跳至内容
「压缩即智能」。这并不是一个新想法,著名 AI 研究科学家、OpenAI 与 SSI 联合创始人 Ilya Sutskever 就曾表达过类似的观点。甚至早在 1998 年,计算机科学家 Jose Hernandez-Orallo 就已经在论文《A Formal Definition of Intelligence Based on an Intensional Variant of Algorithmic Complexity》中有过相关的理论论述。
近日,卡内基梅隆大学 Albert Gu 领导的一个团队进一步证明了这一想法。据介绍,他们的研究目的是通过实验来解答一个简单又基本的问题:无损信息压缩本身能否产生智能行为?
-
博客地址:https://iliao2345.github.io/blog_posts/arc_agi_without_pretraining/arc_agi_without_pretraining.html
-
项目地址:https://github.com/iliao2345/CompressARC
该团队写到:「在这项工作中,通过开发一种纯粹基于压缩的方法,我们的证据证明:推理期间的无损压缩足以产生智能行为。」
该方法在 ARC-AGI 上表现优良,而 ARC-AGI 是一个类似智商测试的谜题数据集,被测模型需要根据有限的演示推断出程序 / 规则。
基于此,该团队将这个方法命名为 CompressARC,其符合以下三个限制:
-
-
无需数据集;模型仅在目标 ARC-AGI 谜题上进行训练并输出一个答案。
-
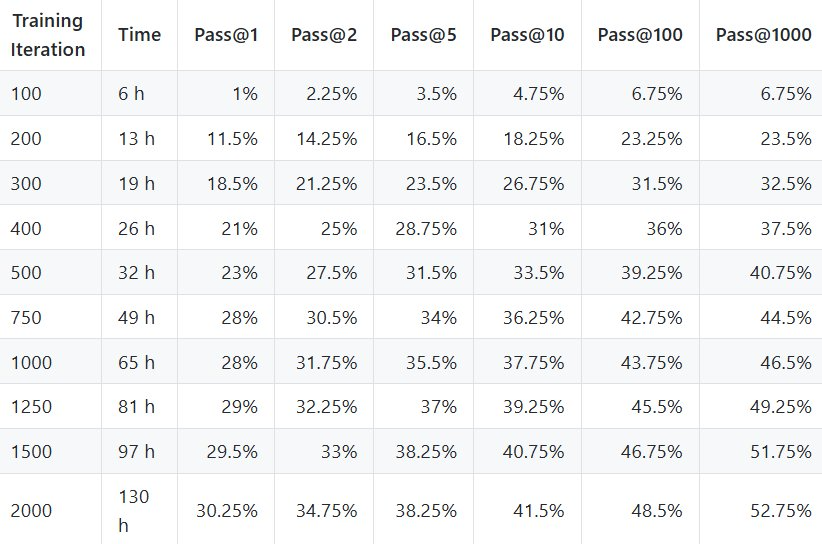
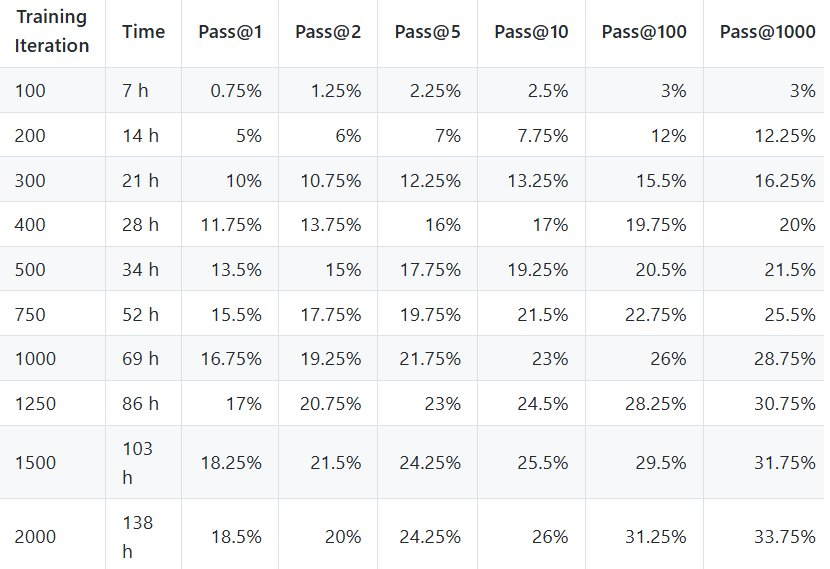
尽管存在这些限制,但 CompressARC 还是在训练集上实现了 34.75% 的准确度,在评估集上实现了 20% 的准确度。
处理时间方面,在 RTX 4070 上,处理每个谜题的时间大约为 20 分钟。
