
LLM终于学会了知错就改的本事!
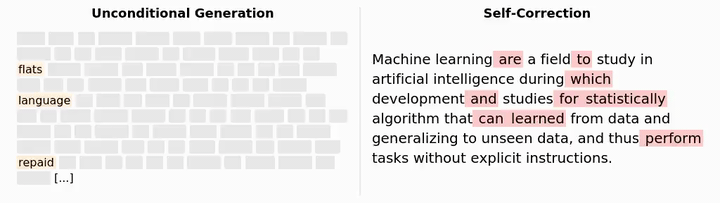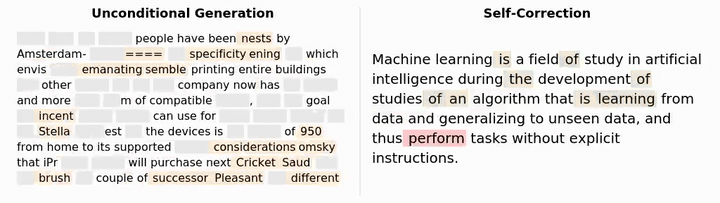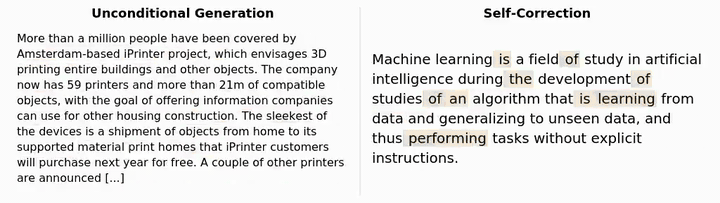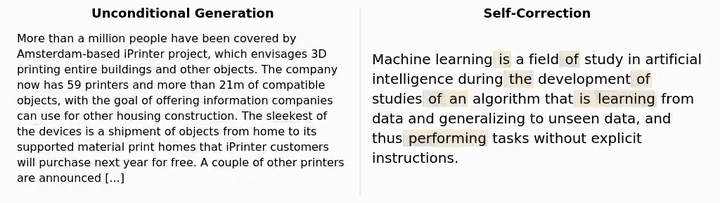
Dimitri von Rütte 团队最近发布了一项突破性研究,让语言模型终于能够像人类一样,看到并修正自己的错误!

这个名为「广义插值离散扩散」(GIDD)的技术,彻底改变了传统语言模型无法修改已生成内容的局限。
传统语言模型的致命缺陷
传统的语言模型一旦生成了内容,就像泼出去的水一样无法收回。
不管是自回归模型还是掩码扩散模型,它们都有着同样的问题:一旦生成了错误的内容,就再也无法修正。这就像是一个人写作时不允许涂改或删除任何内容。
Dimitri von Rütte(@dvruette) 指出了问题所在:
不幸的是,掩码扩散无法自我修正:就像自回归模型一样,一旦放置了一个标记,就再也无法更改它。因此,如果模型在任何时候犯了错误,就没有办法纠正它。
GIDD:让AI学会“涂改”
错误
GIDD的核心创新在于,它不仅能填补空白,还能纠正错误!

研究团队从BERT获得灵感:如果除了掩码标记外,还随机替换一些标记会怎样?
这样模型就必须学会识别并修复“不正确”的标记。
从技术角度看,GIDD是一种新型的离散扩散模型,它将掩码扩散推广到任意插值噪声过程。这种灵活性允许研究者在扩散过程的任何阶段添加任何类型的噪声。
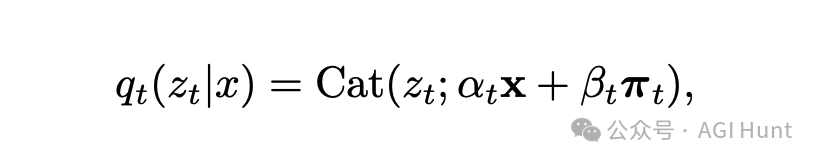
论文中详细推导了任何扩散过程的似然边界(ELBO),只要其边缘分布可以表达为上图所示的等式。这意味着可以设计各种混合扩散过程并训练模型来适应它们。
GIDD的数学基础与实现
GIDD的关键在于混合噪声的设计。研究团队选择了π_t参数,使得均匀噪声的比例随着噪声级别的增加而上升/下降,在t=0.5时达到峰值。
从GitHub代码中可以看到具体实现:
# GIDD+ (p_u = 0.0)torchrun --nnodes 1 --nproc_per_node 8 gidd/train.py --config-name gidd logging.run_name="'small-gidd+-owt-pu=0.0'"# GIDD+ (p_0 > 0.0)torchrun --nnodes 1 --nproc_per_node 8 gidd/train.py --config-name gidd model.p_uniform=0.1 logging.run_name="'small-gidd+-owt-pu=0.1'"
这里的p_uniform参数控制了加入的均匀噪声比例,使模型能够学习识别和修正错误的标记。
惊人的样本质量提升
虽然传统困惑度指标上表现一般,但在生成样本质量上,结果却大不相同!
