
机器之心发布
在 ChatGPT 爆火两年多的时间里,大语言模型的上下文窗口长度基准线被拉升,以此为基础所构建的长 CoT 推理、多 Agent 协作等类型的高级应用也逐渐增多。
随之而来的是,长文本推理速度被提出更高要求,而基于现有 Transformer 架构的模型受限于注意力机制的二次方复杂度,难以在较短时延内处理超长文本请求。
针对这一痛点,清华大学 NLP 实验室联手中南大学、北京邮电大学以及腾讯微信 AI 实验室取得了突破,共同提出了 APB 框架 —— 其核心是一个整合了稀疏注意力机制的序列并行推理框架,通过整合局部 KV 缓存压缩方式以及精简的跨 GPU 通信机制,解决了长上下文远距离语义依赖问题,在无性能损失的前提下大幅度提升超长文本预填充的效率。
在 128K 文本上,APB 能够出色地平衡性能与速度,达到相较于传统 Flash Attention 约 10 倍的加速比,在多种任务上甚至具有超越完整 Attention 计算的性能;与英伟达提出的同为分布式设定下的 Star Attention 相比,APB 也能达到 1.6 倍加速比,在性能、速度以及整体计算量上均优于 Star Attention。

-
论文链接:https://arxiv.org/pdf/2502.12085
-
GitHub 链接:https://github.com/thunlp/APB
这一方法主要用于降低处理长文本请求的首 token 响应时间。未来,APB 有潜力运用在具有低首 token 响应时间要求的模型服务上,实现大模型服务层对长文本请求的高效处理。
瓶颈:加速长文本预填充效率
长文本预填充的效率受到计算的制约。由于注意力机制的计算量与序列长度呈二次方关系,长文本的计算通常是计算瓶颈的。主流加速长文本预填充的路线有两种,提升并行度和减少计算:
-
提升并行度:我们可以将注意力机制的计算分布在不同设备上来提升并行度。当一个 GPU 的算力被充分的利用时,简单的增加 GPU 的数量就可以增加有效算力。现存研究中有各种各样的并行策略,包括张量并行、模型并行、序列并行等。对于长文本推理优化,序列并行有很大的优化潜力,因为它不受模型架构的制约,具有很好的可扩展性。
-
减少计算:另一个加速长文本预填充的方式是减少计算,即使用稀疏注意力。我们可以选择注意力矩阵中计算的位置,并不计算其他位置来减少整体的计算量。此类方法通常会带来一定的性能损失。计算时忽略重要的上下文会导致无法处理某些任务。
然而,简单地提升并行度和减少计算并不能在加速长文本预填充上取得足够的效果。若要将二者结合又具有极大挑战,这是因为稀疏注意力机制中,决定计算何处注意力通常需要完整输入序列的信息。在序列并行框架中,每个 GPU 仅持有部分 KV 缓存,无法在不通过大规模通信的前提下获得足够的全局信息来压缩注意力的计算。
针对这一问题,有两个先驱方法:一是英伟达提出的 Star Attention ,直接去除了序列并行中的所有通信,并只计算每个 GPU 上局部上下文的注意力,但这样计算也导致了很大程度的性能损失;二是卡内基梅隆大学提出的 APE,关注 RAG 场景下长文本预填充加速,通过将上下文均匀分割、对注意力进行放缩和调整 softmax 温度,实现并行编码,同样在需要远距离依赖的场景上有一定的性能损失。
