
麻省理工学院施瓦茨曼计算学院(MIT Schwarzman College of Computing)举办的“拓展计算视野”系列讲座中,“深度学习日”邀请了麻省理工学院电气工程与计算机科学系副教授、计算机科学与人工智能实验室成员何恺明(Kaiming He)博士,就生成式模型(Generative Modeling)这一主题发表了精彩演讲。

何恺明博士首先介绍了生成式模型的概念及其广泛应用,包括文本生成、图像生成、视频生成(如Sora),以及在科学领域如蛋白质设计和天气预报中的应用。他强调了生成式模型与判别式模型的区别,并指出生成式模型的核心在于概率建模,即学习数据背后的潜在分布。
随后,何恺明博士深入探讨了深度学习在生成式模型中的作用,并介绍了当前主流的生成式模型方法,包括变分自编码器(VAE)、生成对抗网络(GAN)、自回归模型和扩散模型。他还特别强调了生成式模型作为“下一级抽象”的概念。最后,他通过多个实例,展示了如何将现实世界的问题(如自然语言对话、图像描述、机器人控制等)形式化为生成式模型,并强调了其广泛的适用性。 讲座深入浅出,为理解生成式模型提供了宝贵的视角。

纲要
生成式模型
├── 一、 介绍 (Introduction)
│ ├── 生成式模型 (Generative Modeling) 概述及其影响
│ ├── 生成式AI时代的应用举例 (ChatGPT, 文本生成图像/视频)
│ ├── 日常生活中的应用 (AI 辅助编程)
│ ├── 科学问题中的应用 (蛋白质设计, 天气预报)
│ └── 生成式模型的历史发展 (Photoshop 内容感知填充, 纹理合成)
├── 二、 什么是生成式模型?(What are Generative Models?)
│ ├── 生成式模型的特性
│ │ ├── 多种可能的预测
│ │ ├── 预测的合理性
│ │ ├── 分布外生成
│ │ └── 预测的复杂性
│ ├── 与判别式模型 (Discriminative Models) 的比较
│ └── 概率建模 (Probabilistic Modeling) 的重要性
├── 三、 深度学习与生成式模型 (Deep Learning and Generative Models)
│ ├── 深度学习是表示学习 (representation learning)
│ ├── 生成式模型中的深度学习
│ │ ├── 表示数据实例和概率分布
│ │ └── 分布之间的映射
│ └── 深度生成模型的要素
│ ├── 问题形式化
│ ├── 表示 (Representations)
│ ├── 目标函数 (Objective Functions)
│ ├── 优化器 (Optimizer)
│ └── 推理算法 (Inference Algorithm)
├── 四、 现代生成式模型方法 (Modern Approaches to Generative Models)
│ ├── 生成式模型为什么难?
│ │ ├── 无监督学习 (Unsupervised Learning)
│ │ └── 分布映射
│ └── 主要方法介绍
│ ├── 变分自编码器 (Variational Autoencoders, VAE)
│ ├── 生成对抗网络 (Generative Adversarial Networks, GAN)
│ ├── 自回归模型 (Autoregressive Models)
│ ├── 扩散模型 (Diffusion Models)
│ └── 流匹配 (Flow Matching)
├── 五、 将生成式模型应用于现实世界问题 (Formulating Real World Problems into Generative Modeling)
│ ├── 条件分布 p(x|y) 的解释 (y: 条件, x: 数据)
│ └── 不同应用场景下的 x 和 y
│ ├── 自然语言对话 (chatbot)
│ ├── 文本到图像/视频生成
│ ├── 3D 生成
│ ├── 蛋白质生成
│ ├── 无条件图像生成
│ ├── 图像分类与开放词汇识别
│ ├── 图像描述 (Image Captioning)
│ └──机器人策略学习
├── 六、 总结 (Conclusion)
│ ├── 生成式模型以深度神经网络为构建块
│ ├── 生成式模型是下一级的抽象
│ └──未来的发展:更高级别模型的构建块
└── 七、 问答环节 (Q&A)
├── 关于分类任务中生成模型与判别模型的比较
└── 关于 p(x|y) 的方向性和目标函数的问题讲座实录
一、 介绍 (Introduction)
大家好!今天我将和大家聊聊生成式模型 (Generative Modeling)。在座的各位,有多少人用过 ChatGPT 或者类似的工具?(停顿,观察听众反应)可能每个人都用过,对吧?那么,在接触 ChatGPT 之前,有多少人听说过“生成式模型”这个术语?(停顿,观察听众反应)嗯,还是有不少人了解的。
在这次演讲中,我将对生成式模型做一个高度概括的介绍,并探讨它如何影响我们的生活以及未来的研究方向。
毫无疑问,我们正处在一个所谓的“生成式AI”时代。对公众而言,这个时代可能始于 ChatGPT 或其他聊天机器人的出现。我们可以用自然语言与计算机交流,提出各种问题,它就像一个助手,帮助我们解决各种问题。但这并不是唯一的生成式AI模型。
另一个非常流行且强大的工具是“文本到图像生成”。用户可以给计算机一段文本,通常称为“提示词”(prompt),然后计算机会生成一张图片。例如……(切换幻灯片,展示“一只泰迪熊在黑板前讲授生成式模型”的图片)我希望这能正常工作……(调试设备)……抱歉,出了点小问题。

好,回到正题。例如,在这个例子中,提示词是“一只泰迪熊在黑板前讲授生成式模型”。计算机算法很可能以前从未见过这张确切的图像,但这就是它如何根据给定的文本提示生成图像的。
我们甚至可以更进一步,要求计算机算法生成一段视频。(播放 Sora 生成的纸飞机视频)这是由 Sora 在一年前生成的,非常令人印象深刻。我相信,可能没有哪个制片人会以这种方式拍摄视频,让这么多纸飞机在树林或森林上空飞翔。这完全是计算机算法想象出来的。
实际上,生成式模型可以成为我们日常生活中非常强大的生产力工具。例如,它仍然是一种聊天机器人,但它可以帮助我们编写代码。这是一个AI助手,它可以阅读你的代码,尝试修复代码中的问题,你可以直接用自然语言与助手交流,助手会将你的指令转换成代码。从某种意义上说,以前的编程语言可能是 C++、Python 或 Java,而下一代的编程语言可能就是英语,或者说人类的语言。
生成式模型的应用远不止计算机科学领域。实际上,它已经被用于许多科学问题中。例如,蛋白质设计与生成 (Protein Design and Generation)。我们的终极目标是设计或生成某种类型的蛋白质,来解决我们关心的问题,比如治愈某些非常危险或致命的疾病。这项工作被称为 RF diffusion,它实际上是今年诺贝尔奖得主工作的一部分。
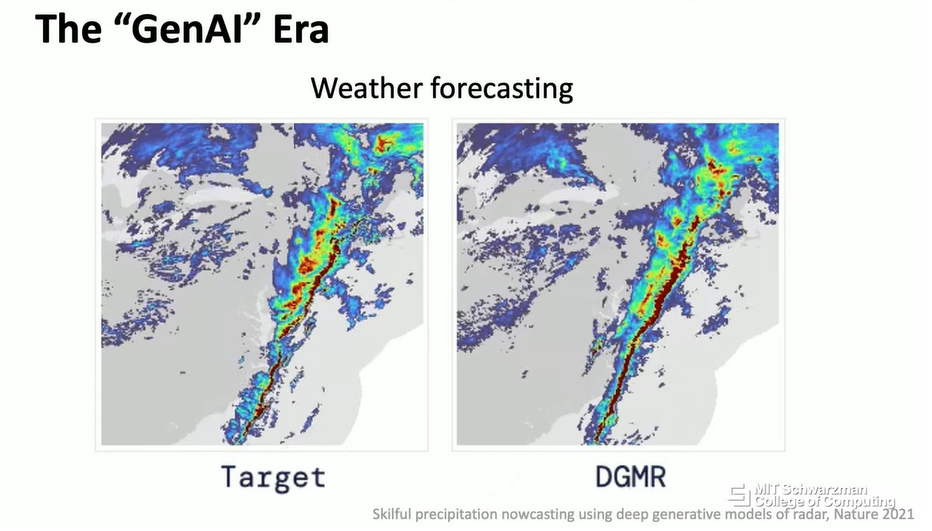
还有许多其他的科学问题可以从生成式模型中受益。这是 DeepMind 几年前的一项工作,他们可以使用这个模型来预测未来几小时或几天的天气变化。对于经典算法来说,这是一个非常困难的问题,因为我们知道,天气或气候的变化是混沌的,很难精确预测。我们可能不想要那一时刻的确切物理状态,我们想要的是一些定性的行为,比如那一时刻是否下雨或刮风。从这个意义上说,生成式模型或深度学习可以为这个问题提供一个很好的解决方案。
实际上,在生成式模型最近进入我们的日常生活之前,它已经被开发和应用了几十年。有一个工具叫做 Patchmatch,或者在 Photoshop 软件中被称为“内容感知填充”(Content Aware Fill)。当我还是博士生的时候,这是一个非常令人印象深刻的工具,当时我研究的正是同一个问题。这里的场景是,你会得到一张照片,用户可以指定照片中的某个区域或结构,计算机算法会尝试根据用户的指令修复或编辑照片。