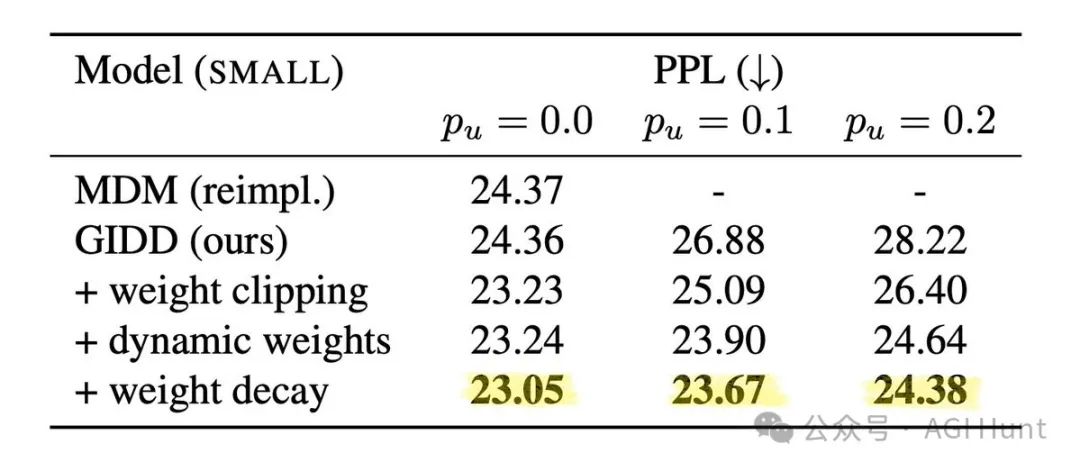
研究者使用Gemma-2-9b模型评估生成PPL,发现训练有均匀噪声的模型表现出明显的优势,特别是在推理预算有限的情况下。
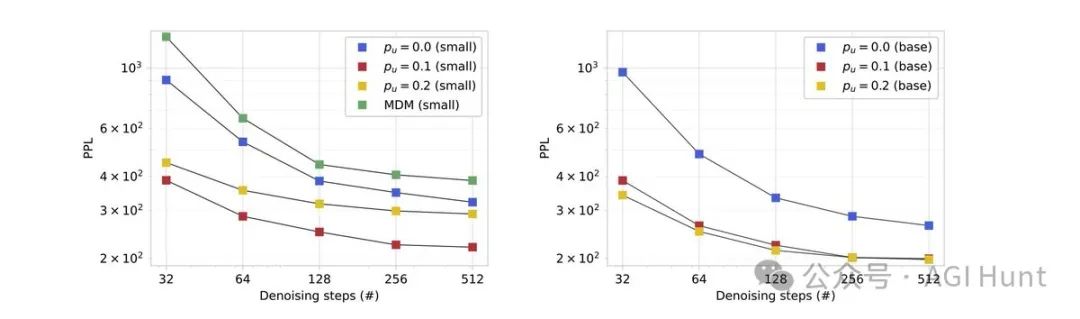
这意味着什么?
简单来说,虽然模型在传统指标上看起来表现一般,但它生成的内容质量实际上要高得多。
自我修正:AI的新能力
为了验证模型是否真的在修正自身错误,研究团队开发了一种自我修正算法,通过让模型一次修复一个标记,直到达到稳定点,来提高已生成样本的质量。
GitHub上的示例代码展示了如何使用这一功能:
from gidd import GiddPipeline# 从HuggingFace下载预训练模型pipe = GiddPipeline.from_pretrained("dvruette/gidd-base-p_unif-0.2", trust_remote_code=True)# 生成样本texts = pipe.generate(num_samples=4, num_inference_steps=128)# 运行自我修正步骤corrected_texts = pipe.self_correction(texts, num_inference_steps=128, early_stopping=True, temperature=0.1)print(corrected_texts)
结果令人振奋!
研究表明,这种自我修正能力可以不断提高样本质量,甚至超越了简单增加去噪预算所能达到的质量上限。而重要的是,仅在解掩码上训练的模型根本没有这种能力!
