

©作者 | 中科院自动化所李国齐课题组
脉冲神经网络(SNN)因其生物合理性和低功耗特性,被视为人工神经网络(ANN)的潜在替代方案。然而,SNN 在实际应用中面临性能差距和训练成本高的挑战。
为此我们提出了一种脉冲发放近似(SFA)方法,通过整数训练和脉冲驱动推理优化脉冲神经元的发放模式。此外,我们开发了高效的脉冲驱动 Transformer 架构和脉冲掩码自动编码器,以防止 SNN 在模型参数量扩展过程中性能下降。
在 ImageNet-1k 数据集上,我们的模型(10M、19M、83M、173M 参数)分别实现了 78.5%、79.8%、84.0% 和 86.2% 的准确率。例如,10M 参数模型比现有最佳 SNN 准确率高 7.2%,训练速度提升 4.5 倍,推理能效提高 3.9 倍。
我们在目标检测、语义分割和神经形态视觉等任务中验证了方法的有效性和高效性。这项工作使 SNN 在保持低功耗的同时达到与 ANN 相当的性能,标志着 SNN 向通用视觉主干网络迈出重要一步。

论文标题:
Scaling Spike-driven Transformer with Efficient Spike Firing Approximation Training
论文链接:
https://arxiv.org/pdf/2411.16061
代码链接:
https://github.com/BICLab/Spike-Driven-Transformer-V3

背景
脉冲神经网络(SNNs)因其受大脑启发的时空动态特性和高效的脉冲驱动计算范式而备受关注。脉冲神经元遵循“积分–发放”模型,通过二进制脉冲进行通信,将空间和时间信息整合到膜电位中。当膜电位超过阈值时,神经元发出脉冲并重置膜电位,仅在接收到脉冲时触发稀疏加法运算。
当部署 SNN 到神经形态芯片(如 Speck 芯片 [1])上时,其会展现出显著的低功耗优势,静息功耗低至 0.42mW 同时在典型边缘视觉场景中功耗仅为 0.7mW。
在深度学习时代,模型规模对现代机器智能的成功至关重要,脉冲神经网络(SNN)也在不断扩展规模。目前,大规模 SNN 的训练方法主要有两种:ANN2SNN [2] 和直接训练 [3][4]。
ANN2SNN 通过脉冲发放率近似人工神经网络的激活值,实现了较高的准确率,但需要大量推理时间步长,且放弃了 SNN 的时空动态特性。
直接训练则利用时空反向传播(STBP)[3] 和替代梯度 [4] 进行训练,保留了 SNN 的时空动态特性,但高时间步长模拟需要大量计算资源。例如,对 10 个时间步长的 ResNet-19 进行直接训练,所需内存是传统 ResNet-19 的 20 倍 [5]。
一些文章 [2] 通过延长时间步长可以减少量化误差,从而提升性能,但高时间步长的模拟需要大量 GPU 内存,增加了训练难度,限制了 SNN 的可扩展性和性能提升。
现有观点认为,量化误差是主要问题,但我们进一步证明,二进制脉冲发放是根本机制缺陷,削弱了脉冲神经元评估输入信号重要性的能力(空间表征)和记忆与遗忘能力(时间动态特性)。现有方法(如 ANN2SNN 和直接训练)通过速率编码解决空间表征问题,但训练效率低下,且无法克服时间动态特性的限制。
为解决上述问题,我们提出了脉冲发放近似(SFA)方法。SFA 在训练期间使用整数激活值,推理期间将其转换为脉冲序列,形成异步连续的脉冲发放模式。与 ANN2SNN 和直接训练的同步随机发放不同,SFA 的发放模式显著提升了训练效率、推理功耗、性能和网络扩展能力。
为进一步提升 SNN 性能,我们改进了 Meta-SpikeFormer [6] 的架构设计,升级了卷积和脉冲驱动的自注意力算子,提出了 E-SpikeFormer。E-SpikeFormer 在性能和能效上均有提升。
为解决扩展时性能下降的问题,我们设计了脉冲稀疏卷积(SSC),并结合掩膜图像建模(MIM)预训练策略,显著提升了模型的表现。
所提出的方法在多个任务上得到验证,包括静态图像分类、目标检测、语义分割和神经形态动作识别。我们成功扩展了 SNN 的规模,并在所有测试数据集上取得了当前最优的结果,为 SNN 的大规模应用奠定了坚实基础。

