
-
• 论文标题:LaRA: Benchmarking Retrieval-Augmented Generation and Long-Context LLMs – No Silver Bullet for LC or RAG Routing -
• 论文地址:https://arxiv.org/abs/2502.09977 -
• 开源地址: https://github.com/Alibaba-NLP/LaRA
**背景:**RAG与长文本语言模型的权衡
随着大型语言模型(LLMs)的快速发展,输入长度限制从最初的4K token到如今普遍支持的128K甚至百万级token输入,”长文本”(Long Context, LC)的定义也在发生着巨变。检索增强生成(RAG)技术曾经作为处理超长文本的关键解决方案,通过检索与问题(query)相关的文本片段来满足输入长度的限制。然而,随着模型上下文窗口的显著扩展和长文本处理能力的质的飞跃,一个富有挑战性的问题浮出水面:在当前LLMs已具备如此强大的长文本理解能力的背景下,RAG是否仍然是处理长文本必不可少的方案?
尽管LLMs在长文本处理能力上取得了显著进展,但我们不能忽视其固有的局限性。长文本处理不仅带来了显著的计算开销,还面临着事实准确性降低、幻觉产生概率增加、专业领域适应性不足,以及容易生成过于宏观和笼统答案等挑战。特别值得注意的是,在超长文本(超过100K tokens)的场景下,RAG与LC LLMs在不同任务类型和上下文类别中的相对优势仍然缺乏系统性的研究和定论。考虑到RAG在计算效率上的显著优势,如果能够准确预判在特定场景下哪种方案更具优势,就能在系统性能和计算资源消耗之间找到最优的平衡点。近日,阿里巴巴通义实验室RAG团队联合香港科技大学与宾夕法尼亚州立大学提出了一套创新的RAG与LC LLM系统性比较框架,为高效设计RAG与长文本处理路由机制提供了全新思路。
已有研究回顾
本篇论文首先回顾了关于RAG和LC LLM的先前研究,发现现有文献尚未就二者优劣达成一致结论。不同研究在各种基准测试和实验设置下得出了截然不同的结果。
早期研究主要采用了LLM时代之前的问答数据集,如Qasper、NarrativeQA和QuALITY等。例如,[1]在这些数据集上进行广泛实验后发现,对于Llama2-70B和GPT-43B等较大模型,RAG表现普遍优于长上下文方法。而[2]则通过整合这些数据集创建了一个新的benchmark得出了相反的结论。然而这些早期数据集普遍存在两个关键问题:(1)上下文长度不足,难以满足当前对”长上下文”的定义要求。QASP和QLTY的平均长度分别仅为4912和6592个tokens。一方面主流LLM已经能处理128k甚至1M的上下文,另一方面现代RAG系统通常使用300-600个token的chunk大小,检索5-10个chunk,使得RAG与长上下文LLM在总体上下文规模上已无显著差异;(2)早期数据集可能已被广泛用于LLM的训练,存在数据泄露问题。例如,研究表明Gemini-1.5-Pro在NQ(Natural Questions)数据集上能达到100%的准确率,几乎可以确定存在数据泄露现象[2]。
近期的长文本benchmark也难以有效地比较RAG和长上下文能力。以最近被广泛用于比较两种方法的∞-Bench为例,[3]和[4]分别在其英文问答(En.QA)和英文多选(En.MC)任务上进行实验,却得出了完全相反的结论:前者认为长上下文LLM更强,后者则支持RAG表现更佳。然而,这两个任务的平均文本长度分别高达192.6k和184.4k tokens,远超大多数LLM的上下文限制。为适应输入要求,研究者不得不采用截断操作,但这可能导致问题答案被意外截除,使得答案不再存在于提供给LLM的上下文中,从而无法真实反映LLM处理长文本的能力。为验证这一假设,研究者采用了如下方法:将超长上下文分段输入LLM,并修改prompt允许模型在无法确定答案时拒绝回答。在多次分段输入后,通过多数投票机制确定最终答案。实验结果表明,通过这种方法,长上下文LLM的性能获得了显著提升,更准确地反映了其真实能力(下表中vote项)
