鹅厂,终于推出自己的AI视频了——「混元视频模型」。
最近,受邀参加混元视频模型的内测。周末连肝两天,从早肝到晚,肝了累计有300多支视频吧![]() 。
先说结论:作为鹅厂交出的第一版(文生视频、5s),总体质量非常高。在指令遵循、动态和画面稳定性、镜头语言、写实质感、物理遵循等方面表现不错,抽卡很少。
甚至,在一些镜头转换、动作特效、科幻/魔幻风格、抽象理解等方面,还有惊喜表现。
。
先说结论:作为鹅厂交出的第一版(文生视频、5s),总体质量非常高。在指令遵循、动态和画面稳定性、镜头语言、写实质感、物理遵循等方面表现不错,抽卡很少。
甚至,在一些镜头转换、动作特效、科幻/魔幻风格、抽象理解等方面,还有惊喜表现。
请看VCR:

为了系统的测测混元视频模型的质量,当然相比那些专业评测基准,也不算很系统。只是我个人认为比较重要也是大家经常会用到的一些风格场景,我把他们分成了10个板块来测。
这10个风格分别是:特写、写实、人物、动物、科幻、特效、动画、艺术/抽象、运动、多人场景/大场面/多镜头。
每个风格,分别设计3~5个提示词,让混元出视频,进行测评。
提示词部分,我自己先想一个idea,用一句话描述,然后让AI帮我优化、扩写。AI优化后的提示词,我自己再改改,基本上就可以发给模型开始跑了。
-
-
模板2:提示词=主体(主体描述)+场景(场景描述)+运动(运动描述)+(镜头语言)+(氛围描述)+(风格表达)
-
模板3:提示词=主体+场景+运动 + (风格表达) + (氛围描述) + (运镜方式) + (光线) +(景别)
重点关注 主体+场景+运动 即可,其他部分如果不太会描述,也可以通过后台提供的标签来选择。
Ps.所有Case都由我自己实测,不含任何官方的demo。
写实,几乎是视频模型必测的风格了。主要看模型对不同场景、人物表情、人物动作、纹理细节以及光影变化的生成效果,看他们是否与真实世界保持一致。

2)一个中国美女穿着汉服,头发随风飘扬。然后镜头切换到正面特写。背景是张家界。

3)一只戴红围巾的企鹅在花海散步,红围巾与花海色彩形成鲜明对比。背景的花海随风轻摆,花瓣飘落,晨露闪烁。

4)超长焦横移,工业废弃厂房,主光从碎裂天窗渗入,自然光。

特写,是视频模型比较擅长的风格。各家模型比拼的关键在于对细节的呈现能力 ,比如物体运动细节、人物肢体细节、人脸表情细节、画面质量细节等。
一个好的特写镜头,很容易拉近观众与主角的距离,让观众身临其境。
4)一名男子惊恐地望着远方,背景是一座正在燃烧和爆炸的城市。镜头对准男子的脸,捕捉到他惊恐的表情。

5)镜头慢慢推近。背景是一个小巧而温馨的客厅,一位年轻女子坐在沙发上,全神贯注地读书。一个冒着热气的茶杯放在咖啡桌上。


人物,主要看视频模型对人的肤色、肢体动作、表情动作以及衣着呈现的真实性,也是我们作为人类最容易识别出AI真假的地方。
但话又说回来,文生视频在人物方面的表现上都不太占优。要想人物表现更稳定、真实和一致,一般得通过图生视频来生成。


9)一个男人坐在沙发上看电视,然后双手抱头,表情非常惊讶。

相对人物来说,各家视频模型在动物上的表现都要好很多。但前提是你的动物得“大胆”地动起来,而不是只将画面放大、缩小![]() 。
从我跑的多支Case来看,混元视频模型在动物写实上非常不错,有点纪录片的味道了。
10)非洲草原上,一只猎豹正在极速奔跑,追逐一头羚羊。
。
从我跑的多支Case来看,混元视频模型在动物写实上非常不错,有点纪录片的味道了。
10)非洲草原上,一只猎豹正在极速奔跑,追逐一头羚羊。

11)大兴安岭,一只老虎正在极速奔跑,背景是皑皑白雪的森林。


科幻、魔幻、玄幻等幻想风格,是吸引很多人用AI做视频的重要原因,当然也包括我。
幻想风格,特别考验视频模型的数据集和泛化能力(指模型对新的、未见过的数据的表现能力),能否把一些幻想场景给展示出来,比如光影变化、色彩变化、变形特效、动作特效等。
这部分,我Case放得最多。考虑到视频转图被压缩(公众号传图不能超过10M),部分case我直接放了原视频。
14)一艘飞船正在穿过时光隧道,周围是五彩斑斓的光线。
15)两个巨型机器人在城市中激战,每一次碰撞都产生巨大的冲击波,将附近的建筑震成碎片。