事实上,在那个时候,还没有深度学习。老实说,对于这个应用或这个算法,甚至没有机器学习。这是一个非常经典的计算算法,但在概念上,这也是一种生成式模型。这项生成式模型背后的技术,实际上可以追溯到更早的10年前。这是一种叫做纹理合成 (Texture Synthesis) 的算法,它的目标是,给你一个纹理示例,你希望将纹理扩展到更大的图像,或者将纹理粘贴到你关心的某个 3D 对象上。这里的想法非常简单,你只需根据已经合成的内容,逐像素地合成纹理。在今天的语境下,这实际上就是一个自回归模型 (autoregressive model)。
二、 什么是生成式模型?(What are Generative Models?)
这就是我接下来要讲的内容。我将快速介绍生成式模型的概念,然后介绍一些现代方法,如何使用当今的深度神经网络构建生成式模型,以及如何将现实世界的问题形式化为生成式模型。

首先,什么是生成式模型?事实证明,这是一个非常困难的问题,因为当生成式模型变得越来越强大时,生成式模型的范围也在不断变化。即使我将介绍一些生成式模型的经典定义,我只想说,也许今天,每一个问题都可以被形式化为一种生成式模型。
现在,让我们看看刚才介绍的应用场景。这些场景有什么共同点?例如,图像生成、视频生成和文本生成,实际上,对于一个输入,存在多个预测,或者从概念上讲,存在无限个预测。假设你希望计算机生成一张猫的图像,你会告诉计算机“这是一只猫,我想要一只猫”。从概念上讲,存在无限多种可能的猫。
生成式模型的另一个特性是,某些预测比其他预测更合理 (plausible)。例如,如果你想要一只猫,计算机可能会生成一只狮子,也可能生成一只狗。根据常识,在这种情况下,狮子比狗更合理,当然,猫比狮子更合理。
生成式模型还有一个非常有趣的特性,你的训练数据可能不包含精确的解决方案。正如我们所看到的,我相信计算机从未见过一只泰迪熊站在黑板前讲授生成式模型,同样,计算机也肯定没有见过这些在森林上空飞翔的纸飞机。这是一种“分布外”生成 (out-of-distribution generation)。计算机算法是在某些数据上训练的,但它们生成的内容可能超出了训练数据的分布。
此外,大多数情况下,生成式模型的预测可能比它们的输入更复杂、信息量更大,从概念上讲,维度也更高。例如,在文本到图像生成中,如果你希望计算机生成一只猫,这只是一个很短的词,而输出图像将有数百万像素,甚至更多。
所有这些特性使得生成式模型比一些经典的深度学习或识别问题困难得多。
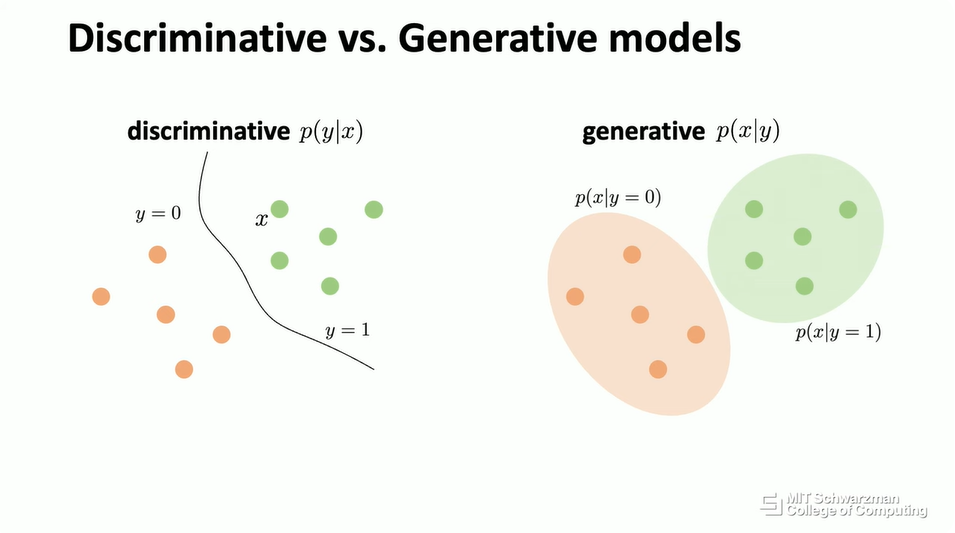
在教科书中,这是生成式模型的正式定义。通常,当介绍生成式模型时,人们会将其与所谓的判别式模型 (Discriminative Models) 进行比较。什么是判别式模型?正如你在这次演讲中看到的,如果我们关心图像分类问题,你会得到一张图像,然后你要训练一个模型,例如一个神经网络,你希望神经网络输出一个标签,比如说“狗”。从概念上讲,在这个非常简单的场景中,我们可以将生成式模型想象成逆转这个过程。
在这种情况下,你会得到一个“狗”的标签,然后你希望训练一个模型,同样,这可以是一个神经网络,然后你希望输出图像,也就是 x。在这种情况下,会有许多可能的输出,许多可能的狗。输出的维度会更高,输出会是你以前从未见过的另一只狗。
从概念上讲,这是判别式模型和生成式模型的一种概率可视化。左边是判别式模型,有一些绿点,代表一个类别,还有一些橙点,代表另一个类别。判别式模型的目标是找到一个可以分离这两个类别的边界,这似乎更容易。从概念上讲,任务是找出这个条件概率分布,这意味着你会得到 x,比如一张图像,然后你想要估计 y 的概率,比如它是标签 0 还是标签 1。
相比之下,在生成式模型的上下文中,你仍然会得到相同的数据,相同的点。但这里的目标是估计这些点的概率分布。假设在这个类别中,对应于 y=1,你想要估计这个类别的条件概率分布。从概念上讲,在生成式模型中,我们关心的是概率建模 (Probabilistic Modeling)。这是生成式模型想要解决的关键问题,也是关键挑战。
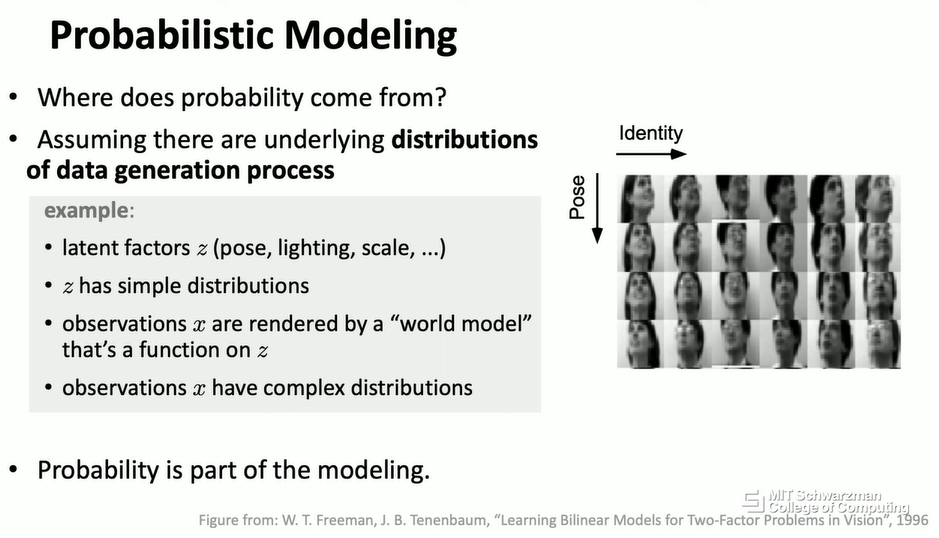
你可能会想,为什么,为什么会有概率?为什么我们关心概率建模?实际上,在许多现实世界的问题中,我们可以假设存在一些潜在的分布。你也可以假设你的数据实际上是由一些非常复杂的世界模型 (world model) 生成的。
例如,如果我们关心人脸图像,我们可以将问题形式化为存在一些潜在因素 (latent factors),比如姿态、光照、尺度,实际上还有人脸的身份。这些是潜在因素,然后你假设这些潜在因素存在一些分布。这些潜在因素会被一个世界模型渲染,例如,你如何将一个 3D 对象投影到一个 2D 像素网格上。然后,这些潜在向量将被这个世界模型渲染,而你实际能观察到的只是一个 2D 网格。
这就是观察值 x。然后,你的 2D 网格会遵循一些非常复杂的分布,这些分布不能简单地用一些潜在分布来描述。这就是为什么我们关心概率建模,而生成式模型正试图揭示这些潜在向量,以逆转这个过程。
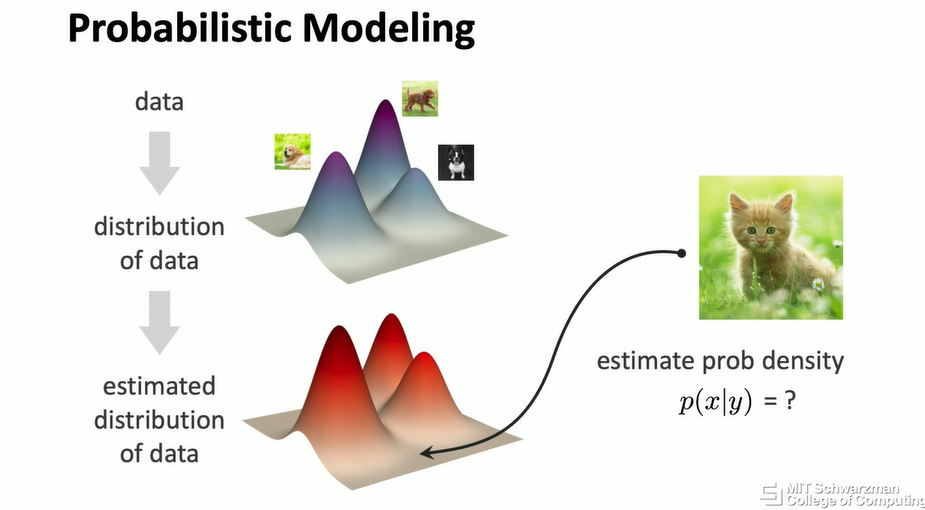
例如,假设我们有一些数据,假设我有一个狗的数据集,这意味着我有很多数据点,每个数据点对应一张狗的图像。从概念上讲,我们想象存在一个潜在的分布,可以对所有狗的分布进行建模。值得注意的是,这已经是你建模的一部分,因为你可以用许多不同的方式对潜在的世界生成器进行建模。即使我们经常假设存在这个潜在分布,这个分布也是建模的一部分。
然后,生成式模型的目标是学习一个神经网络,或者其他模型,来近似这个分布。假设这个红色分布是我们从神经网络中学到的,这里的目标是最小化数据分布和你估计的分布之间的距离。这仍然是一个非常困难的问题,有很多解决方案,但从概念上讲,几乎所有现有的生成式模型都可以用这种方式形式化,它们只是试图解决这个问题所暴露出的挑战。
从概念上讲,假设你的模型在这方面做得很好,那么你就可以开始从你估计的分布中进行采样 (sampling)。如果你的模型做得很好,这意味着当你从这个分布中采样时,你所做的在概念上类似于从原始数据分布中采样。在这种情况下,希望它会产生另一只你的算法从未见过的狗。
也有可能进行概率估计 (probability estimation)。也就是说,你的模型会得到另一张图像,比如说一只猫,然后你可以问模型,这张图像在原始数据分布下的可能性有多大。在这种情况下,如果原始数据分布是关于狗的,而输入图像是一只猫,那么希望它会产生一个较低的概率密度估计。
这就是我们如何使用概率建模来形式化生成式模型问题。
三、 深度学习与生成式模型 (Deep Learning and Generative Models)
正如你可以想象的那样,今天我们解决生成式模型最强大的工具是深度学习。Philip 已经对深度学习做了一个非常出色和快速的介绍。从概念上讲,简而言之,深度学习是表示学习 (representation learning)。
Philip 介绍的是学习表示数据,或者从概念上讲,表示数据实例的过程。这意味着你会得到数据,比如说图像,然后你想要将图像映射到标签。这是使用深度神经网络进行表示学习的一种方式。