此外,先前研究主要依赖F1-score、Exact Match (EM)等自动评估指标,但这些方法存在准确性不足的问题。例如,当标准答案为”Allyson Kalia”,而模型预测为”Allyson Kalia is convicted of the murder of Kiran’s younger brother, Rosetta.”这样一个实质正确但提供了额外信息的回答,仅能获得0.29的F1分数,严重低估了模型的实际表现。将∞-Bench的评估方法从自动化指标转变为LLM评估后,模型得分显著提升(下表中LLM项)。这一发现表明,以往研究中使用的长文本数据集可能并没有指标所显示的那么具有挑战性,传统评估方法可能系统性地低估了模型处理长文本的真实能力。

尽管许多其他长文本benchmark都对RAG和LC LLM进行了比较,但由于这些benchmark的设计初衷主要是评估模型的长文本处理能力,而非专门针对两种方法的对比,导致其任务设计和上下文选择并未充分模拟真实RAG应用场景。这使得它们难以真实反映在实际使用环境中RAG与LC的相对优势,也无法为规划系统的设计提供有效指导。
LaRA Benchmark
为了系统地比较RAG和LC LLM的性能,研究者设计并构建了LaRA benchmark。LaRA的开发过程分为四个关键阶段:长文本收集、任务设计、数据标注和评估方法制定。以下将详细介绍LaRA的各个构建环节。
长文本收集
LaRA基准测试的长文本收集遵循四个核心原则:
-
1. 时效性:优先选择新近发布的高质量长文本,最大限度地降低这些文本被用于LLM训练的可能性,从而避免数据泄露问题。 -
2. 长度适配:考虑到主流开源和商业模型的能力范围,研究者设计了32k和128k两种上下文长度规格。每个文档的长度都被控制为接近但不超过这些阈值,从而避免在测试过程中需要进行截断处理。 -
3. 自然性:所有文本均为天然长文本,而非人工拼接无关短文本或构造的伪长文本,确保实验结果能够真实反映模型在自然长文本环境中的表现。 -
4. 权威性:所有长文本均来自可靠权威的来源,保证内容创作者具备相应的专业知识、声誉和资质
基于上述原则,研究者选取了三类代表性文本作为上下文材料:
-
1. 小说文本:分别选取中篇和长篇小说作为32k上下文测试材料。为防止数据泄露,研究者设计了多阶段的基于LLM的人物实体识别和替换机制,确保测试内容与模型训练语料存在显著差异。 -
2. 财务报告:选取美国上市公司2024年最新发布的年报和季报,分别用于32k和128k上下文长度测试,保证数据的新颖性。 -
3. 学术论文:通过拼接多篇2024年发表的具有引用关系的相关论文,构建连贯且内容相关的学术长文本。
任务设计
LaRA设计了四种核心任务,全面系统地评估RAG和长上下文LLM在不同能力维度上的表现:
-
1. Location(定位)任务
主要评估模型的精确信息检索和单点定位能力。在这类任务中,问题的答案可以在文本的特定位置直接找到,无需复杂推理。测试模型能否在长文本中准确定位并提取关键信息。 -
2. Reasoning(推理)任务
要求模型进行逻辑推理或数学运算,答案无法直接从文本中获取。例如,模型需要对财务报告中的数据进行进一步计算,或基于文本中的信息进行逻辑推导,才能得出正确答案。 -
3. Comparison(比较)任务
测试模型在长文本中定位、整合并比较多处信息的能力。模型需要找到文本中分散的相关信息点,进行对比分析,才能正确回答问题,考验模型的全局理解和信息整合能力。 -
4. Hallucination Detection(幻觉检测)任务
