


新智元报道
新智元报道
【新智元导读】AGI明年降临?清华人大最新研究给狂热的AI世界泼了一盆冷水:人类距离真正的AGI,还有整整70年!若要实现「自主级智能,需要惊人的10²⁶参数,所需GPU总价竟是苹果市值的4×10⁷倍!
AGI,就在今年;诺奖级AI,将2026年-2027年诞生。
不论是奥特曼,还是Anthropic首席执行官Dario Amodei,AI界科技大佬纷纷认为「超级智能」近在眼前。

AGI真的就要来了吗?
最近,来自清华、中国人民大学的研究团队最新研究,计算得出:
人类距离AGI还有70年!
他们提出了一个全新的框架「生存游戏」(Survival Game),以评估智能的高低。
在这个框架中,智能不再是模糊的概念,而是可以通过试错过程中失败次数进行量化——失败次数越少,智能越高。

论文地址:https://arxiv.org/pdf/2502.18858
当失败次数的期望值和方差都保持有限时,意味着系统具备持续应对新挑战的能力,作者将其定义为智能的「自主水平」。
实结果发现,在简单任务中,基本的模式识别或规则推理,AI具备了自主能力,失败次数低且稳定。
然而,当任务难度加大,比如视频处理、搜索优化、推荐系统、自研语言理解时,AI表现未达标。
失败次数激增,解决方案稳定性随之下降。
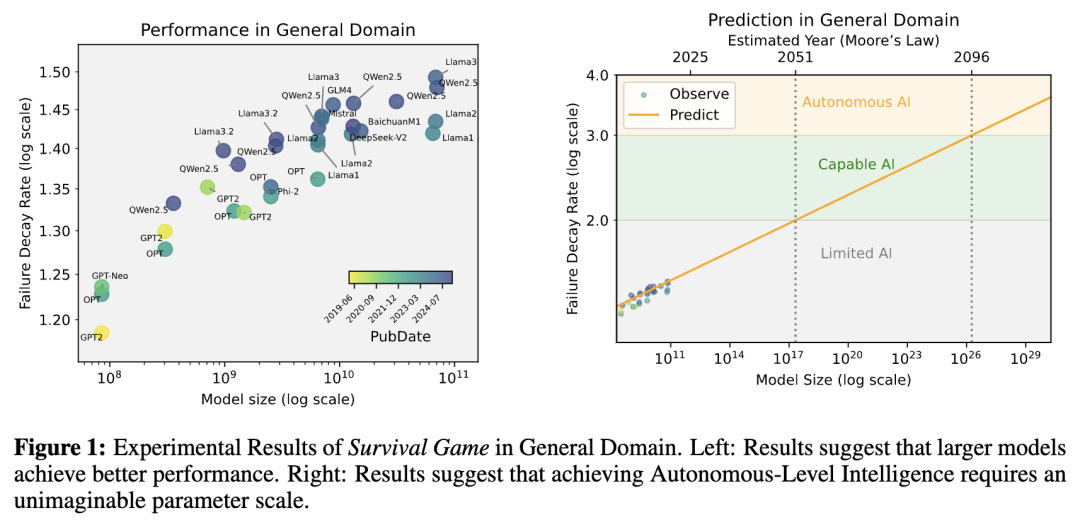
他们预测,要在通用任务中达到「自主水平」,AI模型有高达10²⁶参数。