该团队表示:「据我们所知,这是首个训练数据仅限于目标谜题的用于解决 ARC-AGI 的神经方法。」
他们特别指出:CompressARC 的智能并非源自预训练、庞大的数据集、详尽的搜索或大规模计算,而是源自压缩。「对于依赖大量预训练和数据的传统,我们发起了挑战,并展现了一种未来,即经过定制设计的压缩目标和高效的推理时间计算共同发力,从而可以从最少的输入中提取出深度智能。」
ARC-AGI 提出于 2019 年,这个 AI 基准的目标是测试系统从少量示例中归纳总结出抽象规则的能力。
该数据集中包含一些类似 IQ 测试的谜题:先展示一些演示底层规则的图像,然后给出需要补全或应用该规则的测试图像。下面展示了三个示例:
每个谜题都有一个隐藏规则,可将每个输入网格映射到每个输出网格。被测试者将获得一些输入映射到输出的示例,并且有两次机会(Pass@2)猜测给定输入网格的输出网格。
如果任何一个猜测是正确的,那么被测试者将获得该谜题的 1 分,否则将获得 0 分。被测试者可以更改输出网格的大小并选择每个像素的颜色。
一般来说,人类通常能合理地找到答案,而机器目前还较难解决这个问题。普通人可以解决 76.2% 的训练集,而人类专家可以解决 98.5%。
有 400 个训练谜题会比其他谜题更容易,其目的是帮助被测试者学习以下模式:
-
Objectness(事物性):事物会持续存在,不会无缘无故地出现或消失。物体能否交互取决于具体情况。
-
目标导向性:事物可以是动态的或静止的。有些物体是「智能体」—— 它们有意图并会追求目标。
-
数字和计数:可以使用加法、减法和比较等基本数学运算,根据物体的形状、外观或运动对它们进行计数或分类。
-
基本几何和拓扑:物体可以是矩形、三角形和圆形等形状,可以执行镜像、旋转、平移、变形、组合、重复等操作。可以检测到距离差异。
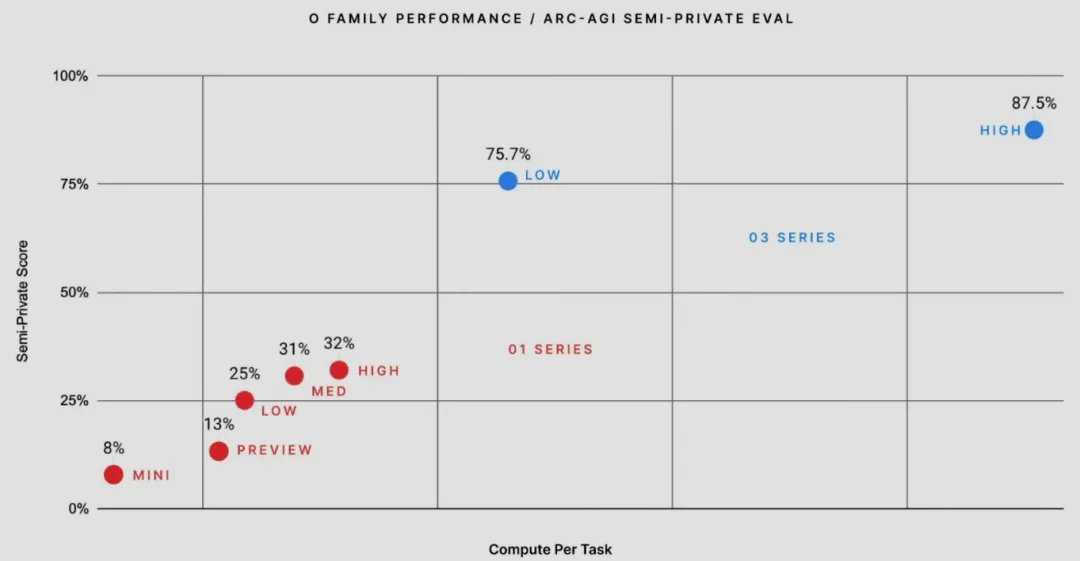