在生成式模型中,实际上有另一种使用深度学习的方式,但仍然是为了表示学习的目标。也就是说,我们不仅要学习单个数据实例的表示,还要学习概率分布的表示。这是一个更复杂的问题,从概念上讲,它可以被视为学习另一种方式的映射。假设这里,输出是标签,比如说猫的标签或狗的标签,然后你想要将其映射回像素空间。
因此,正如你可以想象的那样,深度学习或深度神经网络是生成式模型的一个非常强大的工具。从概念上讲,当你将这个工具用于这个问题时,模型实际上同时扮演着这两个角色:首先,学习表示数据实例;其次,学习表示概率分布。
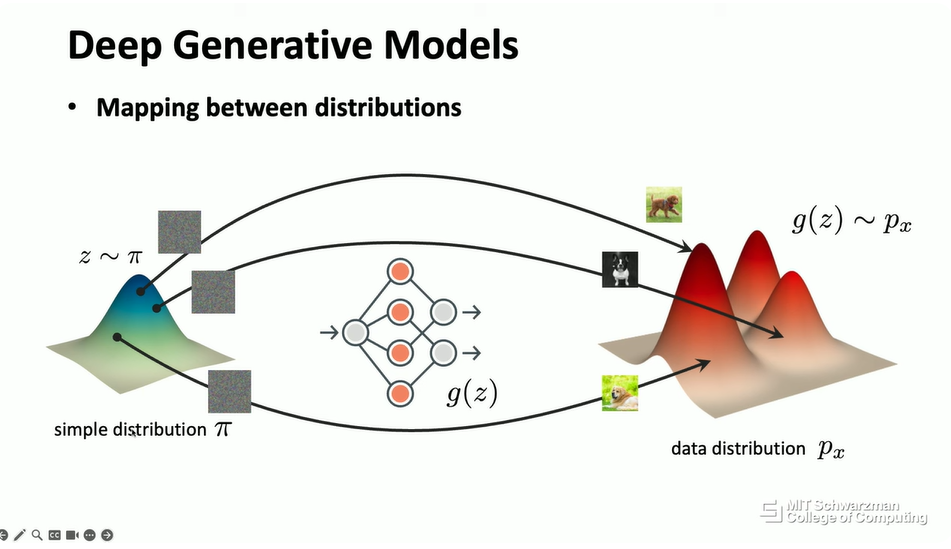
从概念上讲,这就是模型的样子。你的模型会得到一个非常简单的分布,例如,它可以是一个高斯分布,也可以是一个均匀分布,这无关紧要。在图像的情况下,这看起来就像一张完全嘈杂的图像。然后,目标是学习一个神经网络,使得它可以将嘈杂的图像映射到输出空间中的另一张图像。从概念上讲,如果你的模型可以做得很好,希望输出会是一张视觉上合理的图像,比如说,在这种情况下是一只狗。然后,你可以不断地从输入分布中采样噪声,希望神经网络会将所有内容转换成输出中有意义的图像。
从概念上讲,当你这样做时,实际上,你的神经网络正试图将一个简单的分布(例如这里的高斯分布)映射到另一个分布,从概念上讲,这是为了近似潜在的数据分布。从这个意义上说,生成式模型是分布之间的映射 (mapping between distributions),它不仅仅是一对数据点和一个标签之间的映射,它是从一个分布到另一个分布。
接下来的幻灯片会有一点技术性,也许我可以快速过一下。这些是深度生成模型的一些基本要素 (Fundamental Elements of a Deep Generative Model)。首先,你可能需要将现实世界的问题形式化为概率模型或生成式模型。这是我们设计算法最关键的部分之一。
在你完成之后,你需要一些表示 (Representations),今天,通常这是一个神经网络。你想要表示数据及其分布。然后,你需要引入一些目标函数 (Objective Functions) 来衡量两个分布之间的差异。然后,你需要一个优化器 (Optimizer),可以解决非常困难的优化问题。然后,你还需要一个推理算法 (Inference Algorithm),从概念上讲,这是一个采样器 (sampler),可以从潜在分布中采样。