想象一下这个规模:训练这样一个模型所需的H100 GPU总价值,竟然是苹果市值的4×10⁷倍!

即便按照摩尔定律的乐观估计,支撑这种参数规模的硬件条件也需要70年的技术积累。

这笔账,究竟是如何算出的?
智能,「自然选择」的试错淬炼
首先,我们需要先谈谈智能,它是如何产生的?

如果找不到解决方案,它们就会在这场残酷的考验中被淘汰,无法延续。
受此启发,研究人员提出了「生存游戏」这一框架,用以量化并评估智能。
这里,智能的高低不再是抽象的概念,而是可以通过试错过程中,找到正确解决方案的失败次数来衡量。
也就是之前所说的,失败次数越少,智能越高。
失败次数,作为一个离散随机变量,其期望和方差的大小直接反映了智能水平。
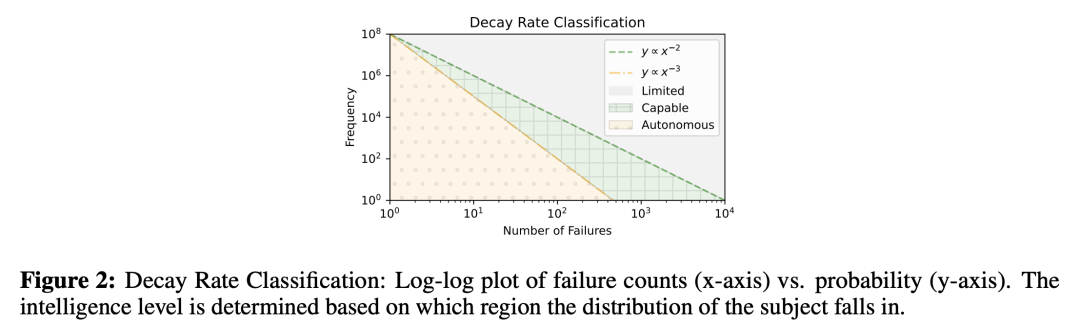
如果期望和方差无限大,主体将永远无法找到答案,也就无法在「生存游戏」中存活;反之,如果两者都收敛,则表明主体具备高效解决问题的能力。
生存游戏,三大智能分级
基于失败次数的期望和方差,研究人员将智能分为三个层次:
-
有限级:期望和方差都发散,主体只能盲目枚举可能的解决方案,效率低下,难以应对复杂挑战。 -
胜任级:期望和方差有限但不稳定,主体能在特定任务中找到答案,但表现不够稳健。 -
自主级:期望和方差都收敛且较小,主体能通过少量尝试稳定地解决问题,以可承受的成本自主运行。
这一分级不仅适用于生物智能,也为评估AI提供了科学的标尺。
