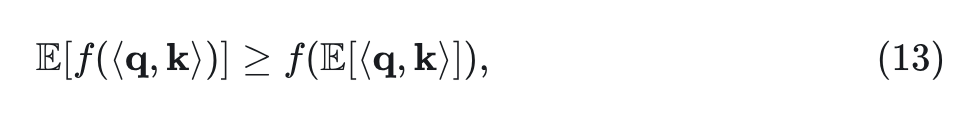
表明 是具有正二阶导数的凸函数。此外,根据 和 的定义, 显然从 到 的映射具有正一阶导数。
证毕。
第 2 步证明 Lemma 2,即:
Lemma 2:给定两个正值 以及函数 ,以及条件 ,有 。
证明:
考虑 (可扩展到 )的情况。不失一般性,假设 ,则 , 可以计算为:
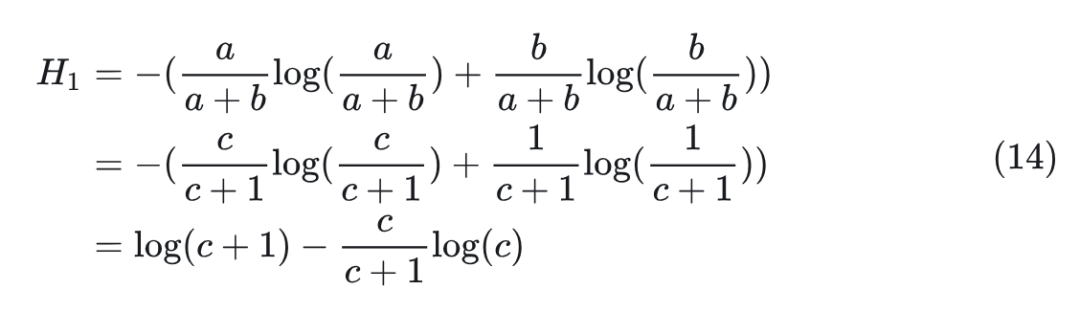
然后,将核函数 应用于 ,并将其映射到 。然后,定义 ,很容易证明 。然后可以计算 为:
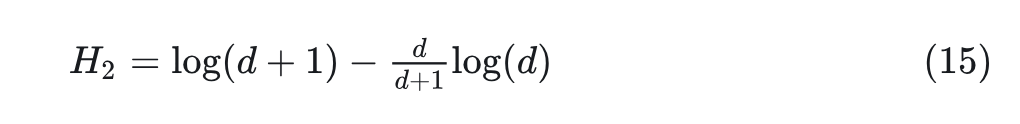
通过定义 ,我们有:

表明对于所有 ,有: ,即 $H_2<h_1$ 。因此,满足条件的所有函数都具有熵降低的影响。<=”” p=””>
证毕。
现在回到 Theorem。首先,定义 诱导的 使得:
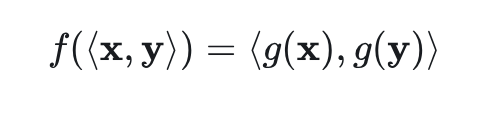
从 Lemma 1 中,可知 是一个具有正一阶导数和二阶导数的函数。然后通过使用 Lemma 2,有:
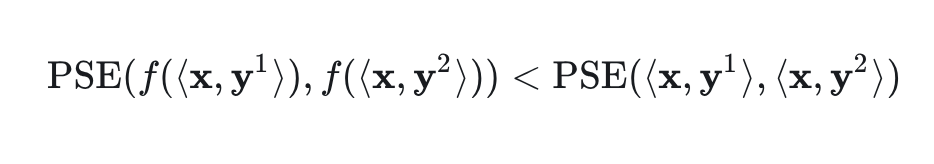
因此,scaling 效果可以通过基于具有正一阶导数和二阶导数的函数进行 element-wise 的计算来实现。这允许去除 Softmax 函数,从而在 Attention 中同时实现线性复杂度和较低的熵。
1.5 ImageNet 分类结果
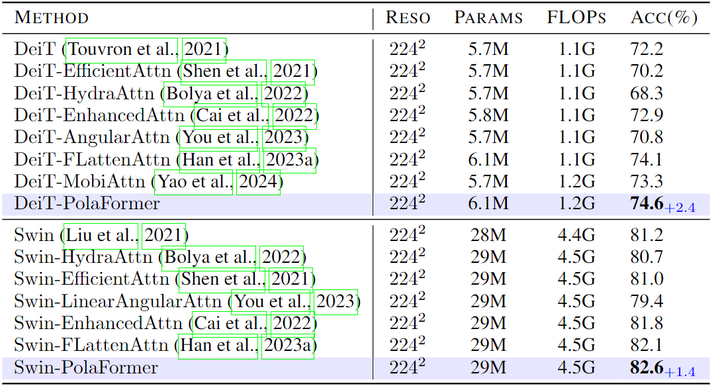
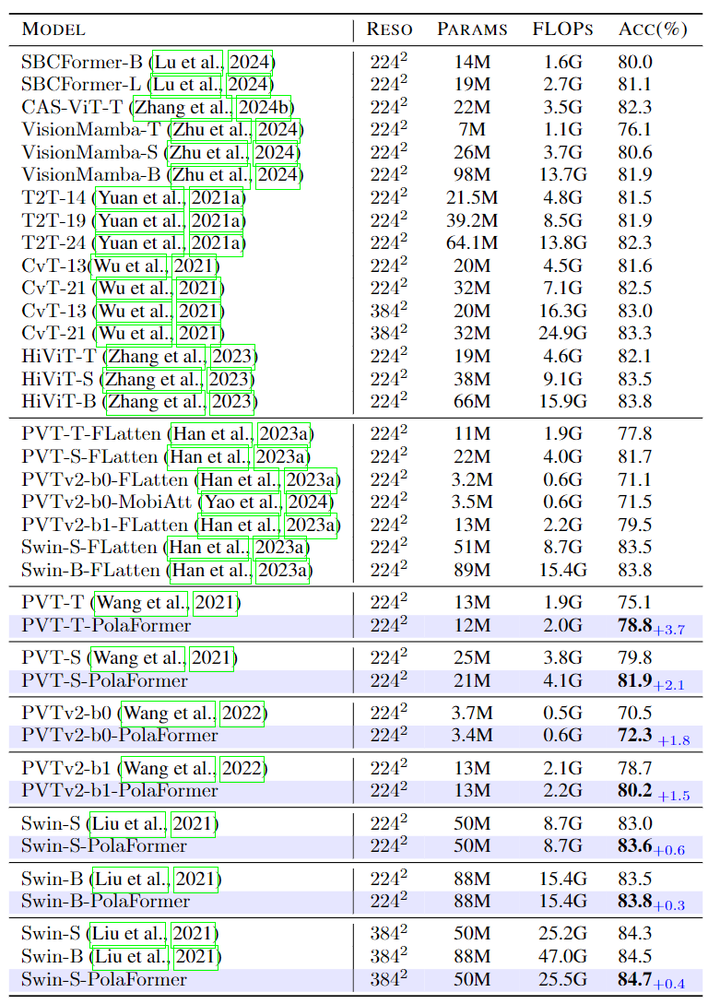
