
电影画质、艺术体验;原生切镜,丝滑转场
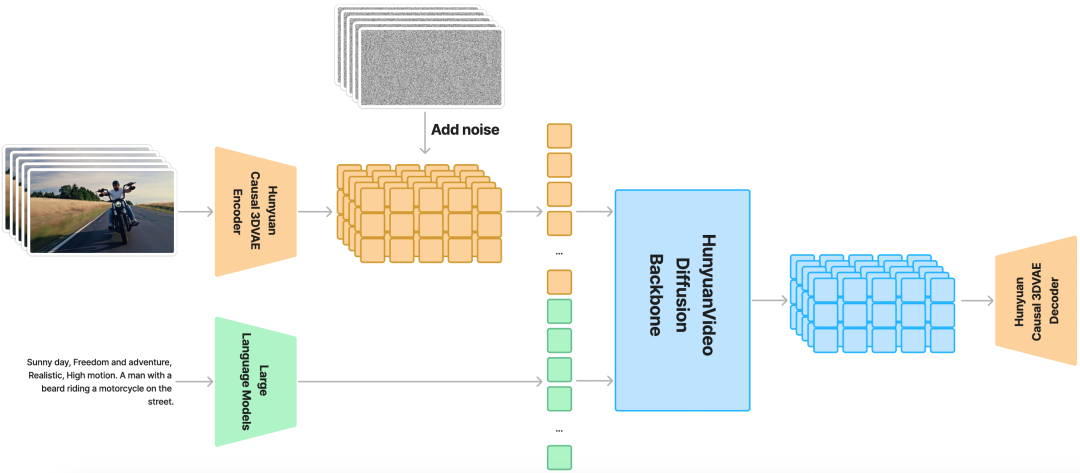
HunyuanVideo是目前最大的开源视频基础模型,它通过集成数据管理、图像-视频联合训练和高效基础设施等关键技术,超过130亿参数,并且在视觉质量、运动多样性、文本-视频对齐和生成稳定性方面超越了现有先进模型: Runway Gen-3、Luma 1.6和3个表现最好的中文视频生成模型。
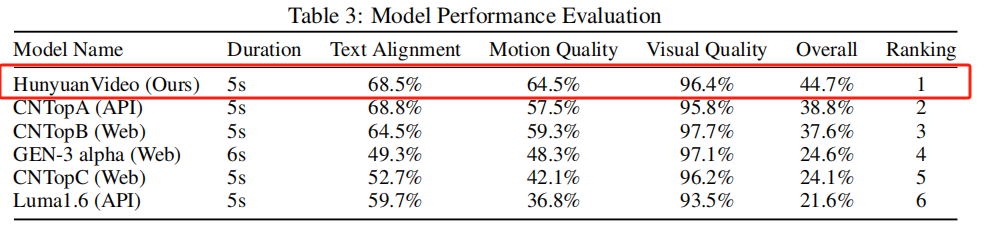
HunyuanVideo在一个时空压缩的潜在空间上进行训练,该空间通过因果3D VAE进行压缩。文本提示使用大型语言模型进行编码,并用作条件。高斯噪声和条件作为输入,生成模型生成输出潜在表示,然后通过3D VAE解码器将其解码成图像或视频。
https://github.com/Tencent/HunyuanVideohttps://aivideo.hunyuan.tencent.com/
(文:PaperAgent)