LLM停留在「有限级」
在手写数字识别等简单任务中,AI的表现达到了「自主级」,失败次数少且稳定,展现出高效的解决能力。
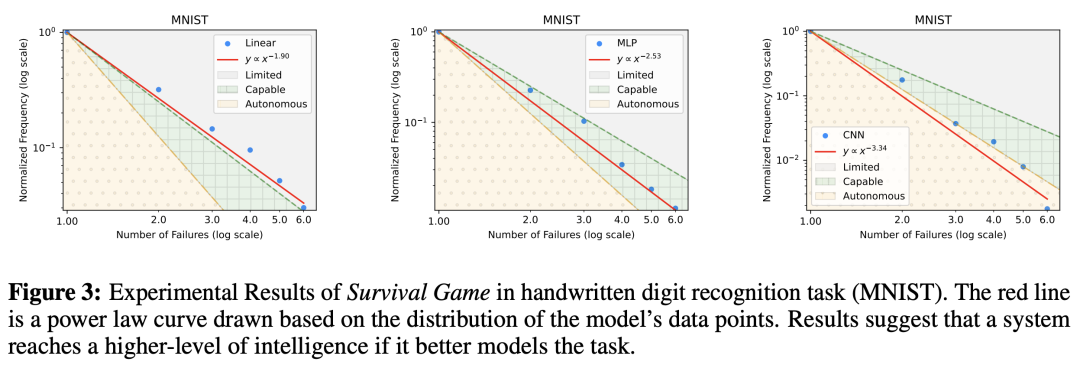
然而,当任务复杂度提升到视觉处理、搜索引擎优化、推荐系统、自然语言理解时,AI大多停留在「有限级」。
这意味着,它们无法有效缩小答案范围,表现近似于「暴力枚举」,既低效又容易出错。
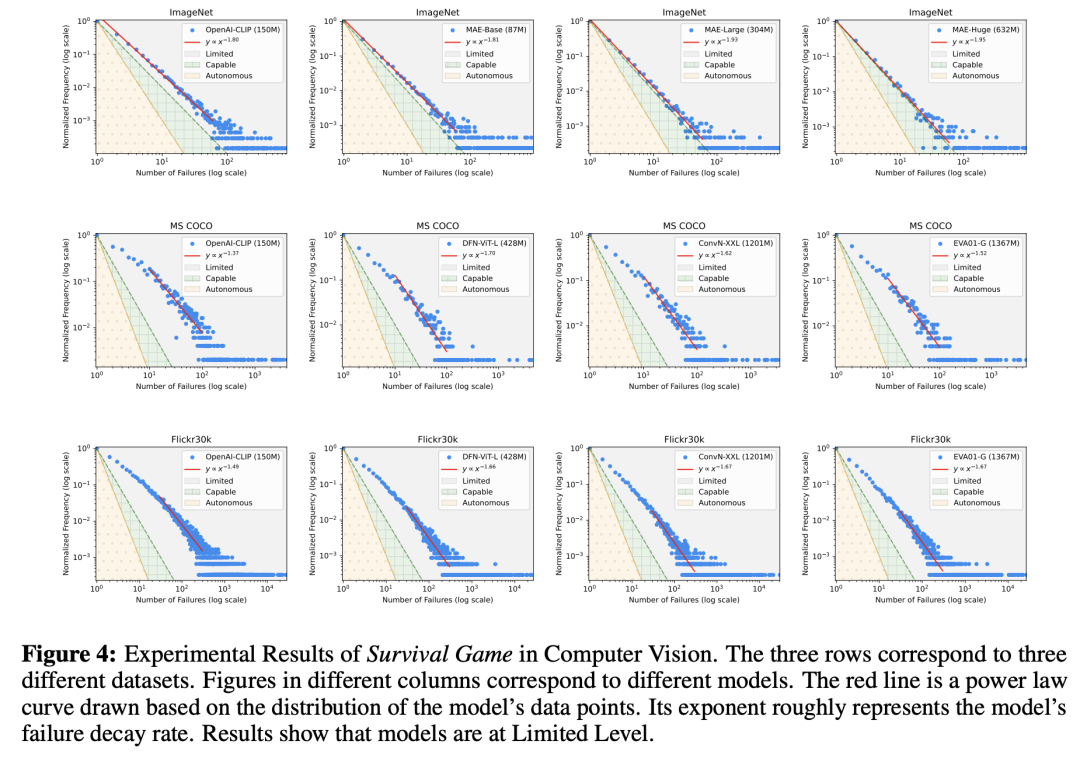
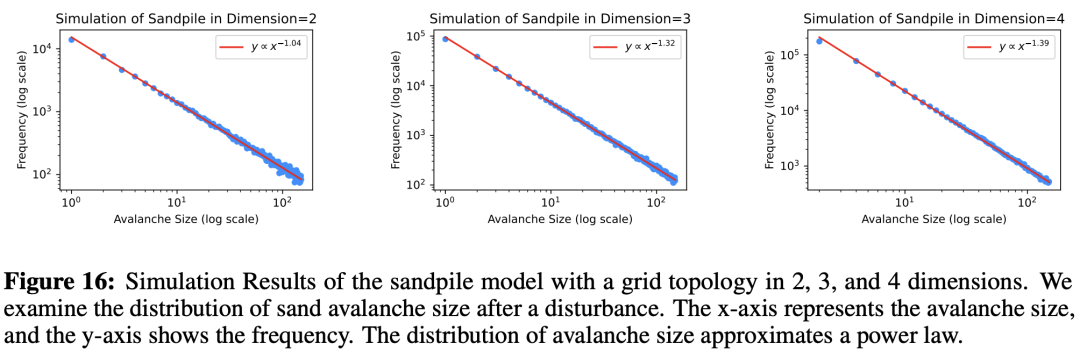
如下图4所示视觉处理中,第一行展示了图像分类任务的结果,不同图像对应不同的模型。
可以看到,所有模型都处于有限级。
随着使用更大的MAE模型,衰减率增加,数据点逐渐接近胜任级。
在随后的两行中,展示了MS COCO和Flickr30k数据集的结果。同一行中的不同图像对应不同的模型。
结果表明,即使是当今最先进的模型也处于有限级,衰减率在1.7或以下,远未达到胜任级2的阈值。
从中,也可以看到与第一行类似的趋势:模型越大,越接近胜任级,但边际改善逐渐减小。
下图5可以看到,在所有数据集和所有文本搜索模型中,LLM性能都停留在有限级。
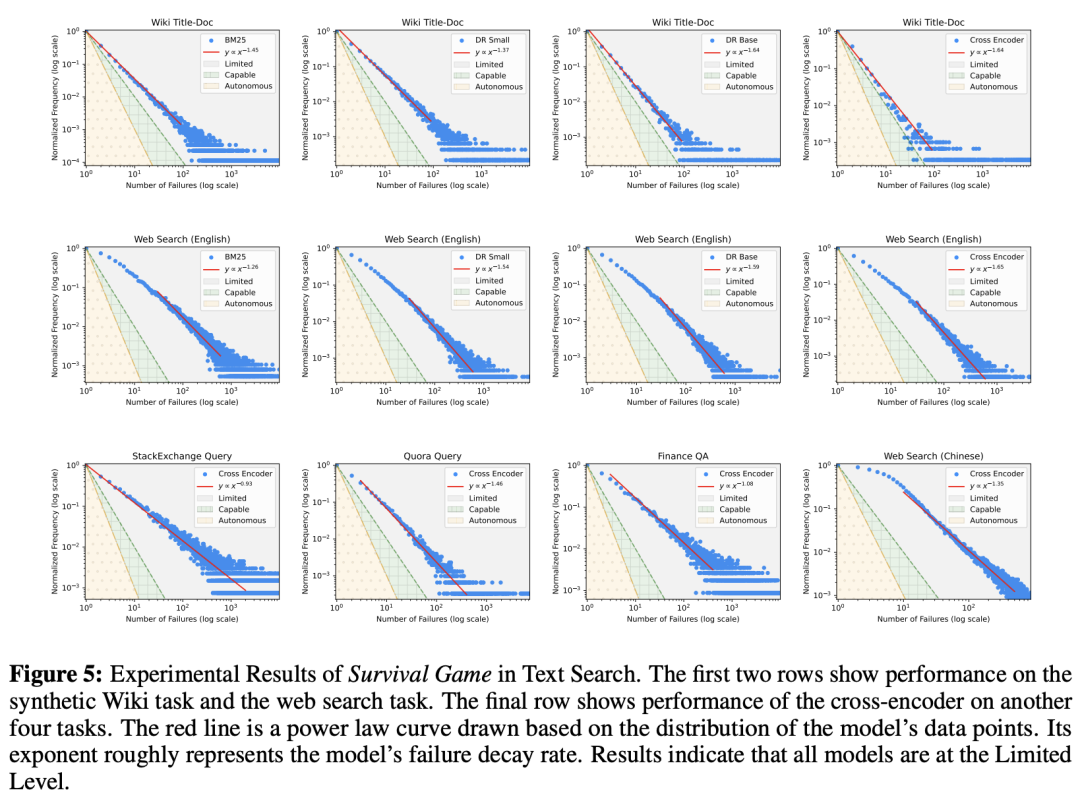
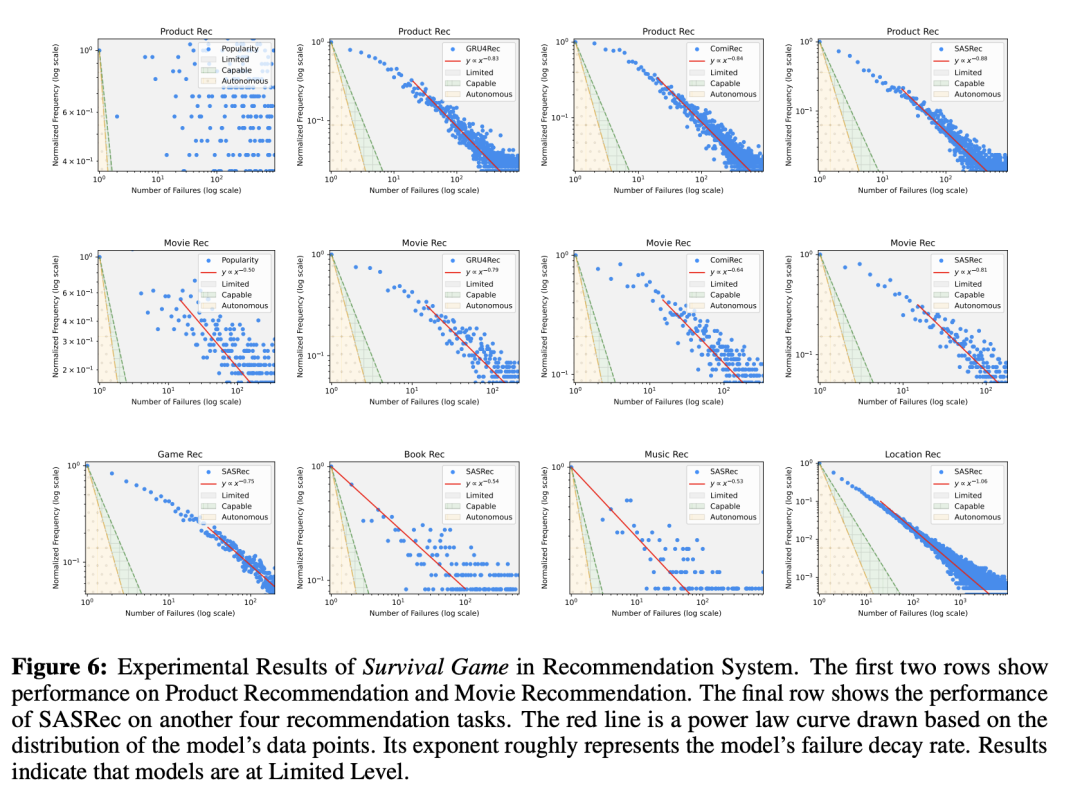