本文主要贡献
2.1 重新思考脉冲神经元机制
我们先深入剖析普通脉冲神经元的积分、发放及重置机制,发现二元脉冲发放是影响脉冲神经元空间表示与时间动态的关键机制缺陷。具体表现为:
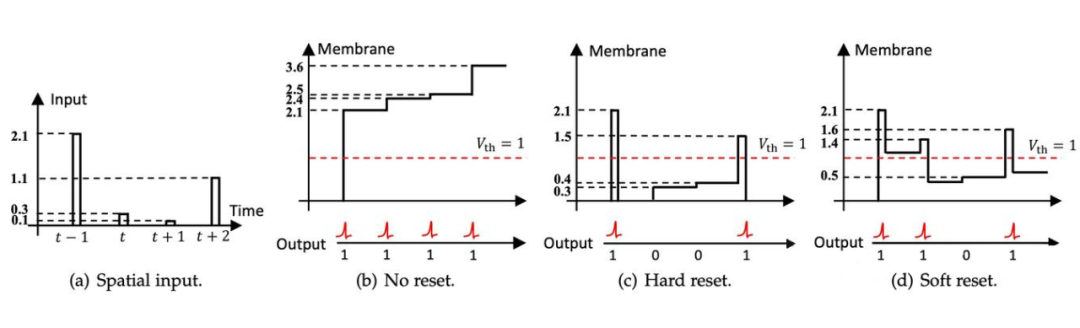
其一,普通脉冲神经元无法评估当前空间输入的重要性。不管膜电位大小,输出皆为单个脉冲,这相当于在膜电位向脉冲转换时存在显著量化误差。
其二,普通脉冲神经元无法执行与数据相关的记忆或遗忘操作。因其脉冲发放值仅能为 0 或 1,意味着软复位只能遗忘固定值。
以图 1 中脉冲神经元为例,假设第 个时间步长的空间输入极为重要(数值大)。硬复位时,脉冲神经元输出一个脉冲,膜电位清零至重置电位,这显然存在较大量化误差,无法体现输入的重要性。而软复位时,脉冲神经元输出一个脉冲,传递到下一时间步长的膜电位依然很大。
如此一来,后续脉冲神经元可能长时间持续发放,致使无法判断第 t 个时间步长的发放是由第 个时间步长的空间输入,还是当前空间输入所致(如图 1(d)所示)。所以,软复位可能在每个时间步长产生相同的记忆和遗忘问题。
▲ 图1
2.2 脉冲发放近似(SFA)方法
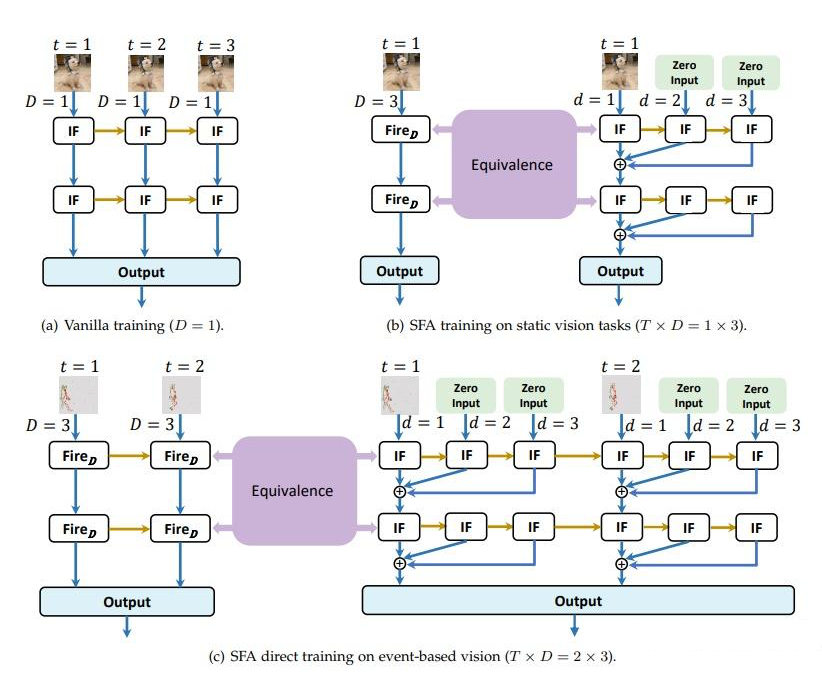
为解决二值脉冲发放机制的缺陷,我们提出了脉冲发放近似(SFA)方法。如图 2 所示,SFA 利用整数训练与脉冲序列推理的等价性,优化 SNN 的脉冲发放模式。
SFA 方法分为三步:首先,假设脉冲神经元在空间维度传输脉冲发放率;其次,训练阶段采用整数值激活近似脉冲发放率,减少量化误差,提升模型学习能力;最后,推理阶段将整数激活转换为多时间步的二元脉冲,扩展时间步长以实现高效推理。
▲ 图 2(a)
SFA 方法通过独特设计在静态和动态视觉任务中展现出显著优势。在静态任务中,SFA 仅需单步训练,大幅降低训练成本,并在推理时无需重复输入图像,提升效率并减少计算资源消耗。
在动态任务中,SFA 通过扩展时间步长克服了传统二元脉冲发放机制的缺陷,赋予脉冲神经元动态遗忘能力,显著提升模型性能。同时 SFA 方法在神经形态芯片上既可同步实现,适用于时间同步要求高的场景,也可异步实现,充分发挥低功耗和低延迟优势,尤其适合异步连续脉冲发放特性。