ARC Prize 团队曾多次发起解决 ARC-AGI 的竞赛,并提供金钱奖励。最近的一次竞赛涉及高达 100 万美元的潜在奖金,主要奖金留给了能够在受限环境中使用 12 小时计算,在 100 个谜题的私有测试集上实现 85% 成功率的方法。
此前,OpenAI 曾宣布 o3 模型在 ARC-AGI 基准可达到 87.5% 的水平,被广泛认为是重大的历史性突破,参阅报道《刚刚,OpenAI 放出最后大惊喜 o3,高计算模式每任务花费数千美元》。
Albert Gu 领导的团队提出,无损信息压缩可以作为解决 ARC-AGI 谜题的有效框架。谜题的一个更高效(低比特)压缩就对应于一个更准确的解。
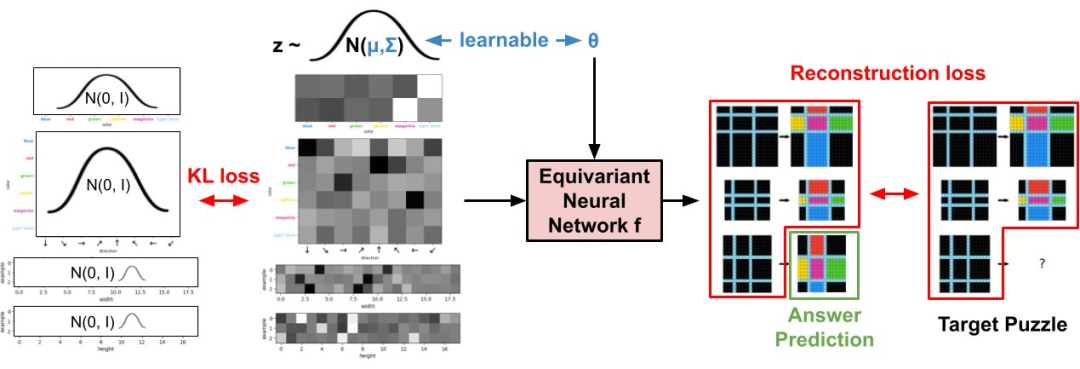
为了解答 ARC-AGI 谜题,该团队设计了一个系统,可以将不完整的谜题转换成完整的(填入答案),方法是寻找一个紧凑的表示,而当对这个表示进行解压缩时,就会重现有任意解的谜题。这个方法的关键难题是在没有答案作为输入的前提下获得这种紧凑的表示。
CompressARC 使用了一个神经网络作为解码器。然而,编码算法却不是一个神经网络——相反,编码是由梯度下降算法实现的,该算法在解码器上执行推理时间训练,同时保持正确的解码输出。
换句话说,运行该编码器就意味着优化解码器的参数和输入分布,从而获得经过最大压缩的谜题表示。
由此得到的优化版参数(例如,权重和输入分布设置)本身将作为经过压缩的比特表示,其编码了谜题与其答案。
如果用标准机器学习术语来描述:(没有压缩领域的术语,并进行了一些简化)
-
从推理时间开始,给出一个要解决的 ARC-AGI 谜题。(比如下图)
-
构建一个神经网络 f(参见架构),该网络是针对该谜题的具体情况(例如,示例数量、观察到的颜色)设计的。该网络采用了随机正态输入 z∼N (μ,Σ),并在所有网格(包括答案网格(3 个输入输出示例,总共 6 个网格))输出每像素颜色的 logit 预测。重要的是,f_θ 等价于与常见的增强手段 —— 例如重新排序输入输出对(包括答案对)、颜色排列和空间旋转 / 反射。
-
初始化网络权重 θ 并为 z 分布设置参数 μ 和 Σ。