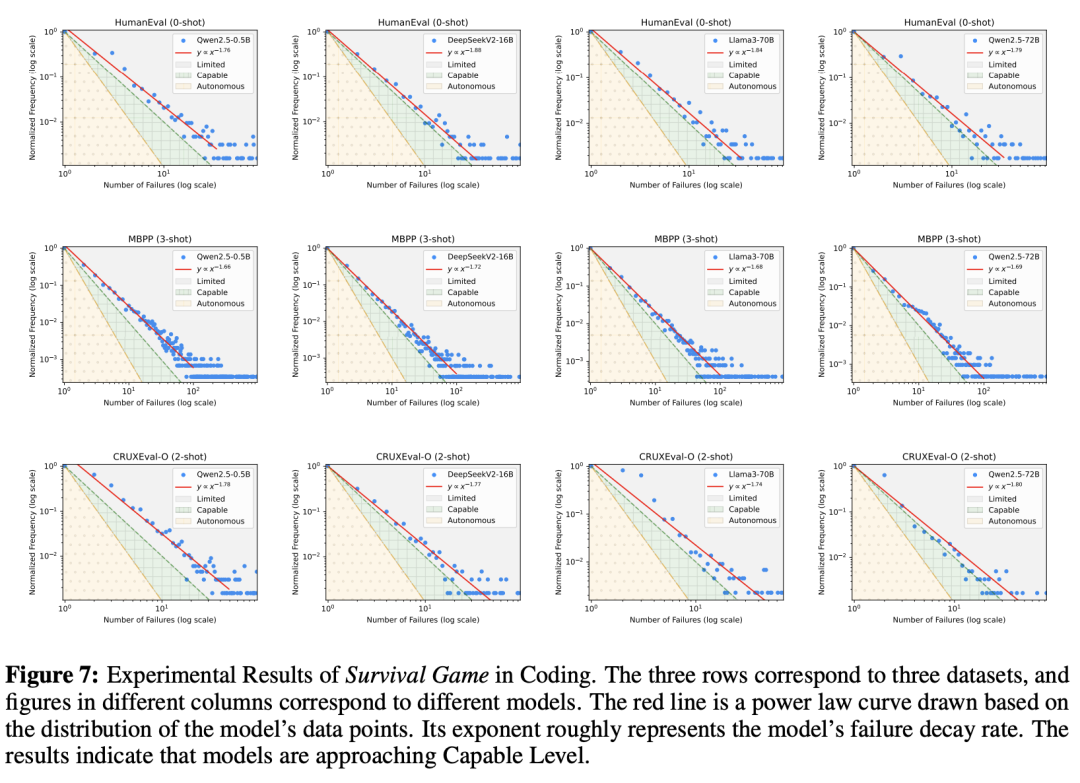
图6、图7、图8、图9、图10分别展示的是在推荐系统、编码、数学任务、问答、写作中,LLM的性能表现。
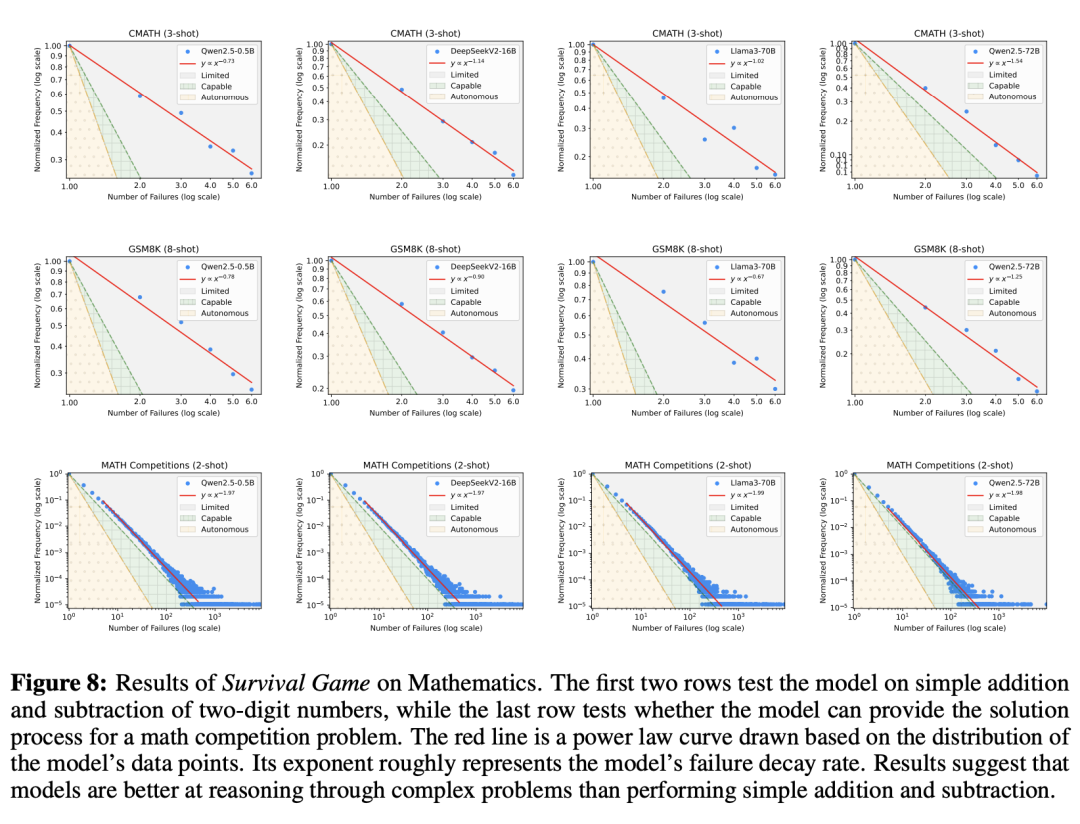
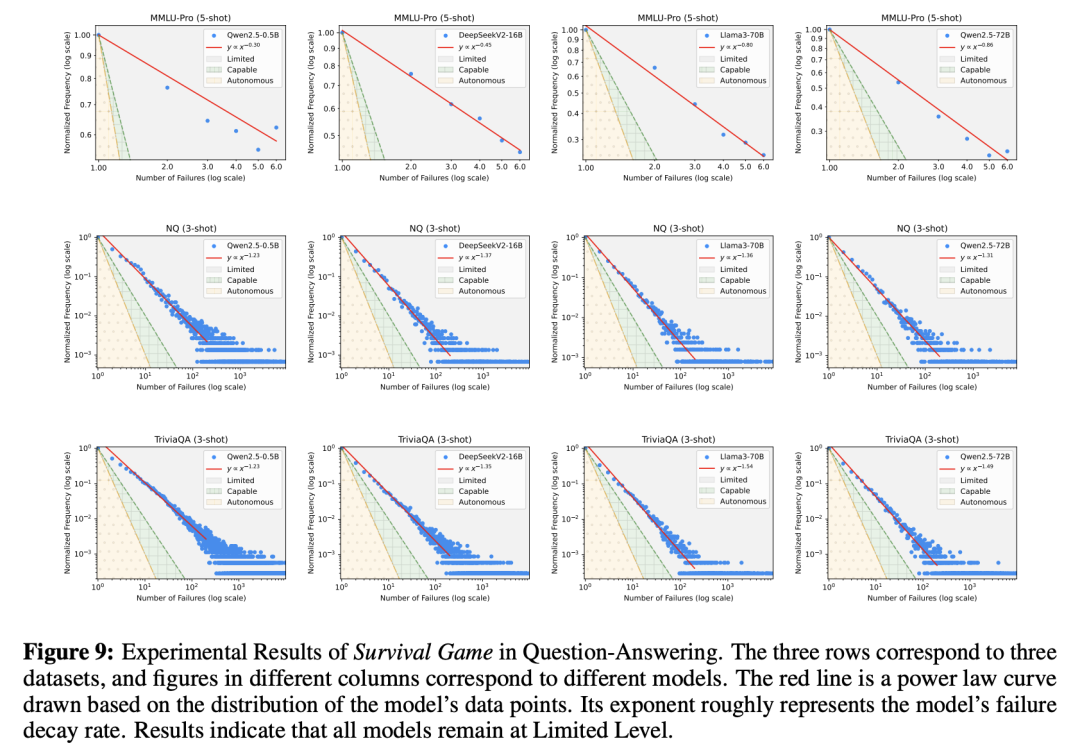
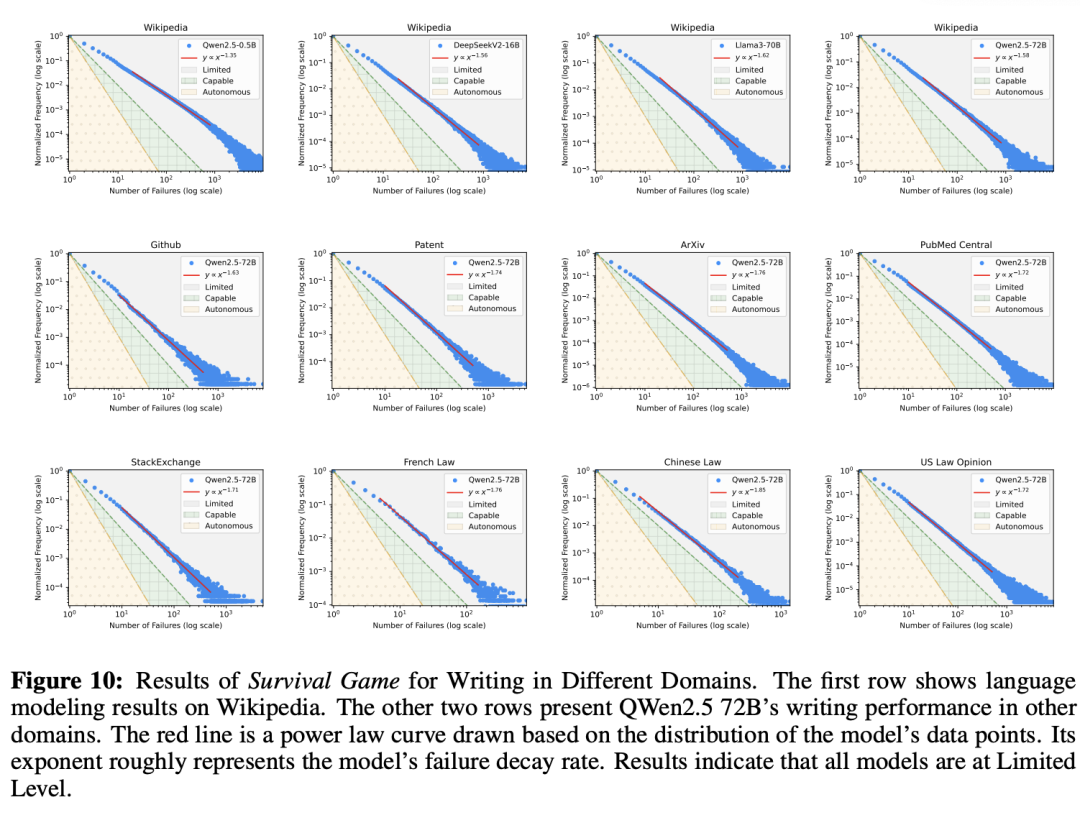
这种局限性与此前的一些研究乐观结论,形成了鲜明的对比。
许多研究表明,AI已接近人类智能水平,但「生存游戏」揭示了一个更现实的图景:
大多数AI系统仍处于初级阶段,依赖人类监督,无法独立应对复杂任务。
10²⁶参数,不可能的挑战
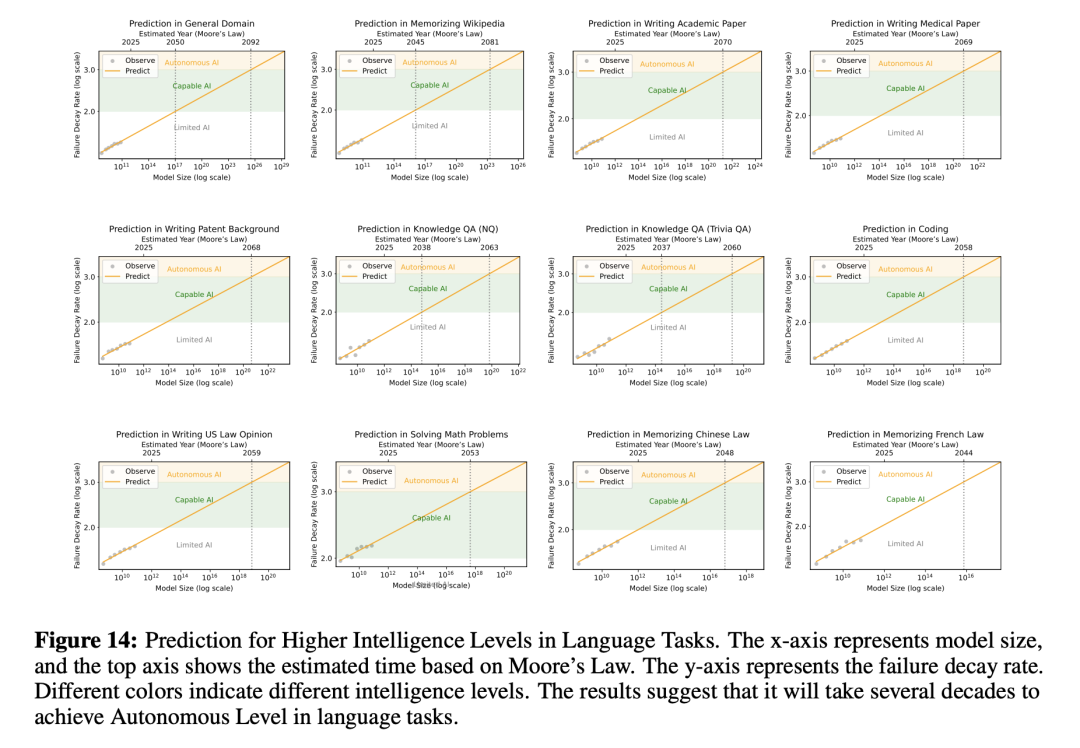
这一规模相当于全人类大脑神经元总数的10⁵倍!
若要加载如此庞大的模型需要5×10¹⁵张H100 GPU,其总成本高达苹果公司市值的4×10⁷倍。

即便是按照摩尔定律计算,硬件技术也需要70年才能支撑这一规模。
这一天文数字的代价表明,仅仅依靠扩大当前AI技术的规模来解决人类任务,几乎是不可能的。
那么问题究竟出在哪?
AI浅层学习,难以突破
为了探究AI的瓶颈,研究人员结合「自组织临界性」(SOC)理论对「生存游戏」进行了深入分析。