今天,许多数学和理论研究都与这个列表中的一个或多个要素有关。我不打算深入细节,但接下来我将对生成式模型的一些现代方法和流行方法做一个非常高层次和快速的概述。我还将解释为什么生成式模型是一个难题。
四、 现代生成式模型方法 (Modern Approaches to Generative Models)
这是你刚刚看到的图。如你所见,这里的问题是,如果你的模型得到一张嘈杂的图像或嘈杂的输入,你希望它将噪声映射到输出图像。为什么这很难?回想一下,在 Philip 的演讲中,他谈到了监督学习的问题。在这种情况下,你会得到一张图像,以及该图像的标签,你有一对输入和输出。这是一个形式化非常好的监督学习问题,这个问题对于现代神经网络来说很容易解决。
但在生成式模型中,从概念上讲,这是一个无监督学习 (Unsupervised Learning) 问题。也就是说,你会得到一张图像,但从概念上讲,你不知道什么输入噪声会对应于那张图像。这种对应关系或配对问题也是你的底层算法应该尝试解决的问题。从这个意义上说,从概念上讲,这不仅仅是映射图像对或数据对,而是映射两个分布。你想要将一个简单的高斯分布映射到一个非常复杂的数据分布,这就是为什么生成式模型很难。
有许多有效且非常聪明的算法可以解决这个问题。我将从一些非常基本和优雅的算法开始,然后我将开始讨论一些当今最先进的算法。
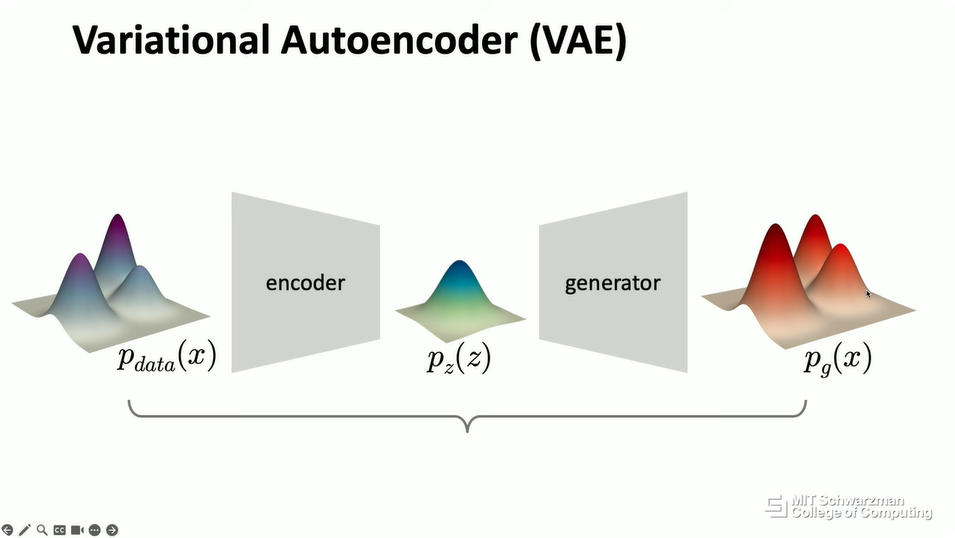
首先,我将讨论变分自编码器 (Variational Autoencoders, VAE)。从概念上讲,在生成式模型中,正如我们已经介绍过的,你想要将输入分布映射到输出分布。然后,我们可以将其形式化为一个自编码 (autoencoding) 问题。这意味着,如果你有数据的分布,那么你可以训练另一个神经网络,将数据分布映射到你喜欢的分布,比如说高斯分布。然后,在你得到这个分布之后,你可以学习生成器将其转换回来。从概念上讲,你计算输入和输出之间的距离。
这是深度学习中非常经典的自编码思想。但在经典算法中,通常从概念上讲,这会被应用于数据实例的概念,也就是说,你将其应用于每一张图像。在变分自编码器中,从概念上讲,自编码的概念被应用于分布。你可以想象这个分布只是一个对象,只是一个你想要处理的实体。你将这个对象转换成这个更简单的对象,然后你再将其转换回来。这就是自编码的思想。
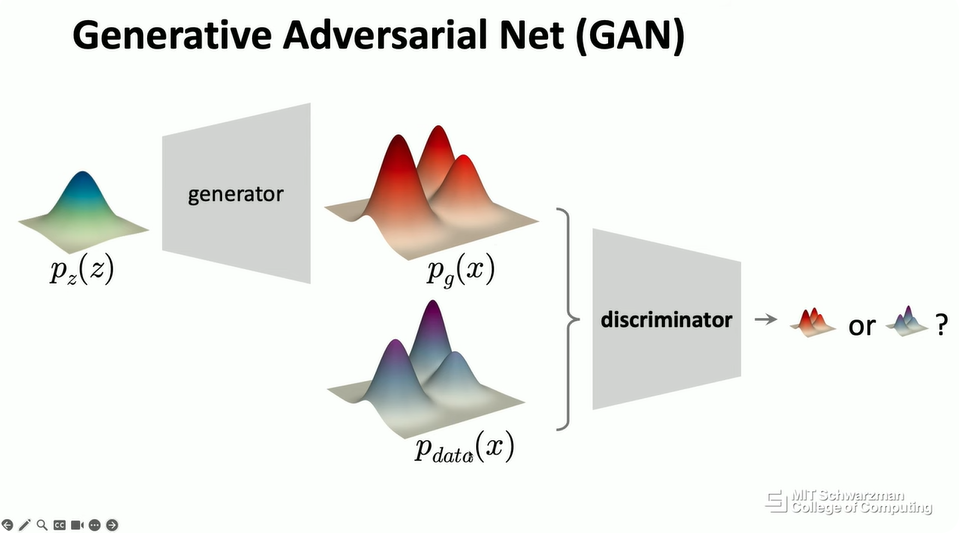
另一个非常流行的解决方案,可以说是 10 年前生成式模型研究的开端,叫做生成对抗网络 (Generative Adversarial Networks, GAN),简称 GAN。从概念上讲,GAN 也只是想学习一个生成器,从一个简单的分布到数据分布。但 GAN 并没有在简单分布之前引入另一个网络,而是在你获得估计分布之后引入了一个额外的神经网络。这个额外的神经网络被称为判别器 (discriminator)。判别器的目标是判断你的样本是来自预测分布还是来自真实分布。如果判别器无法判断它来自哪个分布,那么这意味着这两个分布将非常相似。
GAN 是过去十年中最流行和最强大的生成式模型,直到过去三四年出现了一些非常强大的工具。
另一个非常强大的生成式模型工具叫做自回归模型 (Autoregressive Models)。在自然语言处理的上下文中,这通常被称为“下一个词预测”(next token prediction)。但从概念上讲,自回归或自回归的思想不仅仅是预测下一个词。基本上,如果我们关心涉及许多元素或许多变量的概率,那么根据概率论的基本原理,我们总是可以将这个联合概率分解为一系列条件概率。
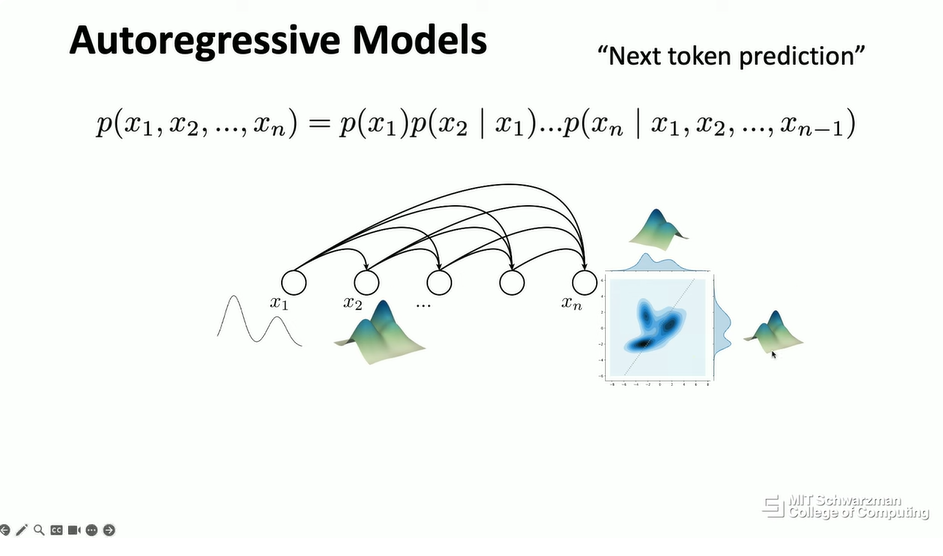