▲ 图 2(b)
同时,SFA 方法改变了脉冲的发射模式(如上图 2(b)所示)。假设近似值为 0.3(=0.3),即在十个时间步(D=10)内需要发射三个脉冲。对于 ANN2SNN 和直接训练 SNN,三个脉冲出现的时间步是同步或随机的,其中同步发射意味着必须完成所有十个时间步,才能计算脉冲发射率。
相比之下,SFA 训练在前三个时间步发射脉冲后,不会在其余七个时间步发射脉冲。因此,SFA 中的脉冲发射可以以异步的方式实现。
2.3 E-SpikeFormer 架构
Meta-SpikeFormer [5] 探索了脉冲神经网络在脉冲驱动自注意力机制(SDSA)、架构和快捷连接方面的元设计。
在此基础上,我们致力于设计一种更高效的脉冲神经网络,将其命名为 E-SpikeFormer (见下图3)。E-SpikeFormer 结合了卷积和基于 Transformer 的 SNN 模块,每个模块包含令牌混合器和通道混合器。以下是我们的主要改进:

▲ 图3
1. 去除 RepConv:我们移除了 Meta-SpikeFormer 中高能耗的重参数化卷积(RepConv),代之以轻量级的脉冲可分离卷积(SpikeSepConv),从而显著降低了能耗。
2. 基于卷积的 SNN 模块:我们将令牌混合器替换为 SpikeSepConv,优化后的结构如下:
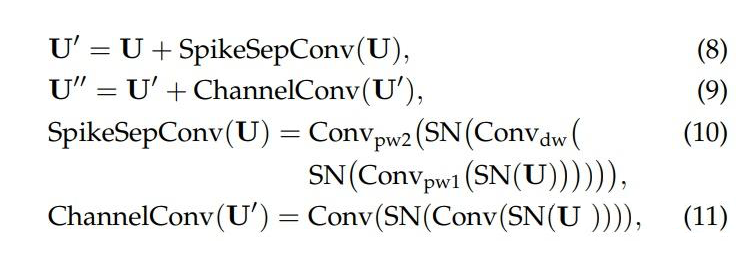
其中,SpikeSepConv 通过深度卷积和逐点卷积结合脉冲神经元层实现。
3. 基于 Transformer 的 SNN 模块:我们在 SDSA 模块前添加了 SpikeSepConv,以增强局部特征提取,优化后的结构为:

4. 高效脉冲驱动自注意力(E-SDSA):我们用线性操作替代 RepConv 生成 、、:

通过这些优化,我们的 E-SpikeFormer 在降低能耗的同时大幅度提升了模型精度,使其可以适用于各种视觉任务。
2.4 脉冲稀疏卷积
我们发现直接对视觉 Transformer(ViT)[7] 进行规模扩展会导致性能下降,这一问题同样出现在我们提出的 E-SpikeFormer 中。
为了解决这一问题,我们采用了预训练-微调的掩码图像建模(MIM)[7] 范式,并结合脉冲稀疏卷积(SSC)编码器,提出了 MIM-SNN 方法(见下图 4)。该方法流程如下:

首先进行掩码操作,我们首先对输入图像进行补丁块级别的掩码操作。将图像 重新组织为一系列展平的二维补丁块,生成随机二进制掩码 ,从而获得两个互补的掩码视图 和 。
接下来我们介绍编码器。掩码图像与神经形态数据类似,仅在亮度变化时触发事件,因此包含大量空白区域。由于脉冲驱动的特性,SNN 中的卷积本质上是稀疏卷积。然而,普通脉冲卷积(VSC)在 MIM-SNN 中会导致信息泄露,因为它在所有位置执行卷积,导致深层脉冲神经元几乎不再发放脉冲(脉冲退化)。
为解决这一问题,我们提出了脉冲稀疏卷积(SSC),它仅在未被掩码的区域执行卷积。具体来说,我们将输入特征 \(X_1\) 在 \(d\) 维空间中重塑,并使用核权重 进行 SSC 处理。SSC 的卷积过程表示为:
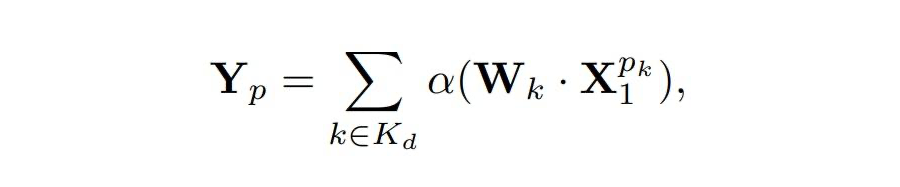
其中, 是选择器,决定是否参与计算。我们在预训练阶段使用 SSC,微调阶段则将权重转换回VSC。这一方法有效避免了信息泄露,提升了模型性能。。
之后我们介绍解码器。编码器的输出与可学习的掩码令牌一起提供给解码器,解码器将掩码令牌重建为图像。在预训练期间,我们采用普通的 ANN(Transformer)作为解码器,在微调时将其移除。
最后是损失函数在预训练中,我们使用均方误差(MSE)损失作为度量函数:
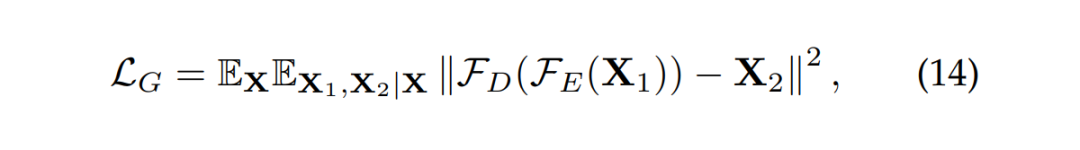
其中, 是解码器的输出, 表示 范数。同时在微调阶段,我们采用了蒸馏(distillation)技术,这与 Meta-SpikeFormer [6] 中的方法一致。

实验结果
3.1 图像分类
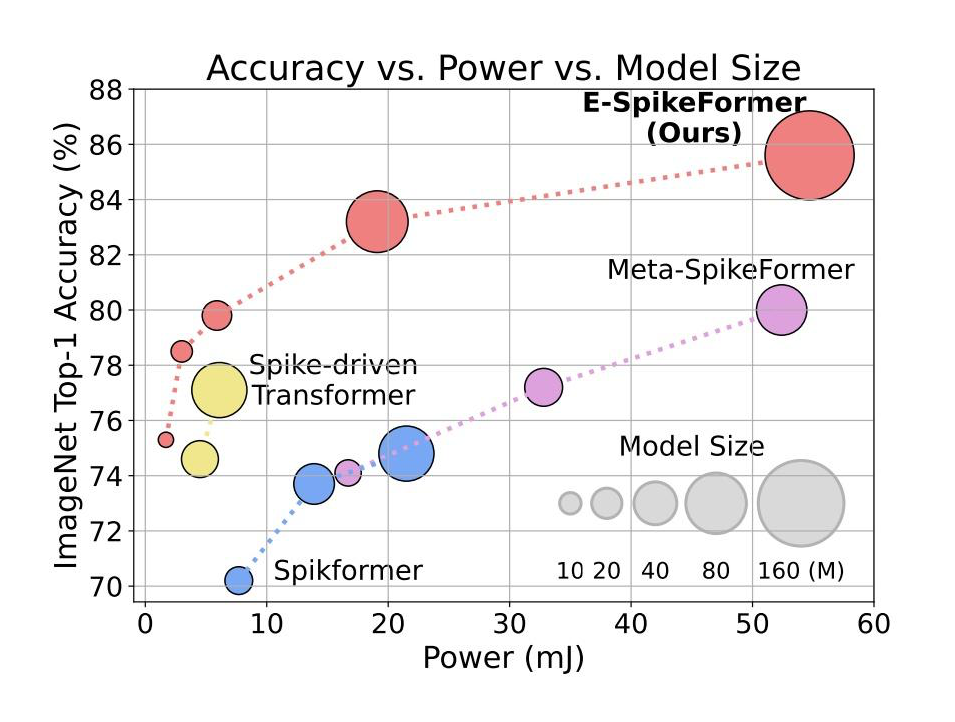
在 ImageNet-1k 数据集上,E-SpikeFormer 在不同模型规模下均取得优异成绩。例如,如图 5,6 所示,10M 参数模型的 Top-1 准确率达到 78.5%,比之前最好的 SNN(71.3%)高 7.2%,训练时间加速 4.5 倍(从 63 小时缩短到 14 小时),推理能效提高 3.9 倍(从 11.9mJ 降低到 3.7mJ)。
在 172M 参数规模下,E-SpikeFormer 的 Top-1 准确率高达 86.2%,超越了许多经典 ANN 模型(如 ConvNeXt-B 的 83.8% 和 CrossFormer-L 的 84.0%),同时功耗仅为 19.1mJ,远低于 ANN 模型的 70.8mJ(ConvNeXt-B)和 74.1mJ(CrossFormer-L)。
这些结果表明,E-SpikeFormer 在图像分类任务中不仅性能优异,还具备显著的能效优势。
▲ 图5