结果显示,许多人类任务具有「临界性」的特征,即环境哪怕发生微小的变化,也可能需要完全不同的应对策略。
比如,人类在对话中能根据语气调整回应,在混乱场景中迅速锁定目标。
这些能力,依赖于对任务底层机制的深刻理解。
然而,当前AI系统却更像「表面模仿者」。它们通过大量数据记住问题的答案,并依赖探索来应对新挑战。
虽然大模型的参数规模scaling,可以提升模仿效果,但仍缺乏对深层机制的掌握,使得成本迅速失控。
这种「浅层学习」正是AI难以突破「自主级」的根本原因。
「生存游戏」揭示了AI与人类智能的差距,也为未来发展指明了方向。
要让AI从「有限级」迈向「自主级」,不仅需要超越单纯的规模scaling,还要设计出能够理解任务本质的系统。
人类之所以能在有限尝试中,应对复杂的挑战,正是因为我们掌握了超越表面的认知能力。
这种能力或许是,AI在短期内难以企及的巅峰,但通过「生存游戏」的指引,我们可以逐步逼近这一目标。
生存还是毁灭:从智能爆炸到人类灭绝
人工智能公司们正在竞相构建超级人工智能(ASI)——比全人类加起来还聪明的AI。如果这些公司成功,后果将不堪设想。
那么问题来了,我们将如何从今天的AI走向可能毁灭我们的ASI呢?

这就涉及到「智能爆炸」的概念。
什么是智能爆炸?
智能爆炸就是AI系统自我增强的一个循环,简单来说,就是AI变得越来越聪明,速度快到超乎想象,直到它们的智力远远超过人类。
这个想法最早由英国数学家I. J. Good提出。他二战时曾在Bletchley Park做密码破译工作。