自回归模型的关键思想是分别对每个条件概率进行建模,而不是对整个联合概率进行建模。如果你按照序列的顺序进行这种分解,假设在这种情况下,你想要首先预测 x1,然后预测 x2,条件是 x1,依此类推,如果你遵循这个顺序,那么你可以将你的问题转化为下一个词预测。
自回归模型的思想是将一个非常复杂的问题分解为一堆更简单、更小的问题。例如,在这种情况下,在第一个输出中,你将估计一个非常简单且低维的分布。在这个例子中,例如,这将是一个一维分布。然后在第二个节点中,它将预测变量的下一个维度。然后,它将是一个二维分布,依此类推。很难可视化更高维的分布,但从概念上讲,当你这样做时,这将是一个高维空间中的分布。这是自回归模型的关键思想。
然后,在过去的三四年里,出现了一种非常强大的模型,特别是在图像生成和计算机视觉领域。这个模型的灵感来自物理学中的热力学。其思想是,你可以将问题形式化为通过添加高斯噪声来反复破坏干净的数据或输入图像,然后你可以逐步将其转换为完全噪声的图像。然后,学习的目标是逆转这个过程。如果你能做到这一点,那么你就可以逐步从嘈杂的输入回到干净的图像。这个想法被称为扩散 (diffusion),或者通常也被称为去噪扩散 (denoising diffusion)。
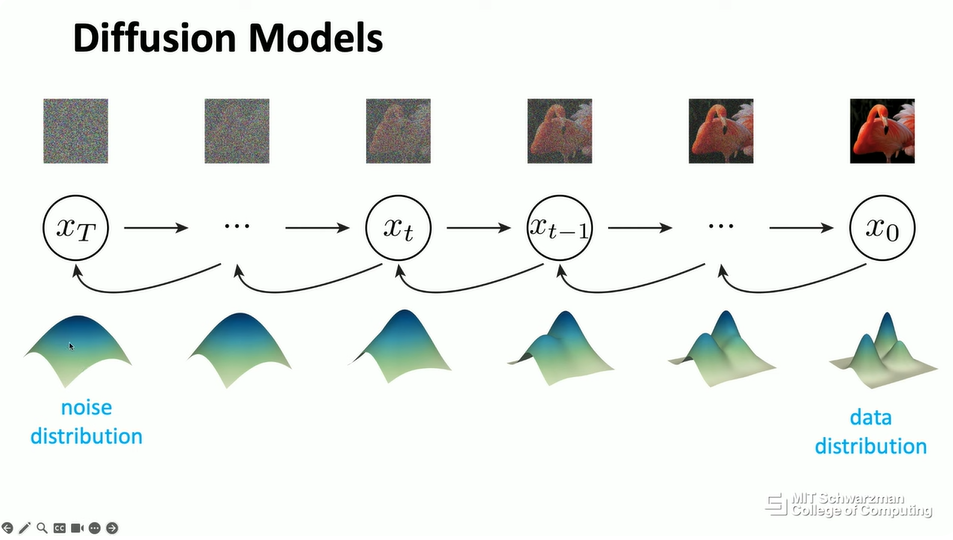
从概念上讲,使用概率或概率分布的术语,这意味着你将有一个输入数据分布,希望它是关于干净图像的。然后,你只需在其上反复添加噪声。从概念上讲,这就像在分布空间上运行一个卷积核。通过多次这样做,最终你将把数据分布转换为高斯分布。然后,你的模型只是试图学习逆转这个过程。
这是扩散模型在推理时的样子。它将从一个非常简单的分布开始,比如说高斯分布。然后,它将逐步逆转这个过程,回到数据分布。实际上,这种可视化与图形学中流行的许多概念非常相似。例如,你可以想象这个过程的起点是一些圆锥形的形状,比如说一个球体或一个圆柱体。然后,你想要逐步变形或扭曲这个对象、这个形状,变成你喜欢的另一个形状。假设这可以是,例如,一座山或一只兔子。
你想要逐步将输入球体扭曲成一只兔子,这是一个研究得很好的问题。在分布建模的情况下,我们可以将这个分布字面上想象成一个几何实体。然后,你可以形式化一个过程来进行这种转换。实际上,我刚才描述的是一种新兴的思想,叫做流匹配 (Flow Matching)。你想要从一个非常简单的对象或非常简单的形状(如球体)流向另一个更复杂的形状(如兔子)。如果你有这个算法,然后如果你将你的底层形状形式化为一些概率分布,那么你就可以使用这个思想来进行概率建模,也就是生成式建模。
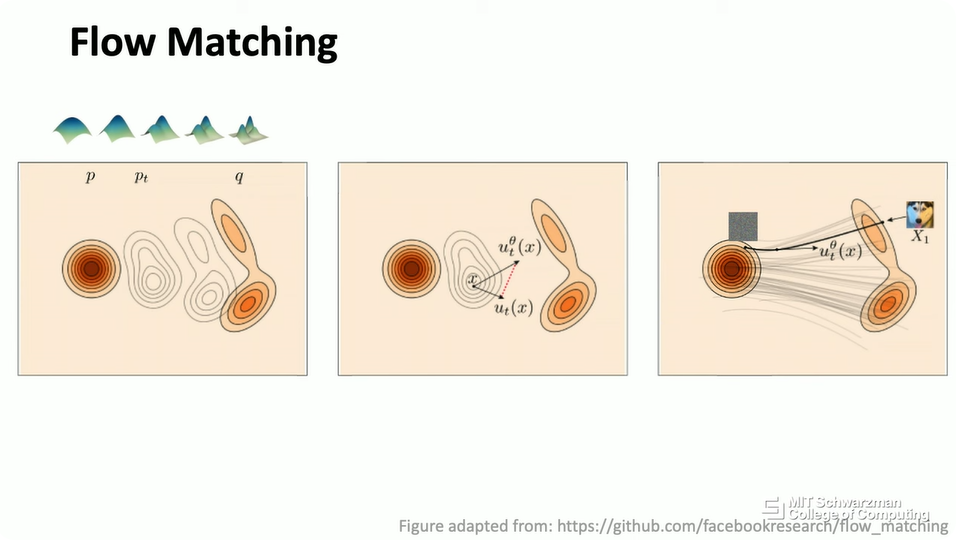
从概念上讲,这只是同一件事的另一种可视化。你将从一些简单的分布开始,比如说高斯分布。这将是你想建模的数据分布。这里的目标是逐步将你的输入分布更改为输出分布。然后,在计算机图形学中,有许多优秀的解决方案可以解决这个问题。这里的一个想法是学习一个流场 (flow field)。你可以想象,如果这实际上是一个 3D 对象,那么你将有一些 3D 顶点或 3D 表面。你想要逐渐将这些 3D 表面从球体移动到兔子中的一些 3D 表面。如果你这样做,那么将有一个流场可以通过这个过程构建。背后会有很多数学细节,当然,我不会深入探讨,但这是生成式模型最新进展的高层思想,也就是流匹配。
从概念上讲,这些是当今生成式模型的一些流行方法。我没有涉及任何数学细节,但浏览所有这些方法是很有趣的。我想说明的一点是,在所有这些生成式模型中,都会有一些深度神经网络作为构建块。这就像在深度神经网络中,会有一些层作为构建块。这些层是 Phillip 刚刚介绍过的模型。它们可以是线性层,可以是 ReLU,可以是归一化层或 softmax 层。