16)昏暗的走廊,一支海军陆战队正在穿过废弃的走廊。

17)在若隐若现的云端,乌云密布,电闪雷鸣。突然一条巨龙从云层穿过,飞奔而来。
特效,Special Effects,是电影、电视中最重要的视觉艺术,常见特效如爆炸、烟雾、火焰、极速等。
特效镜头,也是主要考验视频模型的泛化能力,看模型对指令的遵循程度以及细节表现能力。
18)暴风雪中,一列蒸汽火车在崎岖山间穿行,黑烟从车头直冲云霄,车厢在皑皑白雪中留下深邃轨迹。


17)雾蒙蒙的夜晚,明亮的月光,一艘中世纪的帆船在海上航行,充斥着诡异的氛围。

20)五颜六色的水母在海底自由自在地游动。它们身体呈现出透明的蓝色、紫色和粉色,在水中散发出迷人的光芒。

动画,主要看模型对各种风格的支持和审美,比如2D、3D、矢量、黏土、水墨、宫崎骏、迪士尼等。
21)Animated scene features a close-up of a short fluffy monster kneeling beside a melting red candle. The art style is 3D and realistic, with a focus on lighting and texture. The mood of the painting is one of wonder and curiosity, as the monster gazes at the flame with wide eyes and open mouth. Its pose and expression convey a sense of innocence and playfulness, as if it is exploring the world around it for the first time. The use of warm colors and dramatic lighting further enhances the cozy atmosphere of the image.
22)一片奇幻花园映入眼帘。花园里长着各种奇花异草,它们形态各异,颜色缤纷。在花园中,还生活着一群活泼可爱的小精灵,它们身着五颜六色的衣服,在花草间嬉戏玩耍。吉卜力动画风格,让人仿佛置身于宫崎骏创造的梦幻世界中。

艺术风格,主要考验视频模型对图形、空间、色彩和受力变化的抽象理解。测了几个case,没想到混元也能做一些抽象的艺术视频。


25)5度斜角固定镜头,浅景深对焦,紫红霓虹灯与青色全息投影交织。画面中央的机械舞者着装前卫,张开双臂,向观众致谢。

运动,被视为视频模型皇冠上的明珠,因为它最具挑战性。
要想生成符合真实世界物理运动的视频,模型对空间位置关系的理解,对不同物体受力变化、形态的处理,以及对不同物体、不同运动的语义理解,都要有相当深的技术,才能生成出遵循物理规则的视频。
26)日落时分的越野赛道,改装过的福特F-150猛禽呼啸而过。加高的悬挂让硕大的防爆轮胎在泥地上肆意翻飞,泥浆飞溅在防滚架上形成斑驳图案。车身贴花在金色阳光下闪闪发亮,机械增压器的呼啸声与排气轰鸣交织。

27)慢动作回旋镜头,雷暴天气伴随着闪电,一位英姿飒爽的中国侠客在雨中舞剑。背景是一片竹林。

28)一辆越野车在险峻的山腰上行驶,远处的贡嘎雪山在视觉上缓缓升起逐渐清晰。

多人场景,涉及多人物动作协调以及算力问题,目前基本上很多视频模型都会崩,包括Gen3、可灵等。我们看看混元的效果如何。
29)镜头从骑着马的骑士的脚步局部特写开始缓缓上升,最终拍摄到骑士的面部,骑士面带坚毅的表情看向前方。背景是一个中世纪战场,两军正在交战,人仰马翻。