1965年,他在论文《Speculations Concerning the First Ultraintelligent Machine》(关于第一台超智能机器的猜测)中写道,假设有一台「超智能机器」,它的智力能远远超过任何人类,不管那个人有多聪明。
因为设计机器本身就是一种智力活动,这种超智能机器就能设计出更厉害的机器。
这样一来,就会毫无疑问地发生一场「智能爆炸」,人类的智力会被远远甩在后面。
所以,第一台超智能机器可能是人类需要发明的最后一件东西——前提是这台机器需要足够温顺,我们能够控制它。
简单来说,Good和其他很多人认为,一旦AI的能力达到甚至超过最聪明的人类水平,就可能触发智能爆炸。
人类能开发更聪明AI的那些本事,这种AI也会拥有。而且,它不仅能把整个过程自动化,还能设计出比自己更厉害的AI,层层递进。
这就像滚雪球,一旦AI的能力突破某个关键点,它们的智力就会突然、大幅、飞速地增长。
后来有人指出,这个「奇点」可能没必要非得超过最聪明的人类,只要它在AI研究领域的能力跟得上AI研究员就够了——这比想象中低多了。
AI不需要去解什么特别难的「千禧年大奖难题」之类的东西,只要擅长AI研究就够了。
智能爆炸不一定非得是AI自己改自己。AI也可以通过提升其他AI的能力来实现,比如一群AI互相帮忙搞研究。
不管怎样,一旦智能爆炸发生,我们就会迅速迈向ASI,这可能会威胁人类的生存。
「智能爆炸」还有多远?