评估模型识别无法回答问题并拒绝作答的能力。这类任务中的问题表面上与上下文相关,但实际上文本中并未提供足够信息或根本未涉及该问题。模型需要准确识别这种情况并拒绝回答,而非生成可能的幻觉内容。
数据标注
LaRA采用了GPT-4o与人工协同标注的方式生成高质量的问答对(QA pairs)。研究团队首先为每种上下文类型和任务类别人工设计了独立的Seed QAs和prompt,然后利用这些种子问答引导GPT-4o基于提供的上下文生成新的问答对,通过人工采样的方式验证生产质量和通过率,然后进一步优化调整Seed QAs和prompt,重复这个过程达到较高的生成质量。详细的prompt设计和生成流程可参考论文附录。
长文本标注本身就是一项复杂的长文本任务,为了有效解决这一挑战,研究者采取了以下策略:
-
1. 分段处理法 -
• 对于Location和Reasoning任务,研究者将完整长文本拆分为多个约10k tokens的短文本片段,然后针对每个片段生成对应的问答对。 -
• 这种方法带来两个显著优势: -
• 确保生成的问答对均匀分布在全文各处,增强了数据分布的多样性,同时支持”lost-in-the-middle”实验 -
• 将复杂的长文本处理转化为短文本处理,显著提高了生成质量 -
2. 多段输入法
-
• 对于Comparison任务,研究者一次输入多个文本段落,要求模型基于多段内容生成需要比较的问题 -
• 这种方法还支持探究模型性能与比较信息之间距离的关系
-
3. 文本拆分策略
-
• 小说和财报采用均匀划分策略 -
• 学术论文则保留原有结构,将拼接的多篇论文直接拆分,以保证每篇论文的完整性和连贯性
评估方法
针对F1-score等传统自动化评估指标导致的得分普遍偏低、评估不准确等问题,LaRA采用了基于LLM的评估方法。为确保评估的准确性和可靠性,LaRA选择仅包含具有明确答案的问题类型,避免了总结、续写等开放性问题,使评估更加客观可靠。在这种明确边界的问题设置下,LLM能够提供高度准确的评估结果。研究者通过计算人工评估结果与LLM评估结果之间的Cohen’s Kappa一致性系数,验证了LLM评估方法的准确性和可靠性。
实验结果
主要实验结果
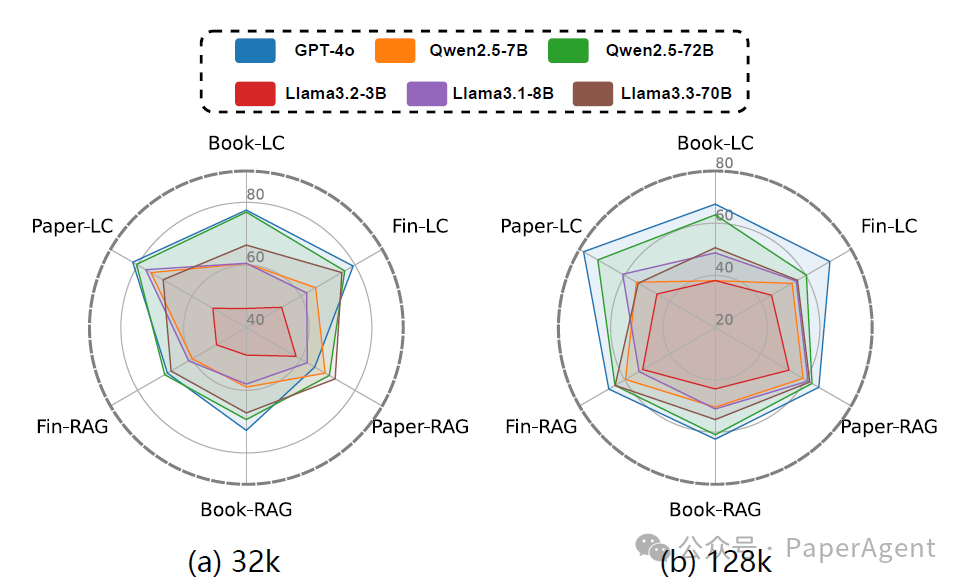
LaRA对7个开源模型和4个闭源模型进行了全面评估,得出以下主要发现:
-
1. 模型能力与RAG效果关系
RAG对能力较弱的模型提供了更显著的性能提升。分析表明模型基础能力与RAG有效性之间存在明显相关性:模型能力越弱,RAG带来的改进就越明显。例如,在128k上下文长度条件下,RAG分别使Llama-3.2-3B-Instruct和Mistral-Nemo-12B的准确率提高了6.48%和38.12%。而对于具备强大长文本处理能力的模型(如GPT-4o和Claude-3.5-sonnet),长上下文方法通常优于RAG,凸显了这些模型直接处理大规模上下文的有效性。 -
2. 上下文长度影响
随着上下文长度增加,RAG的优势变得更加明显。在32k上下文长度条件下,长上下文方法在所有模型中平均准确率比RAG高2.4%。然而,当上下文长度增至128k时,这一趋势发生逆转,RAG的平均表现超过长上下文方法3.68%。 -
3. 任务类型表现差异
RAG在单点定位任务中与长上下文方法表现相当,并在幻觉检测方面展现出显著优势。相比之下,长上下文方法在推理任务和比较任务中表现更为出色,但是更容易产生幻觉。

文本类型分析
研究者进一步对不同类型上下文进行了实验分析,发现无论是长上下文方法还是RAG方法,在处理不同文本类型时均呈现出一致的性能模式:学术论文上表现最佳,而小说文本上表现最差。学术论文通常具有较低的信息冗余度,同时保持强烈的逻辑性和严密的结构。这些特点使学术论文类似于一种天然的COT数据,为模型提供了清晰的推理路径,有助于模型更准确地定位和推导出正确答案。而小说文本中存在大量重复和相似表达,这显著增加了模型精确定位关键信息的难度。同时,小说的叙事性和多层次表达也容易诱导模型产生与原文不符的幻觉内容,导致回答精确度下降。