1)混元模型对指令(也就是提示词)比较遵循。后续大家在设计提示词时,建议一定要有强画面逻辑,指令清晰,切勿堆砌一堆的修饰词以及过多的主体词。
不然反而会干扰模型的注意力,也就是模型DiT架构的T,Transformer,自注意力机制。
2)动态表现和画面稳定性很好。在我测的300多支视频里,肯定有失败的Case,但没有一支视频是在做PPT的放大或缩小。都是正常动作,正常速度,很少有慢镜头、PPT动画。
3)对镜头语言理解到位。如果你指定是什么镜头和景别,模型便会严格遵循。如果没有指定,模型则会根据提示词自行理解,设计镜头,有时候能够给人惊喜。
提示词:超大海浪,冲浪者在浪花上起跳,完成空中转体。摄影机从海浪内部穿越而出,捕捉阳光透过海水的瞬间。水花在空中形成完美弧线,冲浪板划过水面留下轨迹。最后定格在冲浪者穿越水帘的完美瞬间。
4)5s视频也能切镜头。在部分提示词的场景下(通常为长提示词),混元模型即使只有5s视频,也能够自动切镜头。切镜头后,还能能够保持主体一致性。
5)在科幻、魔幻、写实纪录片、特效、运动等风格上表现出色,出片率很高。特别是魔幻风格,很有权游的味道,推测应该与鹅厂自家的视频数据集有关。
6)抽卡次数少。如果指令清晰,有时候一次生成就能够得到满意的视频。最不济再生成3-5次,基本也能拿到心满意足的视频。
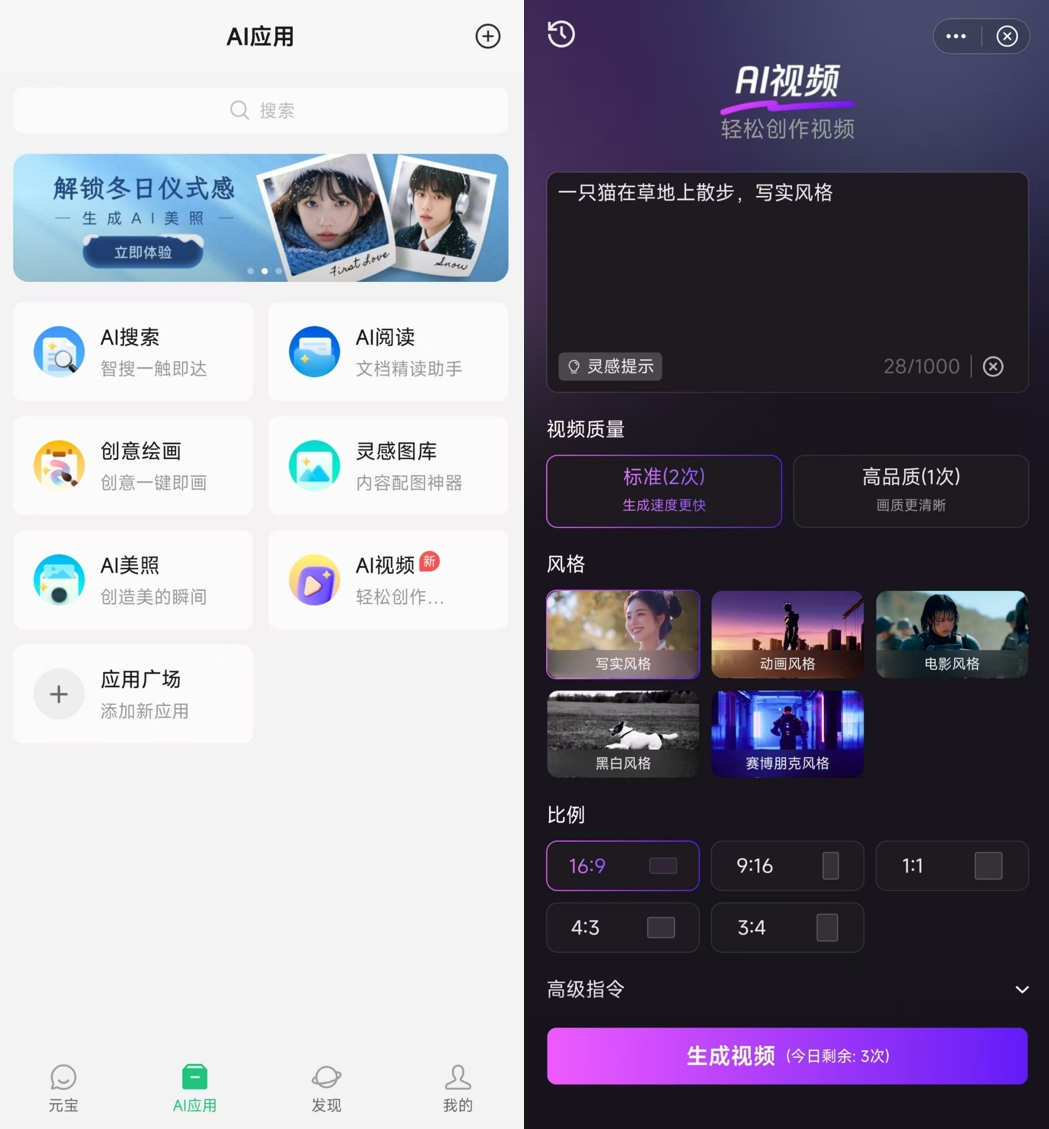
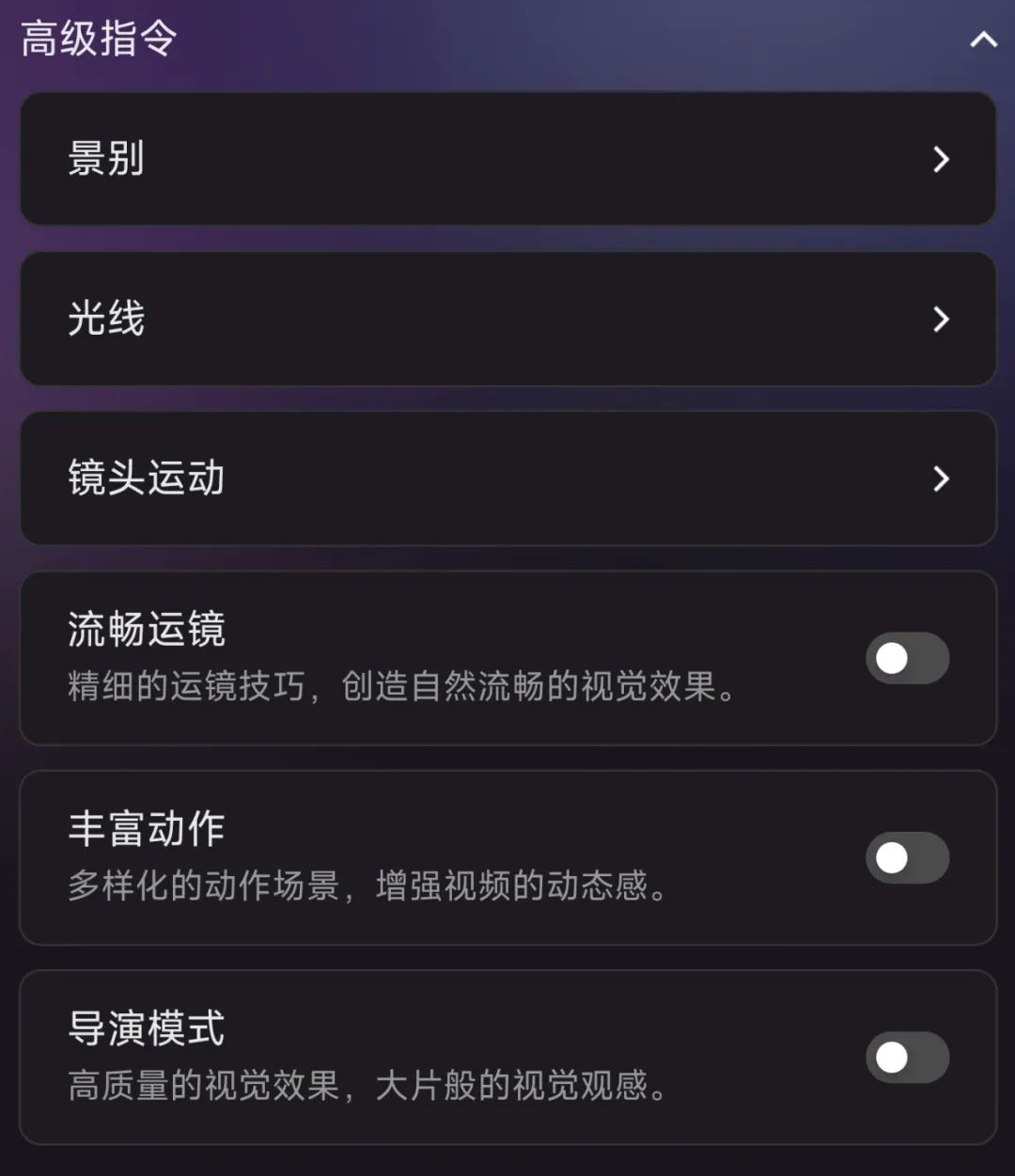
7)尽量照顾小白。在输入框界面,提供了风格、景别、光线、镜头运动以及多种模式(流畅运镜、丰富动作、导演模式),小白也能快速上手。