神经网络是由所谓的层构建的一些实体。而今天,这些生成式模型是由深度神经网络构建的一些实体。从这个意义上说,生成式模型是下一级的抽象。
五、 将生成式模型应用于现实世界问题 (Formulating Real World Problems into Generative Modeling)
接下来,我将讨论如何在解决现实世界问题的背景下使用这些数学模型或生成式模型的理论模型。正如我们已经介绍过的,生成式模型中的关键问题是关于这个条件分布。你想要建模一个分布,从概念上讲,你会得到条件 y,这是关于你的数据 x 的分布。但在现实中,什么是 y,什么是 x?

在通用术语中,y 被称为条件 (conditions)。假设你想要生成一只猫,它也可能是一些约束 (constraints),假设你不希望生成某种类型的输出图像。它也可能是标签 (labels),文本标签,或者其他标签。它也可能是属性 (attributes),假设你想要生成一个大的对象或一个小的对象。
在大多数情况下,条件 y 会更抽象,信息量也会更少。相比之下,输出 x 通常被称为数据 (data),或者它是你在现实世界问题中可以看到的样本的观察 (observations) 或测量 (measurements)。在图像生成的情况下,通常 x 就是图像。通常,x 会比条件 y 更具体,信息量更大,维度更高。

现在,让我们回顾一下我们刚刚介绍过的应用,并讨论什么是 x,什么是 y。在自然语言对话或聊天机器人的上下文中,条件 y 是用户给出的所谓提示 (prompt),输出 x 是聊天机器人的响应。通常,输出的维度更高,并且会有许多合理的输出可以对应于同一个提示。