区别于上述方法,APB 通过设计面向序列并行场景的低通信稀疏注意力机制,构建了一个更快、性能更好,且适配通用长文本任务的长文本加速方法。
APB:面相序列并行框架的稀疏注意力机制
相较于之前的研究,APB 通过如下方法提出了一种面相序列并行框架的稀疏注意力机制:
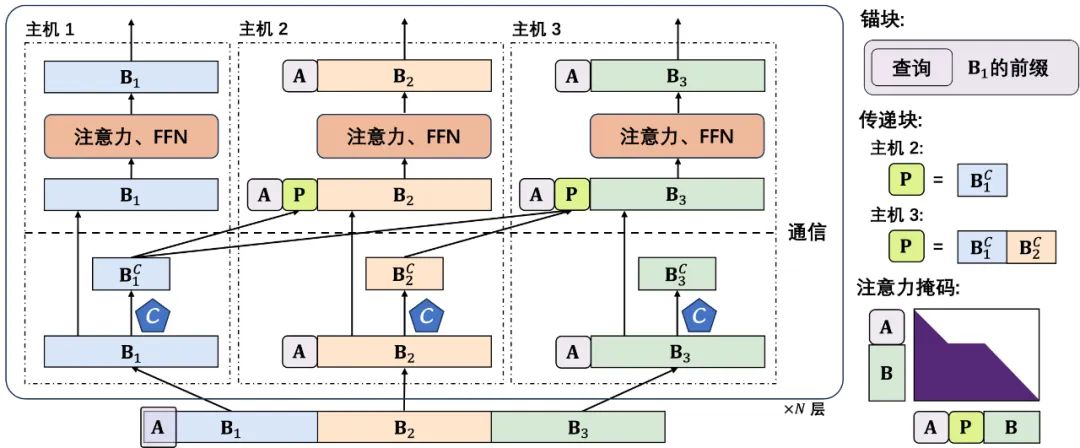
-
增加较小的 Anchor block:Star Attention 中引入的 Anchor block(输入序列开始的若干 token)能够极大恢复性能,然而其尺寸需要和局部上下文块一样大。过大的 anchor block 会在 FFN 中引入过多的额外开销。APB 通过减少 anchor block 的大小,使其和上下文块的 1/4 或 1/8 一样大。
-
解决长距离语义依赖问题:先前研究某些任务上性能下降的原因是它们无法处理长距离语义依赖,后序 GPU 分块无法看到前序上下文块中的信息,导致无法处理特定任务。APB 通过构建 passing block 的方式来解决这一问题。Passing block 由前面设备上的重要 KV 对组成。每个上下文块先被压缩,然后将被压缩的上下文块通信到后续 GPU 上来构建 passing block。
-
压缩上下文块:在不进行大规模通信的前提下,每个设备只对自己持有的上下文有访问权限。因此,现存的 KV Cache 压缩算法(例如 H2O 和 SnapKV)不适用于这一场景,因为它们依赖全序列的信息。然而,该特点与 Locret 一致,KV Cache 重要性分数仅仅与对应 KV 对的 Q, K, V 相关。APB 使用 Locret 中引入的 retaining heads 作为上下文压缩器。
-
查询感知的上下文压缩:APB 在 anchor block 的开头嵌入查询。当预填充结束时,这些查询可以随着 anchor block 一同被丢弃,不会影响整体计算的同时还能让上下文压缩器看到查询的内容。通过这种方式,保留头能够更精准地识别出查询相关的 KV 对,并通过通信机制传给后续设备。
以此机制为基础,APB 的推理过程如下:
-
上下文分割:长文本被均匀的分到每个设备上,开头拼接一个 anchor block,其中包含了查询问题。
-
上下文压缩:我们用 Locret 引入的保留头来压缩 KV Cache。
-
通信:我们对压缩过的 KV Cache 施加一个 AllGather 算子。每个设备会拿到前序设备传来的压缩缓存,并构建 passing block。
-
计算:我们使用一个特殊的 Flash Attention Kernel 来实现这个特殊的注意力机制。我们更改了注意力掩码的形状。Passing block 在注意力计算结束后就被删除,不参与后续计算。
APB 实现更快、性能更好的长文本推理
