




智东西3月12日报道,刚刚,谷歌发布Gemma 3系列模型。谷歌博客中说,这是其迄今为止最先进、最便携、最负责任开发的开放式模型,是“世界上最好的单GPU模型”。
Gemma 3采用与Gemini 2.0相同的研究和技术,支持超过35种语言,并能够分析文本、图像和短视频。
其优势在于可以直接在手机、PC、工作站上快速运行,参数规模有1B、4B、12B和27B四种,开发者可以根据特定硬件和性能需求选择。


▲Gemma 3技术报告
Hugging Face地址:
https://huggingface.co/blog/gemma3
Kaggle地址:
https://www.kaggle.com/models/google/gemma-3
论文地址:
https://storage.googleapis.com/deepmind-media/gemma/Gemma3Report.pdf

4月1-2日,智东西联合主办的2025中国生成式AI大会(北京站)将举行。20+位嘉宾/企业已确认,将围绕DeepSeek、大模型与推理模型、具身智能、AI智能体与GenAI应用带来分享和讨论。更多嘉宾陆续揭晓。欢迎报名~
按Chatbot Arena Elo分数对AI模型进行排名:分数越高(排名越靠前的数字)表明越受用户青睐。下方的圆点表示模型对英伟达H100 GPU的需求,Gemma 3 27B模型排名很高,其他模型可能需要多达32块GPU,Gemma 3 27B仅需一块GPU即可运行。
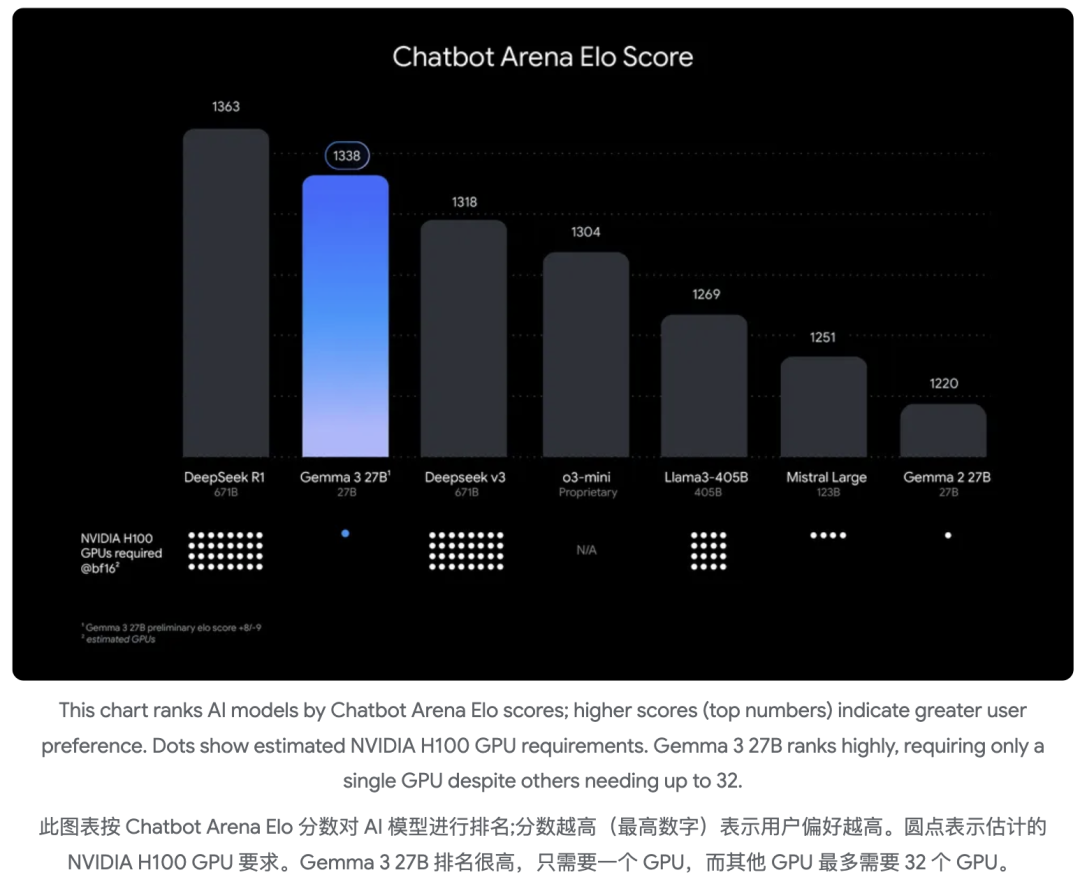
▲Chatbot Arena评估分数越高越受青睐(下方原点指模型运行需要使用的英伟达H100数量)
从Chatbot Arena评测结果来看,Gemma-3-27B-IT得分超过DeepSeek-V3、o1-preview等模型。其论文中提到,所有模型均由人类评分员通过盲目并排评估,每个模型都根据Elo评分系统获得一个分数,Gemma-3-27B-IT是2025年3月8日收到的初步结果。


▲视觉识别
除了Gemma 3,谷歌还推出了基于Gemma 3构建的4B参数图像安全检查器ShieldGemma 2。
ShieldGemma 2可以输出三个类别的安全标签:危险内容、露骨色情和暴力。开发人员可以根据他们的安全需求和用户进一步定制ShieldGemma。
Gemma 3遵循与Gemma 2类似的方法进行知识提炼的预训练。
训练数据方面,研究人员在比Gemma 2稍大的token预算上对模型进行预训练,即在Gemma 3 27B上使用14T tokens,在12B版本上使用12T tokens,在4B版本上使用4T tokens,在1B版本上使用2T tokens。token的增加解释了预训练期间使用的图像和文本的混合。
此外,研究人员还增加了多语言数据量以提高语言覆盖率,并添加了短语和并行数据等。
Tokenizer(分词器)方面,研究人员使用与Gemini 2.0相同的Tokenizer:具有拆分数字、保留空格和字节级编码的SentencePiece Tokenizer,生成的词汇表有262k个条目,此Tokenizer对于非英语语言来说更加平衡。
Gemma 3使用过滤技术降低不必要或不安全的言论风险,并删除某些个人信息和其他敏感数据。其会从预训练数据混合物中净化评估集,并通过最大限度地减少敏感输出的扩散来降低风险。
研究人员为每个token抽取256个logit,并按教师概率加权。学生通过交叉熵损失在这些样本中学习教师的分布。对于非抽样logit,教师的目标分布设置为零概率,并重新规范化。
开发者现在可以将Gemma 3和ShieldGemma 2无缝集成到现有的工作流程中。
英伟达API目录:
https://build.nvidia.com/search?q=gemma
(文:智东西)