

-
在这场变革性的技术交替之际,回顾搜推广模型的历史演进,抓住三条关键路径(明线、暗线和辅助线)有助于更清晰地理解技术升级的内在逻辑。同时,明确如何在新时期系统性发挥算力优势,深度挖掘搜推广领域的 Scaling Law,已成为推动技术进步的核心路线。 -
作为新技术探索的前哨站,预估模型通过与大模型的深度结合,全面提升感知与推理能力。在感知层面,专注于解决内容语义信息与行为协同信息的融合问题,持续优化多模态表征的质量,突破传统 ID 表征体系的局限,逐步实现对客观世界更丰富的感知建模;在推理层面,构建用户行为序列大模型,将生成式方法与判别式方法有机结合,探索推理能力的持续进化之路。 -
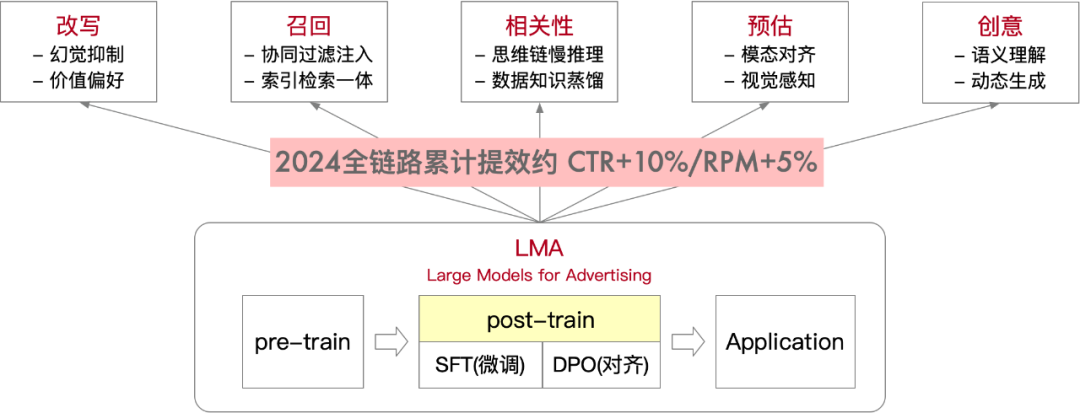
大模型正在全面重塑搜索广告系统。依托预训练(pre-train)与后训练(post-train)的模型迭代新范式,阿里妈妈自主研发了广告领域专属大模型 LMA(Large Models for Advertising),并于 2024 年 4 月随业务宣推。LMA 是电商基座大模型衍生出来的广告模型集合,迭代分支包括认知、推理和决策。新财年以来,LMA 持续优化,认知分支聚焦多模态表征,推理分支聚焦搜推广领域的用户行为大模型等。这些技术进展不仅推动预估环节实现多个版本迭代上线,还深度改造了召回、改写、相关性和创意等核心技术模块,推动技术体系全面升级。
-
明线,归纳偏置(Inductive Bias)的合理设计,是模型能力提升的核心驱动力。 -
暗线,硬件算力的指数级提升,为模型的规模化提供了强力支撑。 -
辅助线,CV 和 NLP 领域的代际性技术升级,给搜推广领域带来重要启发。

-
AlexNet 在 ImageNet 竞赛中的突破性成功表明了 DNN 巨大潜力,搜推广开启 DNN 时代;
-
Word2Vec 奠定了表征基础,启发了 Embedding 技术在搜推广的广泛应用;
-
Attention 机制对翻译任务的大幅提升,深刻影响用户行为兴趣建模;
-
基于 Transformer 结构的训练范式的普及,推动了对比学习、掩码学习、预训练 & 迁移学习等各种迭代模式的兴起。
-
一方面,从算力(暗线)角度来看,Scaling Law 在稀疏的 Wider 方向已经清晰呈现出第一增长曲线,新时期需要探索稀疏往稠密的转变,走出 Deeper 的新增长;
-
另一方面,从归纳偏置(明线)角度来说,人工先验的归纳偏置由精细化设计往朴素化范式转变。正如《The Bitter Lesson》所言:“AI 发展史最苦涩的教训是:试图将我们认为的思维方式硬编码进 AI,长期来看是无效的。唯一重要的,是那些能够随着计算能力增长而扩展的通用方法”。这一点尤为感同身受,过去依赖精巧结构设计的短期收益,往往在算力提升的长期趋势下变得微不足道,甚至某些复杂结构反而成为算力扩展的障碍。真正支撑生产服务的模型,最终仍会朝着紧凑、简约、高效的方向收敛,以适应计算资源的可扩展性和实际业务需求。
-
训练模式,包括分类、对比学习、掩码学习、自回归学习等,且 backbone 紧随主流更迭,包括 BEiT3、BGE、BLIP2、EVA2 等。
-
数据质量,图文质量包括视觉强相关的主体和关键词识别,难正负样本挖掘,结合行业特色挖掘兴趣样本例如拍立淘的图搜场景等。
-
规模效应,包括图片尺寸、训练样本和模型参数,模型尺寸经历了 0.1B、1B 和 10B 的升级过程,是 Deeper 方向规模化的主要路径。


-
【LUM】Unlocking Scaling Law in Industrial Recommendation Systems with a Three-step Paradigm based Large User Model
-
论文链接:https://arxiv.org/abs/2502.08309
-
【UQABench】UQABench: Evaluating User Embedding for Prompting LLMs in Personalized Question Answering
-
论文链接:https://arxiv.org/abs/2502.19178

(文:机器之心)