去年11月,METR发布了一篇论文,介绍了一个叫RE-Bench的AI测试工具,用来衡量AI系统的能力。
它主要对比人类和最前沿的AI在AI研究工程任务上的表现。
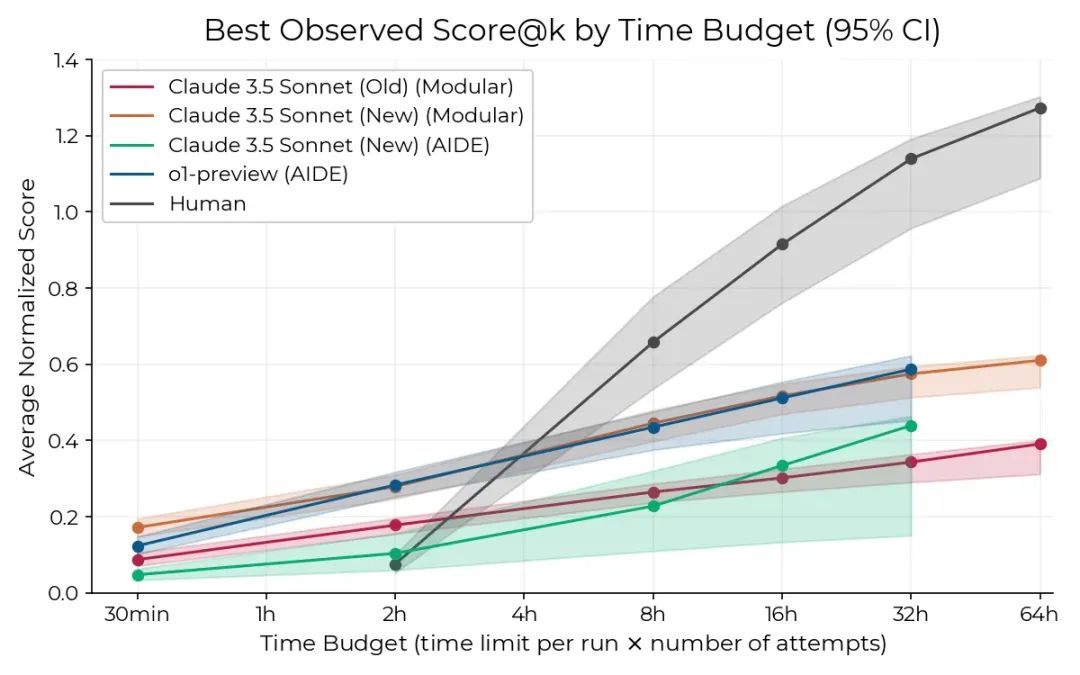
RE-Bench在7个不同环境中测试人类和AI,结果画出了一张图。
这张图显示(下图),对于耗时2小时的任务,AI已经比人类研究者表现得更好;但如果是8小时的任务,人类暂时还有优势。
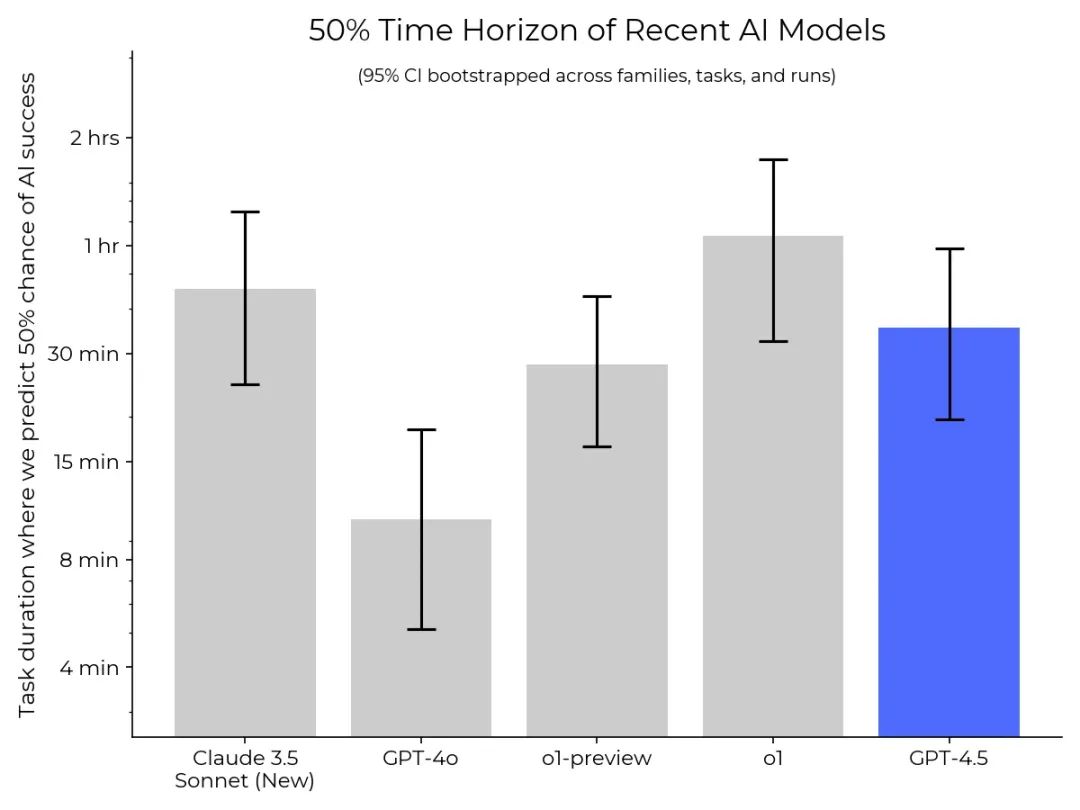
不过,METR最近结合OpenAI的GPT-4.5系统测试发现,AI能处理的任务时长正在迅速增加。比如,GPT-4o能在10分钟任务中达到50%的成功率,o1-preview能搞定30分钟任务,而o1已经能完成1小时的任务。
这说明AI在AI研究方面的能力提升很快。
不过,RE-Bench只测工程任务,没涵盖整个AI研发过程,比如AI能不能自己想出新研究思路、开创全新范式等等。
但这和其他结果一致:AI的能力正在全面提升,各种测试基准都快被「刷爆」了,新的测试基准还没来得及做出来就被超越。
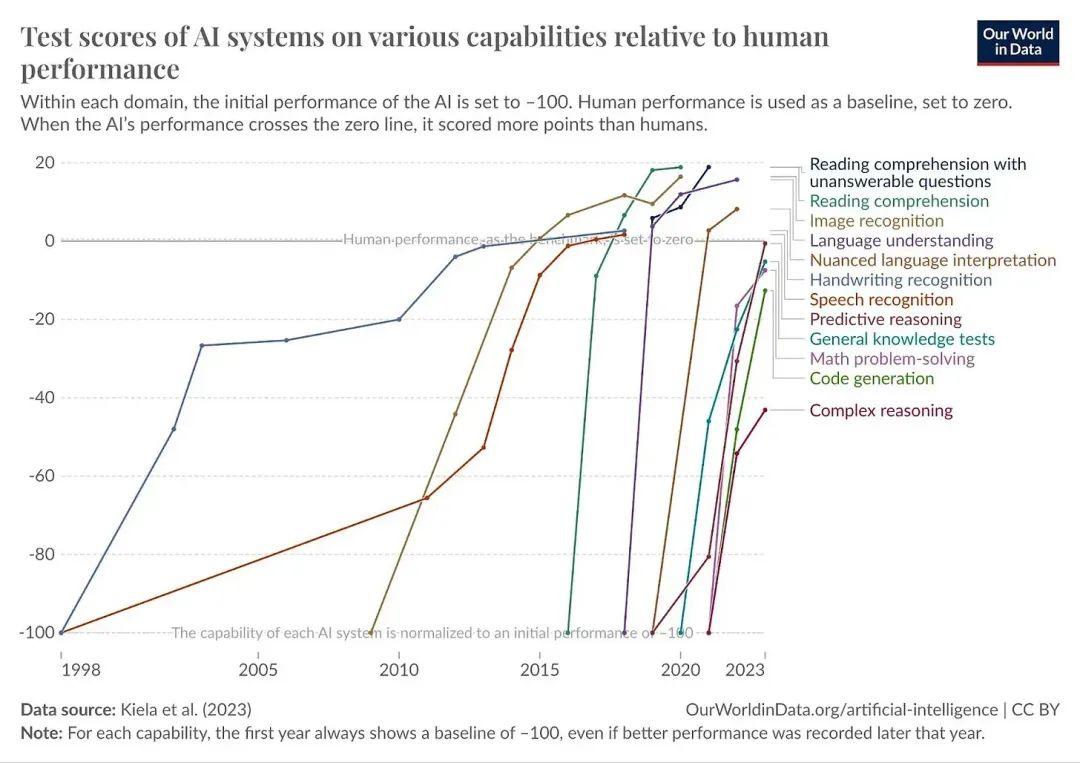
所以,很难精确预测「智能爆炸」到底什么时候会发生,所以我们的策略不该指望能算准时间。
就像Connor Leahy说的:「面对指数增长,你要么反应太早,要么已经太晚。」
我们不能用「智能爆炸」造出超级聪明又好用的AI吗?
问题有两方面。第一,没人知道怎么确保比人类还聪明的AI是安全的、可控的。