▲ 图6
3.2 目标检测
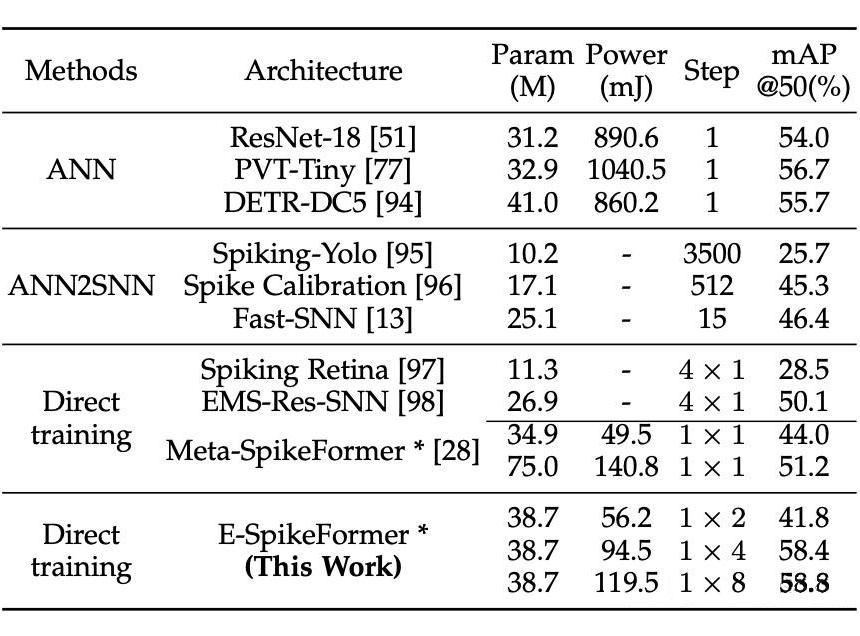
在目标检测任务中,E-SpikeFormer 在 COCO 数据集上达到 SOTA 结果。例如,E-SpikeFormer 的参数数量为 3870万,mAP@0.5 为 58.8%,功耗为 119.5mJ,优于 Meta-SpikeFormer(参数 7500 万,mAP@0.5 为 51.2%,功耗 140.8mJ)和 PVT-Tiny(参数 3290 万,mAP@0.5 为 56.7%,功耗 1040.5mJ)。
E-SpikeFormer 在 mAP@0.5 上超越 Meta-SpikeFormer,同时功耗显著低于 PVT-Tiny,展示了其在目标检测任务中的高效性和性能优势。
3.3 语义分割
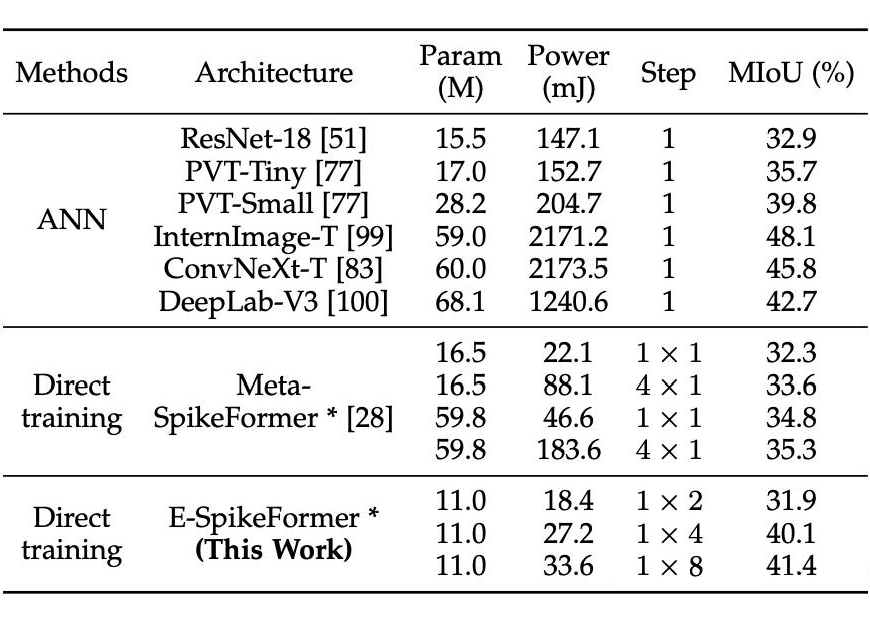
在语义分割任务中,E-SpikeFormer 在 ADE20K 数据集上表现优异。例如,E-SpikeFormer 的参数数量为 11 M,MIoU 为 41.4%,功耗为 33.6mJ,相比 Meta-SpikeFormer(参数 59.8 M,MIoU 为 35.3%,功耗 183.6mJ)在 MIoU上提升 6.1%,同时功耗降低 81.7%。这一结果证明了 E-SpikeFormer 在语义分割任务中的高效性和准确性。
3.4 神经形态人类动作识别
在神经形态人类动作识别任务中,E-SpikeFormer 在 HAR-DVS 数据集上验证了其有效性。例如,E-SpikeFormer 的准确率为 92.5%,相比 Meta-SpikeFormer(90.8%)提升 1.7%。在时间步长 T=8 的设置下,E-SpikeFormer 在直接训练方式下表现出色,进一步验证了其在神经形态任务中的高效性和性能提升。

