
人类行动迅速,常常左右手交替同时执行多个动作任务——这样的演示视频,机器人该如何学习?
“只要人类的移动方式与机器人不同,现有方法就会立即失效,”康奈尔大学计算机科学助理教授Sanjiban Choudhury如是说。“我们的想法是,‘能否找到一种原则性的方法来解决人类和机器人执行任务方式之间的这种不匹配问题?’”
近日,Choudhury教授团队Kushal Kedia和Prithwish Dan等人在机器人模仿学习领域取得突破,提出了全新框架 RHyME(Retrieval for Hybrid Imitation under Mismatched Execution)。该架构无需任何人机配对数据,仅凭跨形态的语义对齐,就能在仿真与真实环境中将任务成功率提升 50% 以上,精准复现复杂的长时序操作。
▍为何机器人对人类视频的动作模仿总是“学废了”?
以人类演示作为提示,是机器人执行长视域操作任务的有效方法。但在实际学习的过程中,由于人类的动作灵活多变,机器人受限于机械结构与运动逻辑,难以完全匹配演示视频里人类的运动路径。现有方法通常依赖‘配对数据’——即针对同一任务,需同步采集人类与机器人执行视频,确保两者在时间戳、空间轨迹上严格同步。此类数据需多视角传感器同步、高精度动作捕捉设备及重复性实验标定,成本高昂且难以规模化部署。一些技术依赖于对画面的逐帧匹配,当存在显著形态差异(如人类双手同时操作与机器人单臂顺序操作)或动作节奏不匹配时,机器人策略迁移常常失败。
▍RHyME:不匹配动作下的混合模仿检索框架
RHyME框架包含两个核心模块:视觉编码器,将未配对的人类和机器人视频数据集映射到统一的语义空间;混合训练策略,在视觉编码器基础上,将人类视频的“任务意图”转化为机器人动作序列。其创新性在于从数据到策略的全链路无监督语义对齐,无需任何人类与机器人配对数据。以下为技术细节详解:

视觉编码器模块:通过采用SwAV自监督对比学习算法,编码器自动聚类跨形态的视觉特征——如人类手掌的抓握姿态与机器人夹爪的闭合角度,在嵌入空间中被拉近到同一区域。在时序维度上,利用时间对比损失函数确保动作连续性:人类“倒水”时水壶倾斜的连续帧,与机器人执行相同动作的机械臂轨迹,在时序维度上形成平滑的嵌入过渡。同时,当少量短时程配对数据可用时,通过最优传输距离计算任务级相似性,结合对比学习(InfoNCE损失)拉近语义等价的人机视频嵌入,如人类“双手整理桌面”与机器人“单臂推挤杂物”因任务目标一致,嵌入空间距离被最小化。这种无监督对齐方式彻底摆脱了对配对数据的依赖,即使面对YouTube上风格迥异的人类视频,编码器也能提炼出代表任务本质的语义信息。
混合训练策略模块:在训练阶段,RHyME先将机器人长视频拆解为“抓取”“移动”等短时程片段,接着从人类视频库中检索语义最接近的片段。例如,机器人“单臂拖拽箱子”的动作,可能匹配到人类“双手搬运重物”的视频,因为二者的核心任务目标都是移动物体。完成高质量检索的关键挑战在于在于定义一个能够处理不同长度视频序列的距离函数,本文设计了两种距离计算方法:
○ 从全局语义匹配出发计算最佳传输距离。将机器人视频分割为短序列,从人类视频库中检索整体任务意图最接近的片段。这种方式对动作风格差异较大的情况具有鲁棒性。
○ 从局部时序对齐出发计算时间循环一致性距离。通过帧级软匹配和循环一致性损失,确保人类与机器人动作在时间轴上对齐。当人机动作节奏差异大时(如人类快速操作),易出现时序错位。
在人类视频库中被检索到的片段会被拼接成“想象人类演示视频”,与真实机器人数据共同输入策略网络。通过利用合成数据与真实数据进行交替训练,策略网络逐渐学会区分“动作细节”与“任务本质”,从而泛化到未见过的动作方式:无论人类是用单手还是双手、快速还是慢速操作,只要任务目标相同,机器人就能生成适配自身形态的动作序列。

