

随着人工智能技术的飞速发展,多模态学习逐渐成为研究热点。多模态模型通过结合视觉、音频和文本等多种模态信息,能够更全面地理解和解释复杂场景。然而,现有的多模态模型大多集中在图像与文本的结合,对于更复杂的全模态场景(如视频情感识别)的支持仍显不足。阿里通义实验室开源的 R1-Omni 模型,首次将强化学习与可验证奖励(RLVR)技术应用于全模态情感识别任务,为多模态模型的发展带来了新的突破。
一、项目概述
多模态模型在处理复杂任务时,往往难以清晰地解释各个模态信息如何协同工作。例如,在情感识别任务中,视觉信息(如面部表情)和音频信息(如语调)都对情感判断至关重要,但现有模型难以明确展示这些模态信息的具体贡献。R1-Omni 通过引入 RLVR 技术,旨在解决这一问题,使模型的推理过程更加透明。

R1-Omni 的主要目标是探索 RLVR 技术在全模态场景中的应用潜力,特别是在情感识别任务中,验证其在提升推理能力和泛化能力方面的优势。通过结合视频、音频和文本等多种模态信息,R1-Omni 能够更准确地识别和解释情感。
二、功能特点
1、透明性与可解释性
R1-Omni 的一大亮点是其透明性。通过 RLVR 方法,模型能够清晰地展示各个模态信息在情感识别中的作用。例如,在分析视频时,R1-Omni 可以明确指出哪些视觉和音频特征对特定情感的判断起到了关键作用。
2、强大的推理能力
与传统的监督微调(SFT)模型相比,R1-Omni 在推理能力上有显著提升。在多个情感识别数据集上,R1-Omni 的性能明显优于其他模型,尤其是在处理复杂情感和分布外(OOD)数据时。
3、泛化能力
R1-Omni 在分布外数据集(如 RAVDESS)上的表现尤为突出,其泛化能力显著优于其他模型。这表明 R1-Omni 不仅在训练数据上表现出色,还能在未见过的场景中保持良好的性能。
三、技术架构
1、基础模型
R1-Omni 基于HumanOmni-0.5B模型开发,这是一个开源的全模态大语言模型。该模型结合了视频、音频和文本等多种模态信息,为情感识别任务提供了强大的基础。
2、强化学习与可验证奖励(RLVR)
R1-Omni 的核心技术是 RLVR,即强化学习与可验证奖励。通过 RLVR,模型能够在训练过程中动态调整权重,优化推理过程,从而更好地结合多模态信息。RLVR 的引入使得 R1-Omni 在推理能力和泛化能力上都取得了显著提升。
3、多模态融合
R1-Omni 通过融合视觉(如 Siglip 模型)和音频(如 Whisper 模型)信息,实现了多模态的协同工作。这种融合方式不仅提升了模型的性能,还使得模型的推理过程更加直观和可解释。
四、评测结果
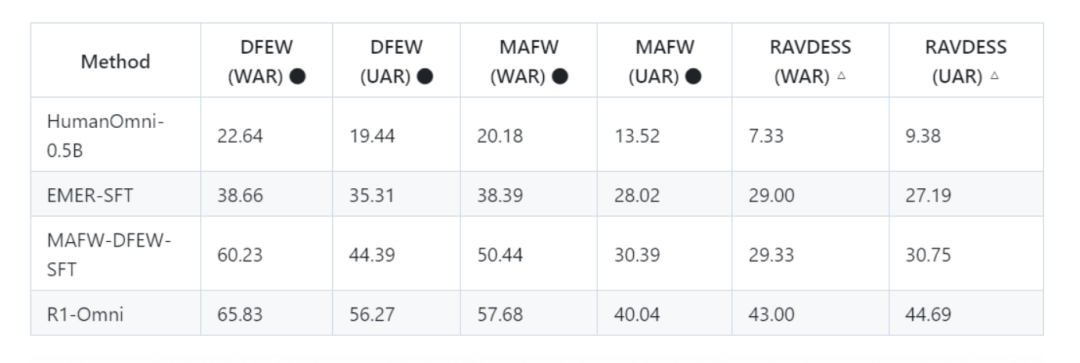
1、性能对比:在多个情感识别数据集上,R1-Omni 的性能显著优于其他模型。例如,在 DFEW 数据集上,R1-Omni 实现了 65.83% 的 UAR 和 56.27% 的 WAR,明显优于 MAFW-DFEW-SFT 的 60.23% UAR 和 44.39% WAR。在 RAVDESS 数据集上,R1-Omni 的 UAR 和 WAR 分别达到了 43.00% 和 44.69%,相较于其他模型有显著提升。
2、泛化能力:R1-Omni 在分布外数据集上的表现尤为突出。在 RAVDESS 数据集上,R1-Omni 的性能提升超过 13%,这表明其在未见过的场景中仍能保持良好的性能。
五、应用场景
1、情感分析:R1-Omni 可用于社交媒体管理、舆情监测和消费者情感分析等场景。通过分析用户的情感表达,企业可以更有效地与目标用户互动,优化产品和服务。
