



-
论文:Multimodality Helps Few-shot 3D Point Cloud Semantic Segmentation -
论文链接:https://arxiv.org/abs/2410.22489 -
GitHub链接:https://github.com/ZhaochongAn/Multimodality-3D-Few-Shot

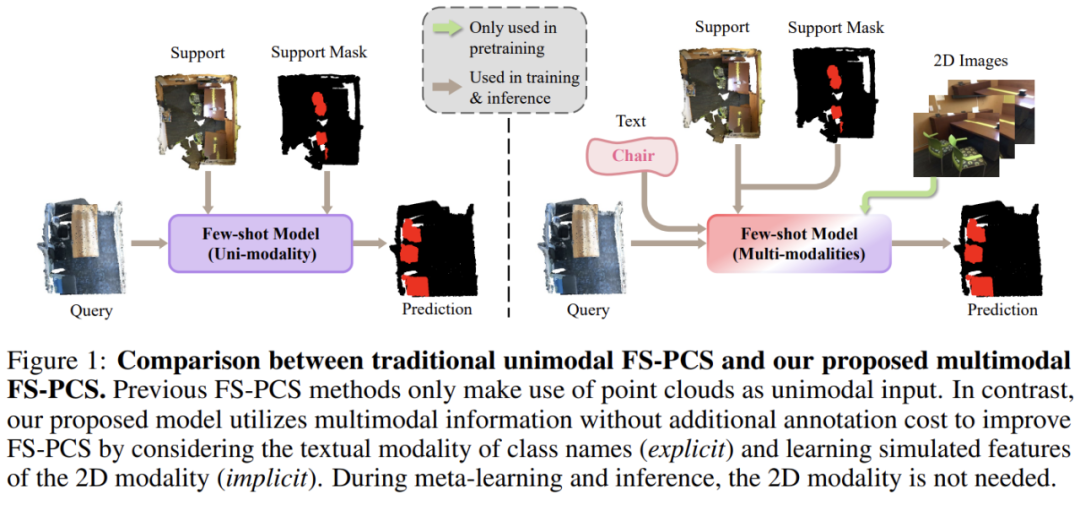
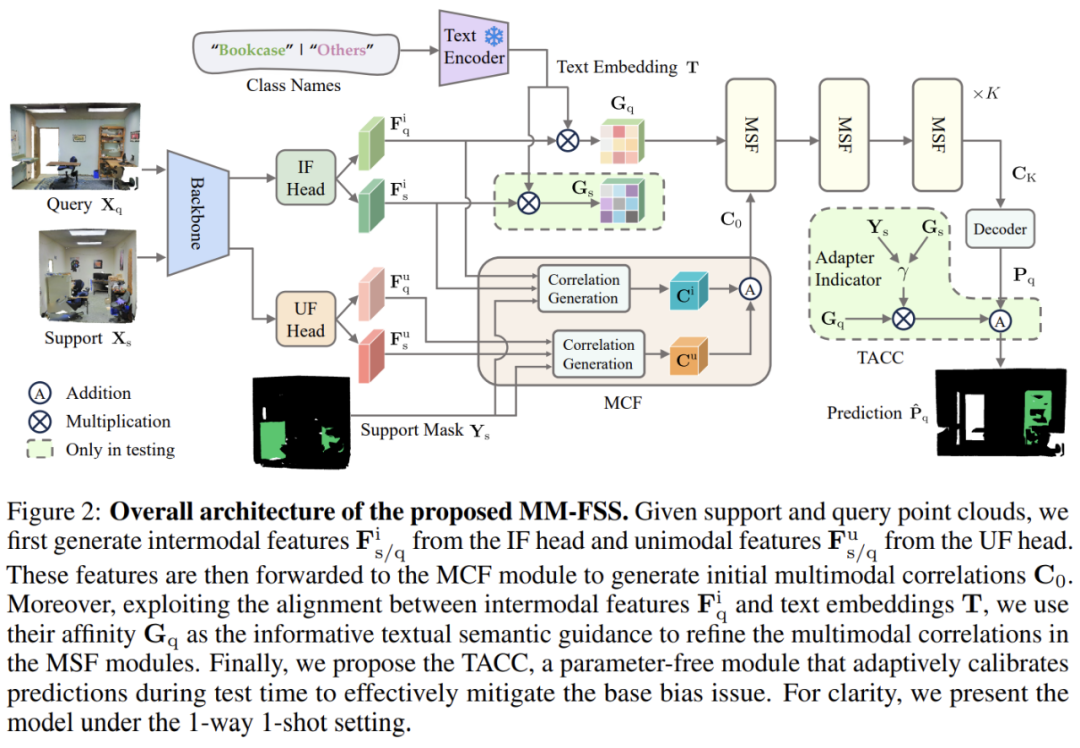
-
Intermodal Feature (IF) Head(跨模态特征头):学习与 2D 视觉特征对齐的 3D 点云特征。
-
Unimodal Feature (UF) Head(单模态特征头):提取 3D 点云本身的特征。
-
Backbone 和 IF Head 保持冻结,确保模型在 Few-shot 学习时能利用其预训练学到的 Intermodal 特征。这样,在 Few-shot 任务中无需额外的 2D 输入,仅依赖 Intermodal 特征即可获益于多模态信息。
-
此外,该特征也隐式对齐了 VLM 的文本特征,为后续阶段利用重要的文本引导奠定基础。
-
两套 correlations 会通过 Multimodal Correlation Fusion (MCF) 进行融合,生成初始多模态 correlations,包含了 2D 和 3D 的视觉信息。这个过程可以表示为:
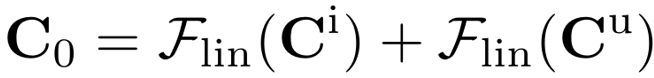
 和
和 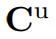 分别表示用 IF Head 和 UF Head 特征算得的 correlations。
分别表示用 IF Head 和 UF Head 特征算得的 correlations。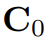 为 MCF 输出的初始多模态 correlations。
为 MCF 输出的初始多模态 correlations。-
当前获得的多模态 correlations 融合了不同的视觉信息源,但文本模态中的语义信息尚未被利用,因此设计了 Multimodal Semantic Fusion (MSF) 模块,进一步利用文本模态特征作为语义引导,提升多模态 correlations:

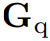 为文本模态的语义引导,
为文本模态的语义引导,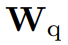 为文本和视觉模态间的权重(会动态变化以考虑不同模态间变化的相对重要性),
为文本和视觉模态间的权重(会动态变化以考虑不同模态间变化的相对重要性),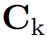 为多模态 correlations。
为多模态 correlations。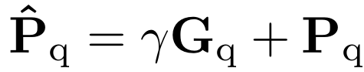
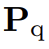 为模型的预测,为跨模态语义引导,γ 为适应性指标。通过借助 support point cloud 以及可用的 support mask 可以如下计算 γ 作为修正可靠程度的估计:
为模型的预测,为跨模态语义引导,γ 为适应性指标。通过借助 support point cloud 以及可用的 support mask 可以如下计算 γ 作为修正可靠程度的估计: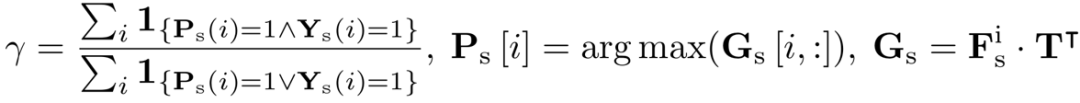
(文:机器之心)