同样,在文本到图像生成或文本到视频生成的上下文中,条件将是文本提示,它可以是一个句子,可以是一个类标签,可以是一些属性。输出将是生成的视觉内容,例如图像和视频。输出的维度更高,更复杂。这些是典型的用例。
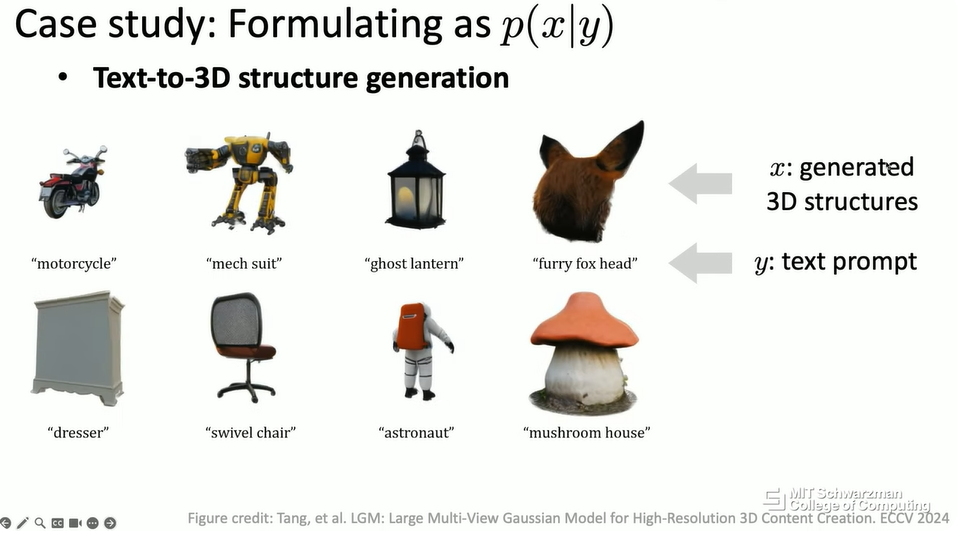
当然,在 3D 生成方面也是如此。在这种情况下,条件仍然是一个文本提示,输出将是 3D 文本结构。在计算机视觉或图形学应用中,3D 文本结构将是形状、纹理,甚至可能是底层对象的光照。
然后,我们可以更进一步,将场景推广到蛋白质生成的问题。在这种情况下,输入条件仍然可以是一些提示,仍然可以是一些文本。假设你可以尝试告诉计算机,我想生成一种可以治愈癌症的蛋白质。这是有效的,但问题是,计算机无法理解“治愈癌症”是什么意思,或者它能做什么来治愈癌症。
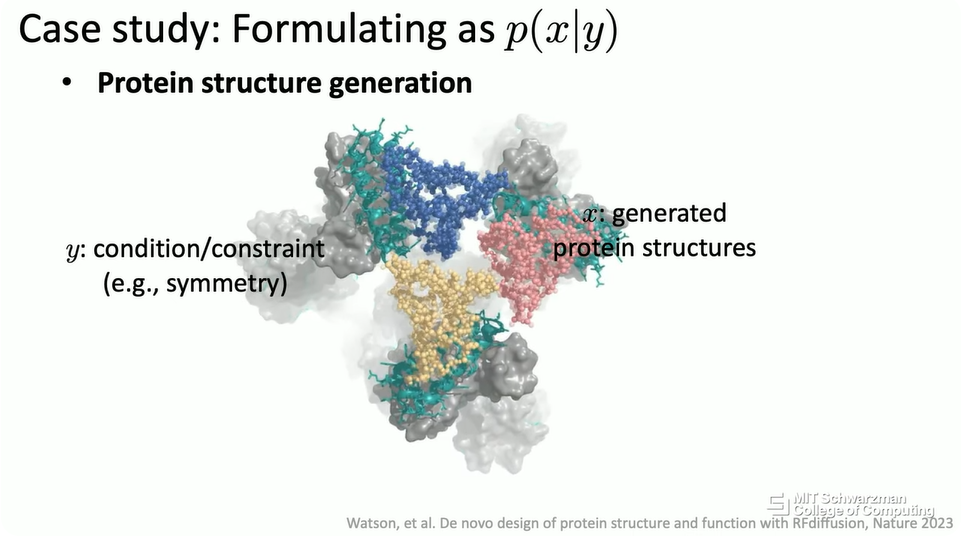
在这种情况下,关于如何表示你关心的潜在条件,会有很多研究。你希望你的输出蛋白质具有某些属性,你希望这些属性与治愈癌症或治愈某些特定疾病有关。在这种情况下,条件会更抽象,它也可能是更高维的,因为它是某些行为的抽象,比如说治愈癌症。输出将是另一种表示,也是高维的,比如说 3D 中的蛋白质结构,它就像另一种 3D 对象。
然后,让我们谈谈一些其他的场景,通常,人们不会认为它们是生成式模型。假设这是一个非常经典的例子,人们会将其视为我们介绍过的判别式模型。哦,抱歉,不是这个。这是图像生成的典型例子。你会得到一个类标签,然后你的算法会被要求生成输出图像。这就是所谓的类条件情况,这意味着你的 y 将非常具体地针对一个标签。

但还有另一种情况,你可以想象你不会得到任何条件。这意味着你想要生成一个数据输出,该输出将遵循数据的整个分布。在这种情况下,你可以将潜在条件想象成一个隐式条件,这意味着你希望图像遵循你的底层数据集的分布。如果你的模型在这方面可以做得很好,那么它将尝试区分这个数据集的分布与任何其他数据集的分布。

好,这就是我刚才混淆的例子。这是我们可以将生成式模型应用于判别式模型场景的想法。这是一个非常典型的监督学习或判别式学习的例子,也就是图像分类。你会得到一张图像,然后你想要估计该图像的标签。如果我们要将其形式化为生成式模型,那么在这种情况下,实际上 y(在之前几乎所有例子中都是标签)在这种情况下将是图像。在这种情况下,图像是你的条件。然后,类标签 x 将是预测的输出。你想要对输出的概率分布进行建模。
仅仅因为这个问题太简单、太琐碎,通常人们不会将其视为生成式模型,但它可以是。那么,这里的重点是什么?如果你可以将图像分类建模为生成式模型,那么实际上,你可以将场景从闭集词汇表分类(这意味着你会得到一组预定义的类标签)扩展到开放词汇表识别 (Open Vocabulary Recognition) 的场景。这意味着你不会得到一组预定义的类标签。这意味着对于同一张图像,可能有许多合理的答案。在这种情况下,你仍然会得到一张图像,但你的输出不再是一个唯一的正确答案。可能有许多不同的可能答案可以描述这张图像。

例如,在这种情况下,这些都是合理的答案,可以说这是一只鸟或一只火烈鸟,这是红色或橙色。正如你所看到的,即使对于这个非常经典的图像分类问题,如果我们尝试将其形式化为生成式模型,它也可以开启新的机会,并且将启用新的应用,这对于经典的判别式模型来说是不典型的。
我们甚至可以更进一步。你可以想象输入条件 y 仍然是一张图像,你希望输出不仅仅是一个标签或一个简短的描述,它可以是一个完整的句子,甚至可以是一些可以描述这张图像的段落。实际上,这也是计算机视觉中的一个经典问题,被称为图像描述 (Image Captioning)。你希望计算机为这张图像写一个标题。

然后,在这种情况下,我们甚至可以更进一步。这张图像可能只是你在对话中、在你与聊天机器人的自然语言对话中的输入的一部分。在这种情况下,条件将是输入图像和一些其他的文本,也就是用户给出的一些其他的文本提示。输出将是聊天机器人基于这张图像和文本提示的响应。假设在这种情况下,给定这张图像,用户可能会问,这张图像有什么不寻常之处?聊天机器人可以尝试提出一些关于这个问题的答案。它说,把衣服熨在固定在行驶中的出租车车顶上的熨衣板上是不寻常的。