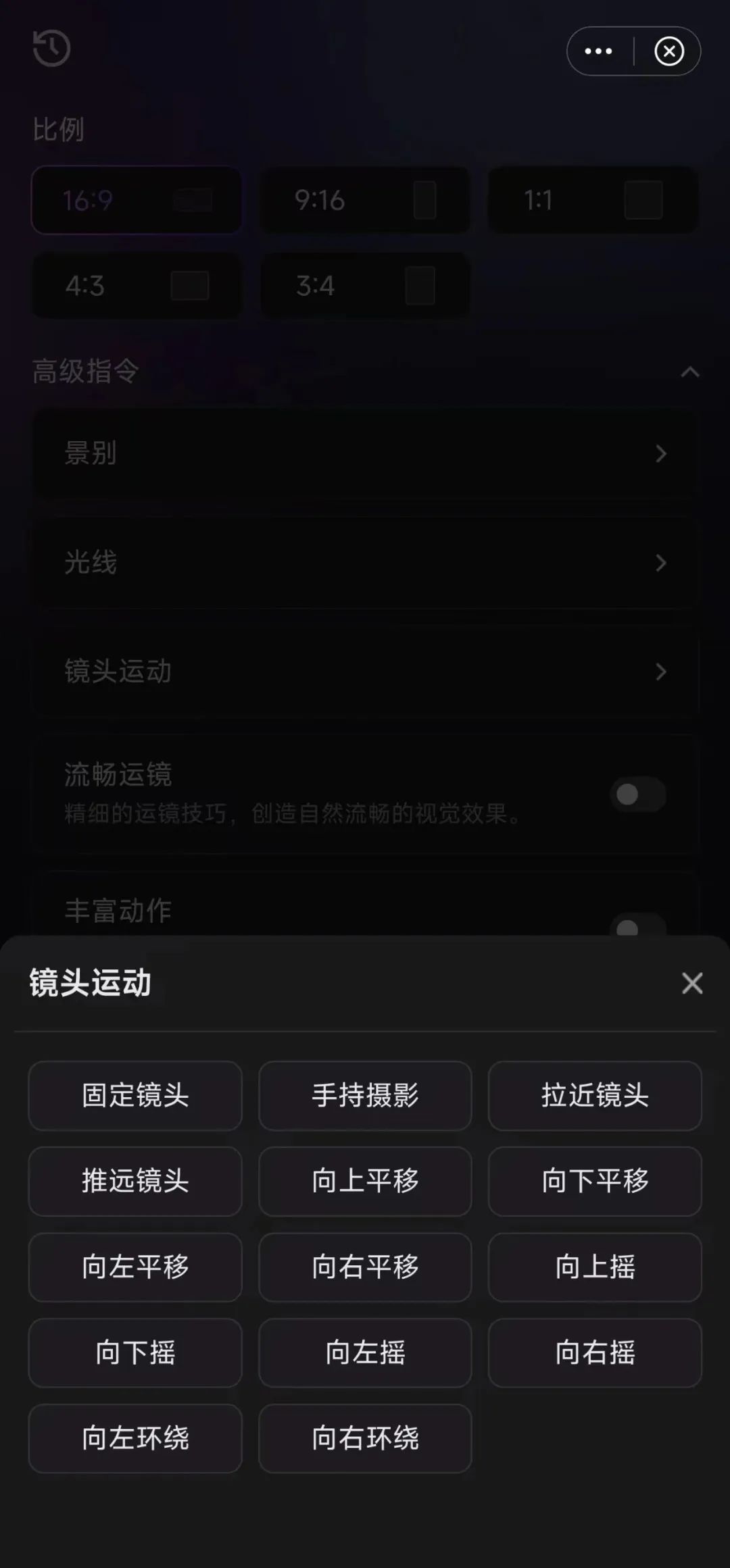
别小看这些标签。在我测的过程中,这些标签对我的视频效果帮助很大,特别是视频风格和运镜方面。
1)泛化能力有待提升。一些陌生、冷门、未训练的描述词(比如主体、场景、动作等),混元还无法识别,导致模型的创造力受到一定影响。
2)画质还需要提升,目前只有720P(是真的720P),虽然提供了“高品质”模式,但对于专业创作者来说,还不太够。
3)对本土人物的理解,还需要提升。如果提示词里没有注明“亚洲人”,模型通常会以欧洲人来生成。当然,文生视频本就不擅长人物主体的一致性,要想提升人物一致性还得等图生视频。另外,模型在情绪的展现上,也稍微弱一些。