-
联合优化 θ、μ 和 Σ,以最小化已知网格(其中 5 个)的交叉熵总和,同时忽略答案网格。使用一个 KL 散度惩罚使 N (μ,Σ) 接近 N (0,1),就像在 VAE 中一样。
-
由于 z 中的随机性,生成的答案网格是随机的,因此需要在整个训练过程中保存答案网格,并选择最常出现的网格作为最终预测。
为什么这种方法是在执行压缩?这里看起来并不那么显而易见。不过该团队在文章中通过压缩 ARC-AGI 推导了它,其中涉及信息论、算法信息论、编码理论和机器学习领域的知识,感兴趣的读者可访问原文了解。
现在,先试试解决上述谜题。下图展示了 CompressARC 的解题过程:
训练完成后,通过解构学习到的 z 分布(详见原文),可以发现它编码了颜色方向对应表和行/列分隔符位置!
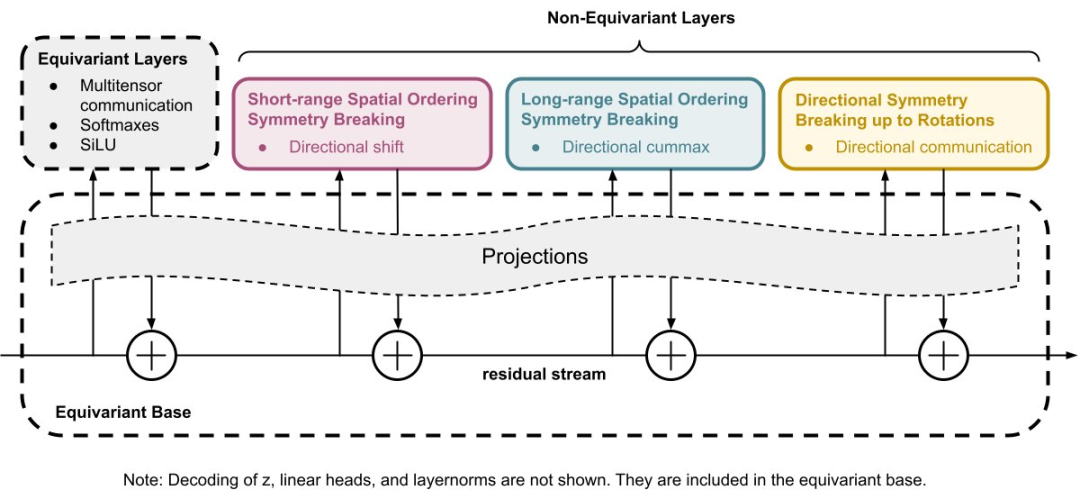
为了将隐含的 z 解码为 ARC-AGI 谜题,该团队设计了自己的神经网络架构。该架构最重要的特征是它的等变特性 —— 这是一些对称规则,规定了每当输入 z 发生变换时,输出 ARC-AGI 谜题也必须以相同的方式变换。例子包括:
等变的方式实在太多了,靠人力穷举实难办到,所以该团队决定打造一个完全对称的基础架构,并通过添加不对称层来逐一打破不必要的对称性,使其具有特定的非等变能力。
什么意思呢?假设 z 和 ARC-AGI 谜题都采用形状为 [n_examples, n_colors, height, width, 2 for input/output] 的张量形式(这实际上不是数据的格式,但它最能表达这个思路。)然后,网络开始与示例中的索引(颜色、高度和宽度维度)的排列等变。另外,在权重共享方面必须格外小心,以强制网络也与交换宽度和高度维度等变。然后,可以添加一个涉及宽度和高度维度的滚动层,让网络可区分短距离空间交互,但不区分长距离空间交互。
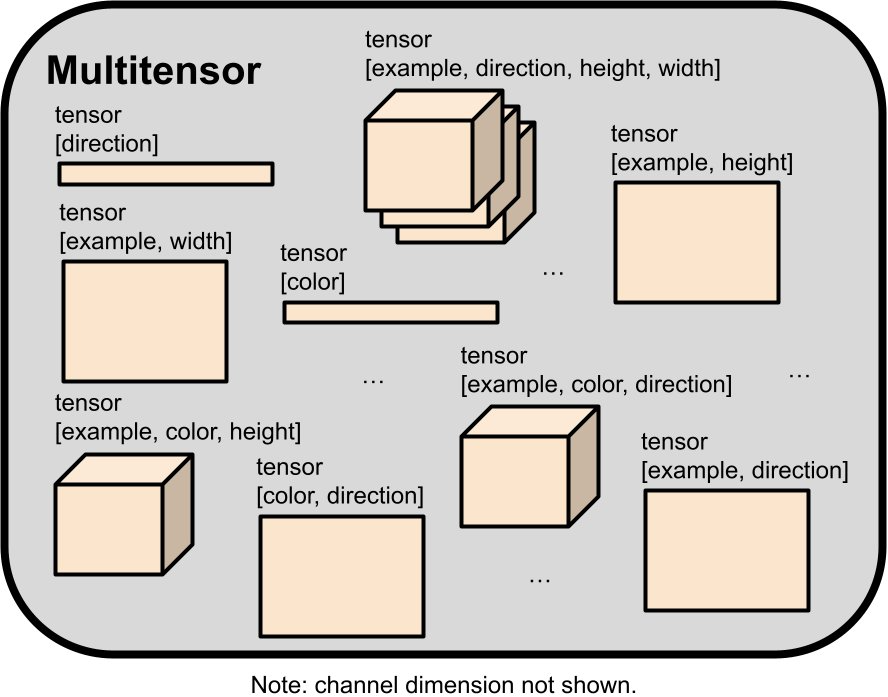