3.5 消融实验
通过消融实验,我们验证了 SFA 训练和 E-SpikeFormer 架构设计的有效性。例如,基线模型在加入 SFA 后,时间步设置从 4×1 改为 1×4,功耗从 11.9mJ 降低到 7.3mJ(降低 4.6mJ),准确率从 71.3% 提升到 77.8%(提升 6.5%)。
进一步结合 E-SpikeFormer 架构后,功耗从 7.3mJ 降低到 3.7mJ(降低 4.3mJ),准确率从 77.8% 提升到 78.5%(提升 0.7%)。这表明 SFA 策略比现有的直接训练 SNN 方法更有效、更高效,同时所提出的高效架构设计在降低功耗的同时进一步提高了准确率。


讨论
4.1 SFA 在功率和性能方面的优势
脉冲发放近似(SFA)方法通过引入一种全新的脉冲发放模式,显著优化了脉冲神经网络(SNNs)的功耗和性能。我们通过分析网络脉冲发放率(NSFR)和脉冲分布情况,揭示了 SFA 的优化机制。
首先,SFA 方法在功耗优化方面表现出色。实验表明,采用 SFA 训练的 SNN 在不同时间步长下的脉冲发放率逐渐降低(图 7),而常规训练的脉冲发放率则保持较高且稳定(图 8)。
图 7 中的脉冲图进一步验证了这一点:SFA 训练的脉冲图从左到右颜色由红变蓝,表明脉冲发放率随时间步长增加而减少,而常规训练的脉冲图颜色变化不明显。
此外,SFA 训练的最高脉冲发放率为 0.19,远低于常规训练的 0.78,表明 SFA 显著降低了脉冲发放密度,从而减少了计算能耗。
其次,SFA 方法在性能优化方面也有显著优势。通过将脉冲图在时间和通道维度上平均,SFA 训练的脉冲特征更加清晰,且发放率更低(图 7 最右侧的脉冲图)。这表明 SFA 方法能够更有效地提取关键信息,同时减少冗余脉冲,从而提升模型的性能和效率。