实验结果如图 4 和 5 所示。在图 4 中,DeiT-T-PolaFormer 超过了其他 DeiT 变体 0.5% 到 6.3%。图 5 中,PVT-T/S-PolaFormer 获得了 3.7% 和 2.1% 的提升。此外,集成到 Swin 和 PVTv2 中的方法在性能和效率之间实现了更好的平衡。这些结果表明,PolaFormer 增强了注意力机制的表达能力,可以广泛应用于各种基于 Attention 的模型中。
1.6 COCO 目标检测和实例分割结果
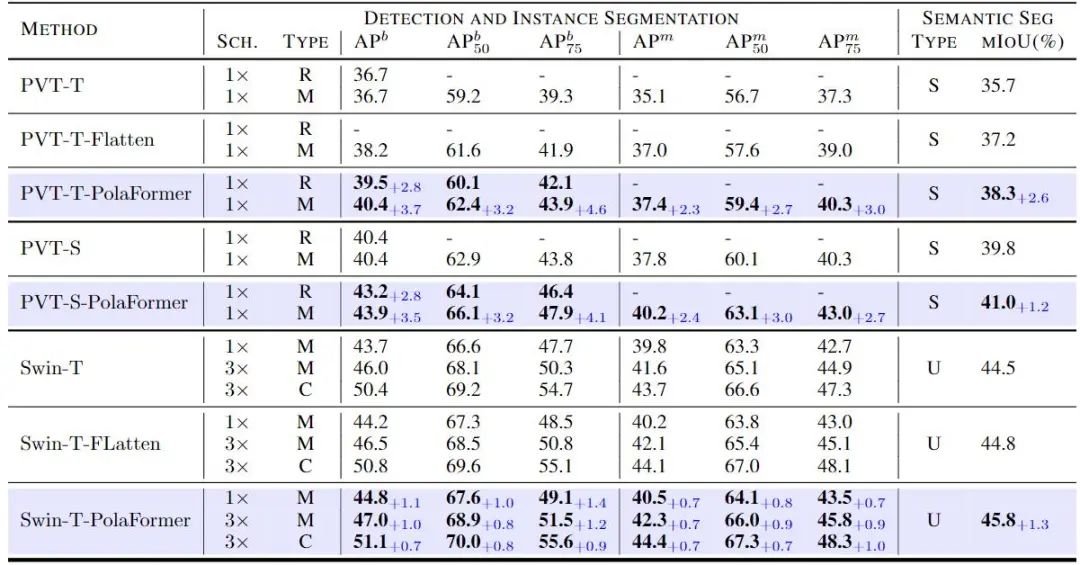
作者进一步验证了所提出的方法在各种视觉任务中的有效性,包括 COCO 数据集上的目标检测任务,其中包含超过 118K 训练数据和 5K 验证数据。作者将 Pola-Swin 和 Pola-PVT 分别作为骨干集成到 Mask-RCNN、RetinaNet 和 Cascade Mask R-CNN 中,并根据 ImageNet-1K 预训练的权重评估它们的性能。
如图 6 (左) 所示,本文模型在所有设置下始终优于原始 Backbone,在所有指标上都取得了显著的改进。例如,使用 RetinaNet 和 Mask-RCNN 检测器测试的 PVT-T-PolaFormer 超过了基线 2.3% 到 4.6%。此外,Swin-T-PolaFormer 在 中达到了 49.1%,与原始具有 Mask-RCNN 检测器的 Swin-T 相比提高了 1.4%。与分类任务相比,模型在需要细粒度的注意力图来准确定位边界框的检测方面提供了更显着的性能提升。
本文的模型捕获了之前省略掉的负值信息的交互,并通过幂函数的 Rescale 更好地恢复了 Attention map。
1.7 语义分割结果
在 ADE20K 数据集上的像素级语义分割任务微调预训练模型时,也观察到了类似的现象。ADE20K 为场景、对象和对象部分提供了一组不同的注释,其中包含 25,000 张在自然空间环境中具有不同对象的复杂场景图像。作者将 Pola-Swin 和 Pola-PVT 与 ImageNet-1K 预训练权重集成到两个分割模型 SemanticFPN 和 UperNet 中,使用 mIoU 作为评估指标。结果如图 6 (右) 所示,mIoU 的性能提升范围从 1.2% 到 2.6%。这些发现进一步突出了我们模型的多功能性,表明它可以有效地微调并适应广泛的视觉任务。
参考
-
^Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention -
^COSFORMER : RETHINKING SOFTMAX IN ATTENTION -
^Skyformer: Remodel self-attention with gaussian kernel and nystrom method -
^Revisiting Linformer with a modified self-attention with linear complexity -
^Polysketchformer: Fast transformers via sketching polynomial kernels -
^FLatten Transformer: Vision Transformer using Focused Linear Attention
(文:极市干货)