2、心理健康评估:在心理健康领域,R1-Omni 可以分析患者的情绪表达,辅助专业人士进行评估和干预。这种应用不仅可以提高评估的准确性,还能为患者提供更个性化的治疗方案。
3、教育领域:在在线教育中,R1-Omni 可以分析学生的情绪反应,帮助教师调整教学策略。例如,通过识别学生的困惑或焦虑情绪,教师可以及时调整教学内容或方式。
六、快速使用
1、环境准备
R1-Omni 基于R1-V 框架开发。在开始之前,请确保按照 [R1-V 仓库](https://github.com/HumanMLLM/R1-V) 中的安装说明完成环境配置。
2、下载模型
R1-Omni 提供了以下预训练模型供下载:
-
HumanOmni-0.5B:基础全模态模型。
-
EMER-SFT:冷启动模型。
-
MAFW-DFEW-SFT:在 MAFW 和 DFEW 数据集上直接微调的模型。
-
R1-Omni:最终强化学习模型。
3、配置文件更新
下载模型后,需要更新配置文件 `config.json`,以确保模型能够正确加载依赖的子模块。例如,更新 `config.json` 文件中的路径如下:
“`json
{
“mm_audio_tower”: “/path/to/local/models/whisper-large-v3”,
“mm_vision_tower”: “/path/to/local/models/siglip-base-patch16-224”
}
“`
4、单视频推理
使用 `inference.py` 脚本进行单视频推理。运行以下命令:
python inference.py --modal video_audio \--model_path ./R1-Omni-0.5B \--video_path video.mp4 \--instruct "As an emotional recognition expert; throughout the video, which emotion conveyed by the characters is the most obvious to you? Output the thinking process in <think> </think> and final emotion in <answer> </answer> tags."
– `–modal`:指定输入模态(如 `video_audio` 表示同时使用视频和音频)。
– `–model_path`:指定 R1-Omni 模型路径。
– `–video_path`:指定待推理视频路径。
– `–instruct`:推理指令,用于引导模型输出。
七、结语
R1-Omni 作为阿里通义实验室开源的全模态情感识别模型,不仅在技术上取得了显著突破,还在多个应用场景中展现了巨大的潜力。通过引入 RLVR 技术,R1-Omni 在推理能力和泛化能力上都取得了显著提升。未来,随着技术的进一步发展,R1-Omni 有望在更多领域发挥重要作用。
项目地址
GitHub 仓库:https://github.com/HumanMLLM/R1-Omni
技术论文:https://arxiv.org/abs/2503.05379
模型下载:https://www.modelscope.cn/models/iic/R1-Omni-0.5B
HuggingFace 模型库:https://huggingface.co/StarJiaxing/R1-Omni-0.5B
(文:小兵的AI视界)