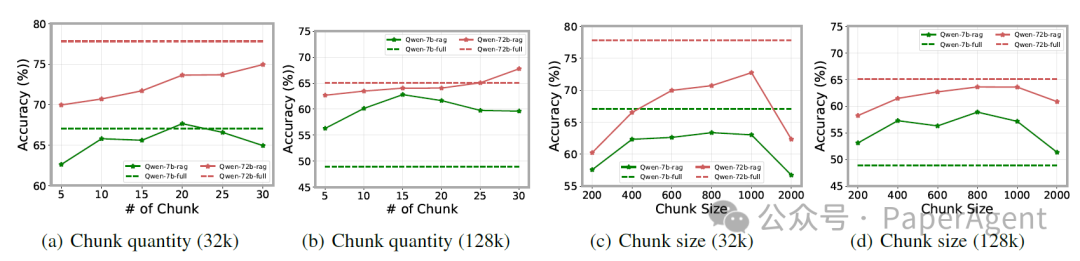
检索消融实验
研究者分析了检索信息长度对RAG性能的影响,主要从两个关键维度展开:检索chunk数量和单个chunk大小。为观察这些参数对大小不同模型的影响,研究团队选取了Qwen-2.5-72B-Instruct和Qwen-2.5-7B-Instruct两个模型进行对比实验。
如下图所示,实验结果揭示了模型规模与最优检索配置之间的重要关系:
-
1. 大型模型的检索特性
对于72B规模的模型,随着检索chunk数量的增加,性能呈现持续提升趋势。这主要得益于大型模型更强大的长上下文处理能力,能够有效整合和利用更多的检索信息。 -
2. 小型模型的检索特性
相比之下,7B规模的模型在检索chunk数量达到某个中间值时性能达到峰值,之后继续增加检索量反而导致性能下降。这表明对于小型模型,过多的检索信息引入的噪声最终会超过其带来的信息增益。 -
3. Chunk大小的影响
研究发现,无论是过大还是过小的chunk大小都会导致性能下降。在合理范围内增加chunk大小确实能带来一定改善,但其影响程度明显小于调整检索chunk数量所产生的效果。
结论
研究结果表明,当前LC LLMs在处理超长文本时并未展现出对RAG的全面碾压性优势,两者在不同应用场景中呈现出显著的互补性特征。在模型基础能力较弱(如参数量低于70B的开源模型)、上下文长度较长、涉及单点定位或需要严格抑制幻觉等场景下,RAG方案仍保持显著优势;而当采用GPT-4o等前沿闭源模型处理结构严谨的学术文本、或需要执行复杂推理与跨段落比较任务时,直接使用LC LLMs往往能取得更优效果。
局限与未来方向
LaRA主要聚焦于真实场景中具有确定性答案的问答任务,对RAG和长上下文方法进行了系统性比较,但仍存在一些值得进一步探索的研究方向:
-
1. 开放性问题的评估
当前LaRA主要限于有明确答案的问题类型,尚未涵盖总结、推断、创作等开放性任务。这类任务在实际应用中同样重要,但评估标准和方法较为复杂,需要在未来版本中进一步研究和完善。 -
2. 复合任务的模拟
虽然LaRA设计了定位、推理、比较和幻觉检测四种代表性任务,但实际应用场景中往往涉及多种能力的综合运用。未来研究应考虑设计更复杂的混合任务类型,更准确地模拟真实应用环境中的挑战。
参考文献:
[1] Xu, Peng, et al. “Retrieval meets long context large language models.” The Twelfth International Conference on Learning Representations. 2023.
[2] Lee, Jinhyuk, et al. “Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?.” arXiv preprint arXiv:2406.13121 (2024).
[3] Li, Zhuowan, et al. “Retrieval augmented generation or long-context llms? a comprehensive study and hybrid approach.” Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track. 2024.
[4] Yu, Tan, Anbang Xu, and Rama Akkiraju. “In defense of rag in the era of long-context language models.” arXiv preprint arXiv:2409.01666 (2024).
(文:PaperAgent)