▲ 图7

4.2 为什么二元脉冲发射机制不利于SNN的扩展
本中,我们从编码器设计的角度分析了直接扩展 E-SpikeFormer 导致性能下降的原因。这一问题的根源在于,掩膜图像建模(MIM)中的掩膜操作会使得常规脉冲卷积泄露信息。为此,我们提出了脉冲稀疏卷积(SSC)来解决这一问题。此外,我们还观察到二进制脉冲发放会干扰脉冲神经网络(SNNs)的扩展。
通过实验,我们从两个正交角度分析了 SNN 的扩展情况:是否采用 MIM-SNN 预训练,以及使用脉冲发放近似(SFA)方法还是直接训练。
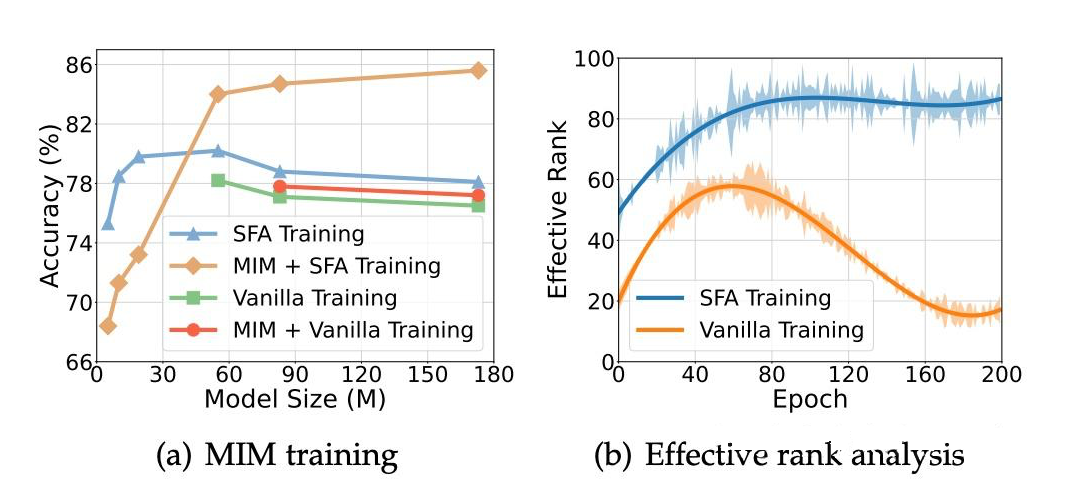
如图 9(a)所示,当使用 SFA 方法并结合 MIM 策略时,SNN 能够有效扩展(橙色曲线)。然而,在常规训练中,即使采用 MIM 策略,性能仍会下降(红色曲线),这表明二进制脉冲发放限制了模型的扩展能力。
我们认为,二进制脉冲发放影响了 MIM-SNN 编码器的特征提取能力。通过有效秩(Rank)来衡量特征提取能力,我们发现:在常规训练的 MIM-SNN 中,有效秩在训练过程中逐渐下降(图 9(b)),表明特征表示坍缩到低维空间,损害了模型的泛化能力和任务性能。
相比之下,采用 SFA 方法的 MIM-SNN 在训练过程中有效秩增加并趋于稳定,表明模型具有更稳健的特征表示和更好的微调性能。
▲ 图9
4.3 SFA在神经形态芯片上的实现
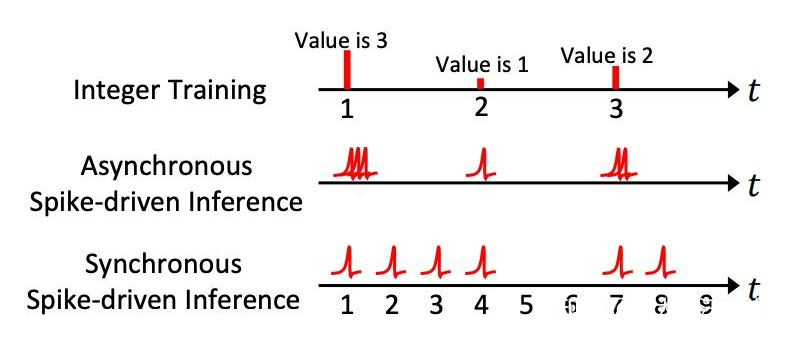
常规训练和 SFA 训练的脉冲发放模式存在显著差异。在 ANN2SNN 和常规直接训练中,多个时间步长的脉冲发放是随机的,而 SFA 训练中的脉冲则是集中且连续的。这种差异决定了它们在神经形态芯片上的实现机制不同。图 10 展示了 SFA 方法在神经形态芯片上的两种实现方式:
1. 同步实现:整数激活值被同步转换为脉冲。同步神经形态芯片利用全局时钟,将 T 个时间步长扩展为 T×D 个时间步长。这种方式适用于静态和动态视觉任务,且“天机”芯片支持此类操作。