如Fig. 1所示,从训练到推理的完整链路,展现了RHyME在工程上的精妙之处。训练阶段,系统通过最优运输算法在语义空间“绘制”任务地图,将杂乱的非配对数据转化为结构化的“嵌入-轨迹”对应关系;推理阶段,当输入一段新的人类视频,视觉编码器首先提取其语义嵌入,策略网络随即根据这些嵌入生成机器人动作指令。推理的关键在于动态适配:机器人会自主调整执行节奏,将人类快速动作分解为多个稳妥的步骤,确保符合自身物理限制。这种“语义优先”的设计理念,让RHyME在测试场景中展现出惊人优势。面对人类“左手开柜门、右手提重物”的双任务操作,传统方法因无法理解双手协同的语义而频频失败,但RHyME却能将其拆解为两个独立的子任务序列,通过语义匹配分别生成对应的单臂操作。这种能力不仅降低了数据收集成本,更让机器人一定程度上摆脱了对特定形态的依赖——未来,同一段人类视频可能同时指导工业机械臂、家庭服务机器人甚至无人机完成跨形态任务,实现“一次演示,全域通用”。
○ Sphere-Easy:外观不同但动作风格相似
结果表明,RHyME 对不断增加的失配水平具有鲁棒性,性能优于 XSkill。
RHyME 动作(本文方案)
XSkill 动作(基线)
○ 仿真场景
○ 人机图像嵌入
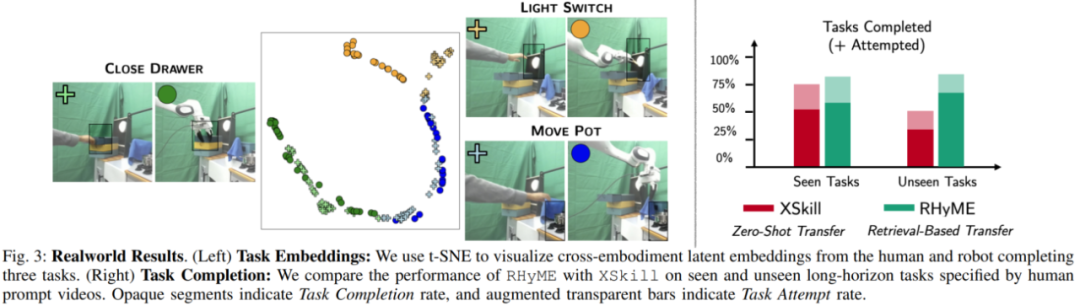
如Fig. 3和Fig. 4所示,论文还可视化了真实场景与仿真场景的人机图像嵌入,验证了不同任务的嵌入明显分离,展示了人类与机器人动作在语义空间的高度对齐,突出了RHyME的核心创新在于任务级语义对齐,而非传统的逐帧动作模仿。

Choudhury教授团队将在今年五月于国际机器人学顶级会议ICRA(IEEE International Conference on Robotics and Automation)上发表这项研究成果。
技术的突破往往始于认知的升级。RHyME的出现,重新定义了机器人模仿的目标:不再追求动作的帧级复现,而是聚焦于任务意图的跨形态传递。这为机器人融入人类生活打开了一扇新的大门——当机器人真正学会“理解”而非“复制”,通用具身智能的时代,可能就藏在这场模仿秀的下一幕。
论文信息
标题:One-Shot Imitation under Mismatched Execution
作者:Kushal Kedia, Prithwish Dan, Angela Chao, Maximus A. Pace, Sanjiban Choudhury
机构:Cornell University
研究主页:https://portal-cornell.github.io/rhyme/
来源:具身智能大讲堂
(文:机器人大讲堂)