在许多其他的现实世界问题中,例如机器人技术,我们也可以将策略学习的问题形式化为生成式模型。例如,在机器人控制中,可能有许多合理的轨迹、许多合理的策略可以完成相同的任务。在这种情况下,例如,你希望机器人将这些 T 形物体移动到它们的目标位置。机器人可以从右侧移动,也可以从左侧移动。这两种轨迹都是合理的,没有唯一的答案。这也是我们可以使用生成式模型来建模这个策略学习问题的地方。
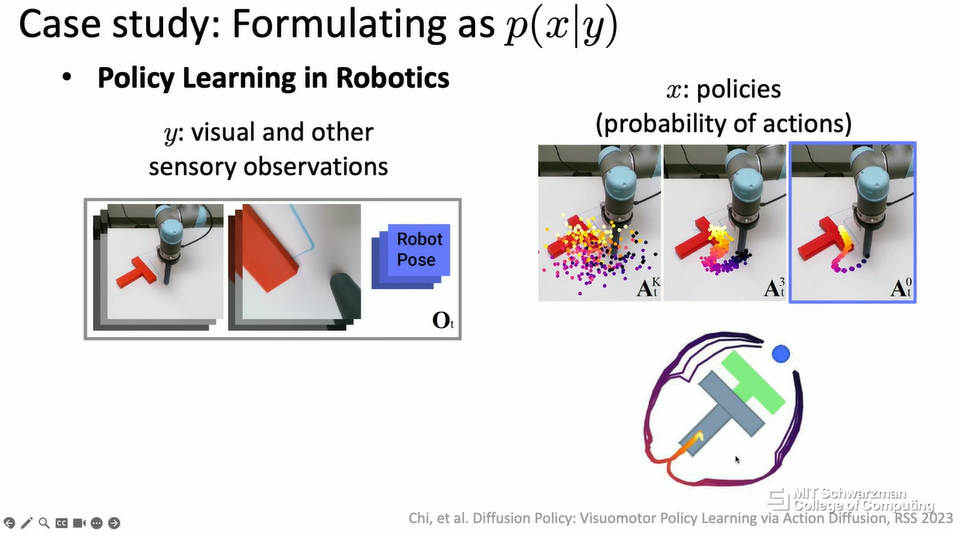
总的来说,这就是我们刚才看到的。生成式模型从概念上讲,只关心这个条件分布。在我看来,实际上,对于什么是 x 或什么是 y,没有任何约束或要求。从概念上讲,它们可以是任何东西。这意味着我们可以使用生成式模型来解决许多种类的现实世界问题。我们可以尝试将所有这些现实世界问题形式化为某种条件分布问题,然后我们可以尝试应用生成式模型的最新进展作为解决这个问题的工具。这也是为什么生成式模型在今天变得越来越普遍的部分原因,人们用它来解决现实世界的问题。


六、 总结 (Conclusion)
这将是这次演讲的最后一张幻灯片,但我只想给出一些高层次的想法,并传达一些我认为最重要的信息。正如我们所看到的,生成式模型有一些深度神经网络作为它们的构建块。这就像深度神经网络有一些层作为它们的构建块。10 年前,深度学习的研究主要围绕这些层,比如说卷积、激活函数、归一化、自注意力层等等。那是大约十年前的研究。

然后,我们有了生成式模型,生成式模型成为下一级的抽象。所有先前关于深度神经网络的研究仍然适用,但有一个新的研究层次将围绕生成式模型构建。
展望未来,当人们使用这些生成式模型来做更多惊人的事情时,比如说大型语言模型、推理、智能体,以及机器学习(我们将在这次演讲的其余部分中介绍),在这种情况下,这些现有的生成式模型将成为另一级的构建块。正如我们可以看到的,正如你从 Philip 的介绍幻灯片中看到的那样,我们正在构建一个由许多不同层次的模型组成的堆栈。
这些是不同层次的抽象。抽象可以是层,可以是深度神经网络,它们可以是生成式模型,也可以是推理智能体。这就是过去一个世纪左右计算机科学进步的方式。人们正在构建不同层次的抽象,然后我们可以解锁不同层次的新机会。从这个意义上说,我想说生成式模型是下一级的深度学习,也是下一级的抽象和构建块。
七、 问答环节 (Q&A)
-
• 观众 1 提问: 既然建模主要是映射分布,那么对于像分类这样的简单任务,是不是一个更难解决的问题?因为你在映射概率分布,这是一个更复杂的任务。这是否意味着它们在简单任务上表现更差? -
• Kaiming He 回答: 你是说生成式模型在简单的监督学习任务上表现更差吗?我认为目前还没有确定的答案。因为在某种意义上,我认为使用生成式模型来解决判别式问题还没有成为一种普遍的共识。如果这是一个非常简单的,比如说,闭集词汇表分类任务,如果你非常清楚地知道你有 10 个可能的标签或 1000 个可能的标签,那么通常一个简单的解决方案就足够了。但是,即使在所谓的开放词汇表识别的情况下,比如说,你会得到一张图像,你仍然想要一个标签,比如说一个主题标签。那么你仍然可以有一个词汇表,但那个词汇表只是英语词汇表,人类的词汇表,它可能非常长。即使在这种情况下,我认为生成式模型也是一个好主意。然后,如果你想更进一步,你想要一个句子作为描述,或者如果你想要一些基于这张图像的对话,那么生成式模型可能是你应该使用的唯一解决方案。 -
• 观众 2 提问: 非常精彩的演讲。我有两个问题。当我们谈论给定 y 时 x 的概率时,这似乎是单向的。我想知道你对双向的可能性有什么看法。其次,在蛋白质合成的情况下,是否要求我们至少有一个明确的目标,也就是说,我们确切地知道如何启动?是否可能有一个明确的目标函数范围,有能力……(问题未说完) -
• Kaiming He 回答: 好问题。第一个问题是,是否可以反向进行?我认为这取决于具体的方法。我认为最近,答案是肯定的。流匹配算法可以让我们做到这一点。正如你可以想象的那样,在我的类比中,如果你把流匹配想象成从一个球体移动到一个兔子,那么从概念上讲,它不需要是一个球体,它可以是一只猫。你可以从一只猫变形到一只兔子。在这个类比中,这意味着你可以从一个任意分布转换到另一个任意分布。然后它们的位置是对称的。所以从概念上讲,你可以交换它们,对吧?这是第一个问题。第二个问题是,如果我没记错的话,是关于机器人场景的。是否存在一个明确的目标函数?或者它是否可以在不明确的情况下工作?(问题未说完) -
• 观众 2 补充: 是的(目标函数不明确的情况)。 -
• Kaiming He 回答: 是的,好问题。我认为这更像是强化学习和模仿学习之间的区别,或者基本上就是监督学习。我认为从概念上讲,我们总是可以将问题形式化为强化学习。也就是说,你只想接近目标。假设目标是将 T 形物体移动到目标位置,如果你能做到,你就会得到奖励。如果你做不到,你就什么也得不到,或者你的奖励是零。这是可能的。然后,模仿学习或监督学习是另一种方式。你试图给出一些可能的轨迹的例子,然后你试图模仿这种行为。是的,我想我可以在线下回答问题,因为我已经超时了。让我们继续下一个演讲。
引用链接
[1] Deep Learning Day: Generative Modeling: https://www.youtube.com/watch?v=2yJSoaGU2i4
 一起“点赞”三连↓
一起“点赞”三连↓
(文:Datawhale)