2. 异步实现:异步神经形态芯片在极短的时间窗口内发出一系列脉冲(最多 D 个)。由于没有全局时钟,脉冲神经元独立工作,仅在事件输入时激活,其余时间处于空闲状态。Speck 芯片支持这种实现方式。
SFA 方法在神经形态芯片上具有显著优势:其兼容性使其可通过同步或异步芯片实现,而常规训练的脉冲神经网络因依赖全局时钟难以在异步芯片上运行;在能效与延迟方面,当 D 值较小且脉冲发放率较低时,SFA 的异步实现显著降低功耗和延迟,尽管存在通信带宽超载风险,但风险可控。
此外,D 值对能耗的影响因任务而异,例如在图像分类任务中,D 值从 1×4 调整为 1×8 导致的能耗增加幅度高于目标检测和语义分割任务。综上所述,SFA 方法的独特脉冲发放模式使其与异步神经形态芯片高度兼容,为算法驱动的芯片设计提供了重要参考。
▲ 图10
4.4 神经形态芯片自然支持MIM-SNN预训练
脉冲卷积在神经形态芯片上以脉冲驱动的方式执行,通过逐个事件的稀疏处理实现低延迟和低功耗的优势。系统状态随每个脉冲输入动态更新,SNN 核心通过地址搜索识别权重和目标神经元位置,并更新目标神经元状态。为解决 MIM-SNN 预训练中的信息泄露问题,我们提出了脉冲稀疏卷积(SSC)。
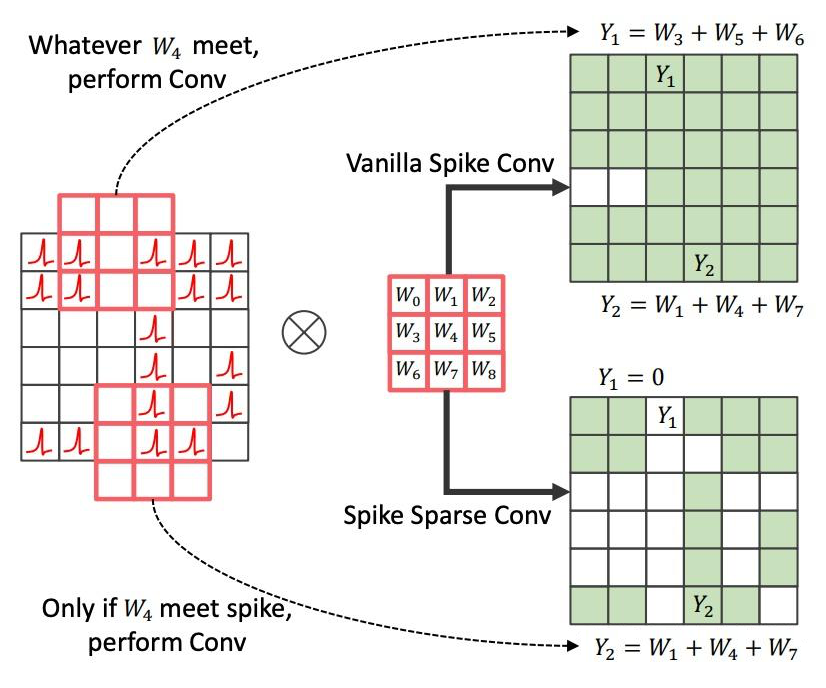
如图 11 所示,与常规脉冲卷积(VSC)相比,SSC 仅在卷积核中心位置有脉冲输入时执行卷积操作,确保信息传递到下一层的相应位置。这一特性在 MIM 编码器中尤为重要,因为大部分信息需要被掩膜处理。
SSC 通过记录掩膜位置,仅在未掩膜区域操作,从而避免信息泄露。由于 VSC 和 SSC 的共性,只需对 VSC 的寻址映射函数稍作修改,即可在神经形态芯片上实现 SSC,支持基于 MIM 预训练的片上学习。
▲ 图11

(文:PaperWeekly)