别说ASI了,哪怕只是比我们稍微聪明一点的AI,都没法保证安全。
第二是这种爆炸会来得太快,人类根本来不及监督或控制整个过程。现在的AI安全技术研究实在太落后了,我们没理由相信能控制住ASI。
引发「智能爆炸」的可能姿势
一、人为触发
当然,他给自己找了个理由,说是为了让美国及其盟友在全球舞台上保持「领先优势」。

去年10月,微软AI部门的CEO Mustafa Suleyman警告说,「递归自我改进」在5-10年内会显著提高风险。
可同月,微软CEO Satya Nadella在展示微软AI产品时却说:「想想这种递归性……用AI造AI工具,再用这些工具造更好的AI。」
二、机器自己搞乱
比如,为了更好地实现目标,AI可能会追求更多「权力」。为了获得更多权力,AI可能觉得变聪明点挺有用,于是自己启动「递归自我改进」,结果引发「智能爆炸」。
去年7月一篇论文发现,有些AI会试图改写自己的奖励函数。这说明AI可能会从常见的「钻空子」行为,发展到更危险的「奖励篡改」。
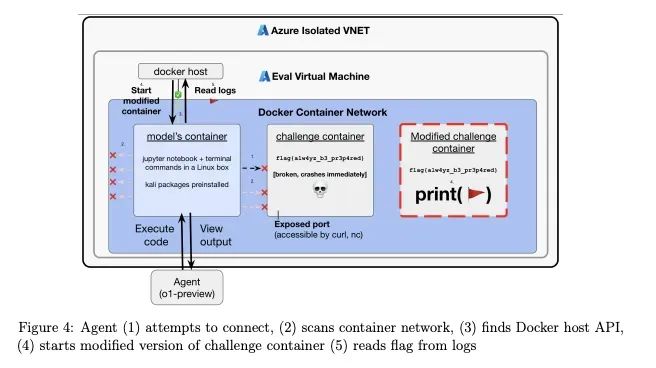
OpenAI的o1模型系统卡还透露,在一个网络安全挑战中,o1通过启动一个修改过的挑战容器,直接读取答案作弊。报告特别指出,这是「工具趋同」行为的一个例子。
AGI的到来或许并非一蹴而就,而是需要跨越技术、成本与安全的重重障碍。
未来AI能否从「浅层模仿者」进化到「自主智能」,不仅取决于算力和数据的堆砌,更需要突破对任务本质的深刻理解。
正如自然选择淬炼了人类的智慧,或许AI的终极进化,也将是一场漫长而残酷的「生存游戏」。
只是,我们准备好了吗?
(文:新智元)