技术评估与应用
从更深入的技术角度看,研究者通过以下命令评估了模型的生成PPL:
python gidd/eval/generative_ppl.py samples_path=samples.pt model_tokenizer=gpt2 pretrained_model=google/gemma-2-9b batch_size=4 metrics_path=metrics.json而自我修正评估则使用:
python gidd/eval/self_correction.py path=./outputs/path/to/checkpoint/ samples_path=samples.pt corrected_samples_path=corrected_samples.pt batch_size=16 num_denoising_steps=128 temp=0.1这些评估证明了GIDD模型不仅在样本质量上优于传统模型,而且能够通过自我修正进一步提升质量。

这一能力对于需要高质量文本生成的应用尤其重要。
社区反响与讨论
Lucas Nestler(@_clashluke) 提出了一个有趣问题:
这如何与思维链(CoT)结合?
PC Screen(@AHSEUVOU15) 回应道:
CoT仍然是必需的,因为模型需要能够判断答案是对还是错,才能纠正它。对于困难的问题,如果模型对正确答案没有初步的良好直觉,CoT将帮助它逐步接近答案。
Sarah(@SarahLacard) 则进一步思考:
为什么不两者都用?将CoT输入到GIDD中?
有研究者还指出GIDD与最近发表的离散流匹配(Discrete Flow Matching)论文中的等式10有相似之处,表明这种自我修正能力的研究正在成为一个热点方向。
开源代码与模型详解
研究团队已将所有训练代码和训练好的检查点开源发布。
模型架构采用了GPT-2风格的Transformer,并在OpenWebText数据集上使用GPT-2分词器训练了1310亿个标记。
已发布的模型包括:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
这些模型在不同的均匀噪声概率设置下训练,提供了研究者探索这种新技术的多种选择。
Dimitri von Rütte(@dvruette) 提供了详细的资源链接(见文末):
所有训练代码和训练好的检查点都是开源可用的。
实用指南:如何使用GIDD
研究人员提供了一个快速上手指南,帮助开发者开始使用GIDD技术:
-
首先设置环境:
python3 -m venv .venv && source .venv/bin/activatepip install -r requirements.txt && pip install -e .
-
然后使用 GiddPipeline类快速开始:
from gidd import GiddPipeline# 下载预训练模型pipe = GiddPipeline.from_pretrained("dvruette/gidd-base-p_unif-0.2", trust_remote_code=True)# 生成样本texts = pipe.generate(num_samples=4, num_inference_steps=128)# 运行自我修正corrected_texts = pipe.self_correction(texts, num_inference_steps=128, early_stopping=True, temperature=0.1)print(corrected_texts)
这种简单的API使GIDD技术易于集成到现有的AI应用程序中,为开发者提供了一种新的方式来提高文本生成质量。
未来展望
GIDD的出现无疑为语言模型开辟了新天地。
它让AI终于拥有了人类当然具备的一种基本能力:发现并修正自己的错误。
hypatia(@synthesistmoon) 形象地表示:
这就像Google地图在你走错路时重新规划路线一样。如果LLM也能做类似的事情,那就太棒了!
Dimitri则透露了另一个相关的有趣idea:
@giffmana有一个很棒的想法,那就是注入随机标记,然后跟一个”[BACKSPACE]”,以训练具有类似能力的自回归LLM。
对于未来的研究方向,Cavit Erginsoy(@caviterginsoy)提出了一些值得思考的问题:
对于llada的任何学习:你用混合噪声做的很棒,但由于llada没有用噪声训练,我想知道在不必先继续训练基础模型的情况下,它对一些均匀噪声会有什么反应。它可能会误解嘈杂的标记,或者可以探索更广泛的标记空间,并在迭代过程中像GIDD那样纠正不连贯的预测。
这些讨论表明,GIDD开创的自我修正方向可能会在未来AI研究中产生深远影响。
随着这项技术的发展,我们可能会看到更智能、更灵活的语言模型,它们不仅能生成内容,还能不断优化和完善自己的输出。
当 AI 也能学会了「知错能改」,你觉得这将带来哪些变革?
相关链接
-
论文链接:https://www.arxiv.org/abs/2503.04482
-
GitHub代码库:https://github.com/dvruette/gidd
-
HuggingFace模型库:https://huggingface.co/collections/dvruette/generalized-interpolating-discrete-diffusion-67c6fc45663eafb85c6487af
-
Colab演示:https://colab.research.google.com/drive/1Xv4RyZhXHkIpIZeMYahl_4kMthLxKdg_?usp=sharing
(文:AGI Hunt)