经过连续三天的测评,个人认为,作为初代模型,混元的总体质量是非常高的,比很多视频模型第一版的表现都要好。
跟混元的同学了解了下,这源于他们在这些方面的创新:
-
使用新一代语言模型作为文本编码器,具备更强的语义理解和画面呈现能力;
-
全程采用full attention(全注意力)机制,而不是时空模块,使得每帧视频的衔接更为流畅;
-
使用自研图像视频混合VAE(3D 变分编码器),提升模型在细节上的表现能力,比如人脸、手指、高速镜头等。
现在起,无论是个人还是企业,所有开发者都可以在Hugging Face和Github上免费使用这个模型了。
代码:https://github.com/Tencent/HunyuanVideo
模型:https://huggingface.co/tencent/HunyuanVideo
卧槽!大气,真的大气!130亿参数的模型,说开源就开源。包括模型权重、推理代码、模型算法等完整模型,直接全部公开。
要知道,视频模型因为技术最难,敢开源、能开源的真没几家,包括“源神”Llama推出的视频模型Movie Gen,都不打算开源。
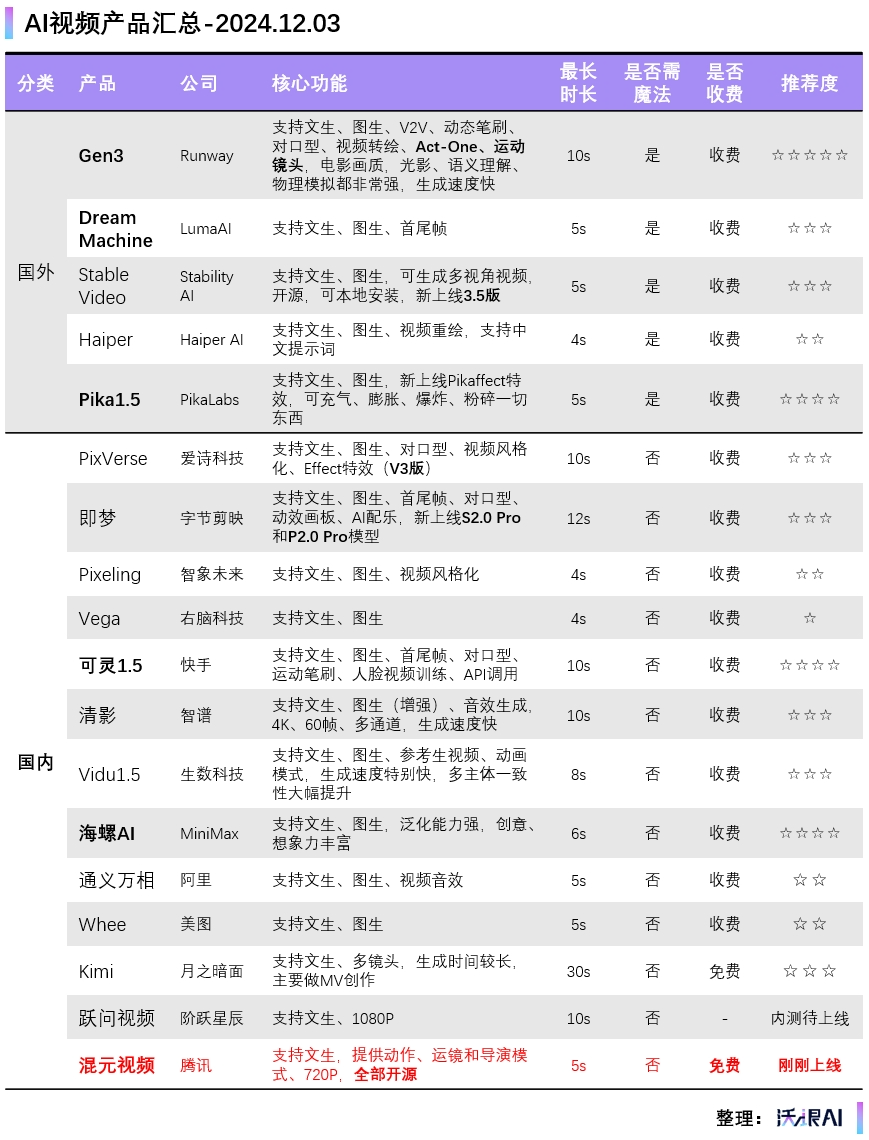
而混元视频模型,上线就开源,这气度,这格局,牛。到目前,他们已经开源了文生文、文生图、3D生成以及最新的文生视频。
(文:沃垠AI)

 。
。