团队使用 Llama-3.1-8B-instruct, Qwen-2.5-14B-instruct 以及 Yi-34B-200K 模型在 InfiniteBench 和 RULER 上进行了测试,测量任务性能(%)以及处理完整长文本请求的推理速度(tok /s)。研究人员选择 Flash Attention, Ulysses, Ring Attention, MInference 以及 Star Attention 作为基线算法,实验结果如下:
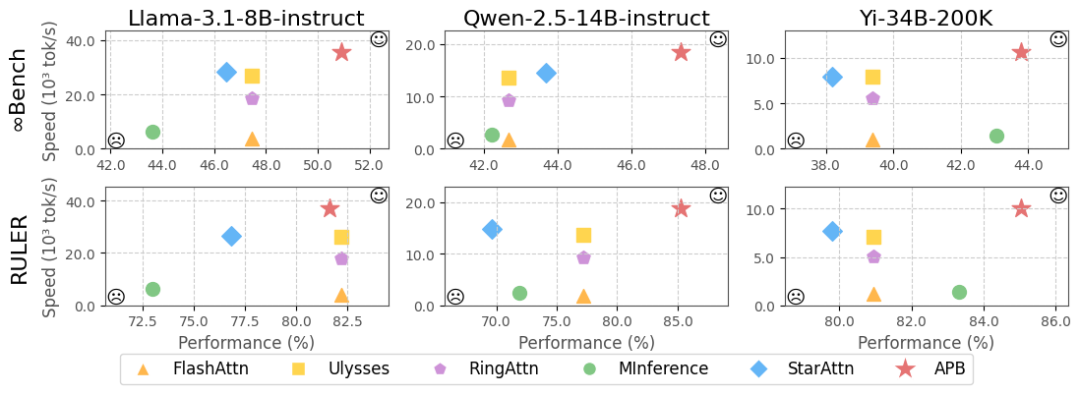
从上图可见,Flash Attention 作为无序列并行的精准注意力算法,具有较好的任务性能,但推理速度最慢;Ring Attention 和 Ulysses 作为序列并行的精准注意力算法,通过增加并行度的方式提升了推理速度;MInference 是一种无序列并行的稀疏注意力机制,表现出了一定的性能损失;Star Attention 作为序列并行与稀疏注意力结合的最初尝试,具有较好的推理速度,然而表现出了显著的性能下降。
相较于基线算法,APB 在多种模型和任务上表现出更优的性能和更快的推理速度。这意味着,APB 方法能够实现最好的任务性能与推理速度的均衡。
除此之外,研究人员在不同长度的数据上测量了 APB 与基线算法的性能、速度,并给出了整体计算量,结果如下:
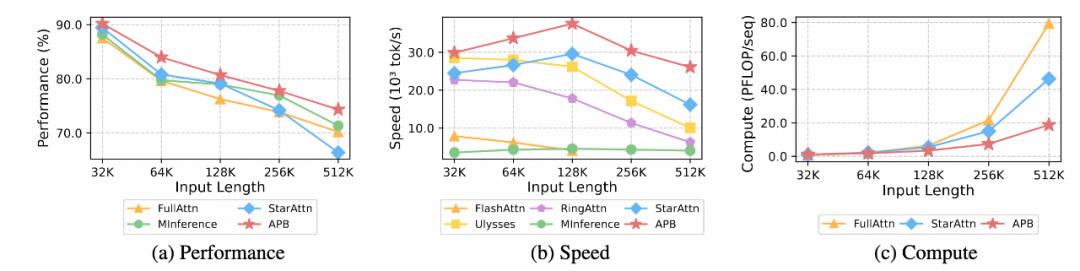
可以从上图中看到,APB 在各种输入长度下均表现出更优的任务性能与推理速度。速度优势随着输入序列变长而变得更加明显。APB 相较于其他方法更快的原因是它需要更少的计算,且计算量差异随着序列变长而加大。
并且,研究人员还对 APB 及基线算法进行了预填充时间拆解分析,发现序列并行可以大幅度缩减注意力和 FFN 时间。
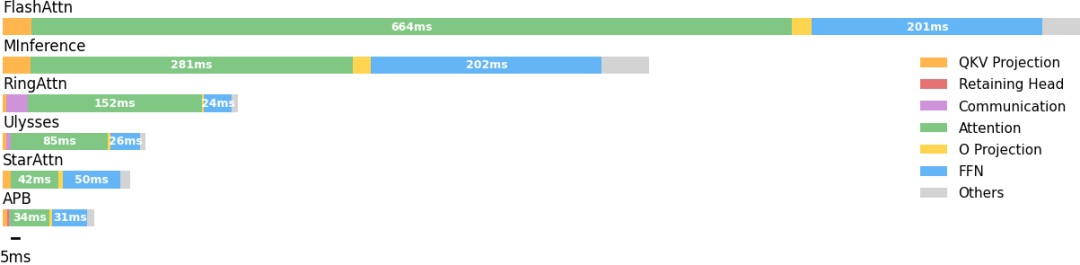
通过稀疏注意力机制,APB 能进一步缩减注意力时间。Star Attention 由于使用了过大的 anchor block,其 FFN 的额外开销十分明显,而 APB 由于使用了 passing block 来传递远距离语义依赖,能够大幅度缩小 anchor block 大小,从而降低 FFN 处的额外开销。
APB 支持具有卓越的兼容性,能适应不同分布式设定(显卡数目)以及不同模型大小,在多种模型和分布式设定下均在性能与推理速度上取得了优异的效果。
核心作者简介
黄宇翔,清华大学四年级本科生,THUNLP 实验室 2025 年准入学博士生,导师为刘知远副教授。曾参与过 MiniCPM、模型高效微调、以及投机采样研究项目。主要研究兴趣集中在构建高效的大模型推理系统,关注模型压缩、投机采样、长文本稀疏等推理加速技术。

李明业,中南大学三年级本科生,2024 年 6 月份加入 THUNLP 实验室实习,参与过投机采样研究项目。主要研究兴趣集中在大模型的推理加速,例如投机采样以及长文本推理加速等。

(文:机器之心)