穿过各层的实际数据(z、隐藏激活和谜题)采用了所谓的「多张量(multitensor)」格式,其中包含各种形状的张量。所有等变都可被描述成它们对这个多张量的改变。
目前来说,大多数机器学习框架操作的都是具有恒定秩的单一类型的张量。比如 LLM 操作的是秩为 3 的张量,其形状为 [n_batch, n_tokens, n_channels],而 CNN 操作的则是秩为 4 的张量,其形状为 [n_batch, n_channels, height, width]。
而新的多张量则是由多个不同秩构成的张量组成的集合,其维度是一个形状为 [n_examples, n_colors, n_directions, height, width, n_channels] 的秩为 6 的张量的子集。其中 channel 维度总是会被保留,因此每个多张量最多有 32 个张量。
为了判定张量形状是否「合法」该团队还设定了一些规则(详见原文「其它架构细节」部分)。这样一来,多张量中张量的数量就减少到了 18 个。
那么,多张量是如何存储数据的呢?ARC-AGI 谜题可以表示成 [examples, colors, height, width, channel] 张量,其中 channel 维度可用于选择是输入还是输出网格、width/height 维度指定像素位置、color 维度是一个 one hot 向量(指示了该像素的颜色)。[examples,width,channel] 和 [examples,height,channel] 张量可以用于存储表示每个输入/输出网格的每个示例的网格形状的掩码。所有这些张量都被包含在单个多张量中,该多张量由该网络计算,就在最终的线性头层之前。
当操作多张量时,该团队默认假设所有非 channel 维度都被视为 batch 维度。除非另有说明,否则将在各个维度索引上执行同样的操作。这能确保所有对称性完好,直到使用旨在破坏特定对称性的某个层。
关于 channel 维度的最后一点说明:通常在谈论张量的形状时,我们甚至不会提及 channel 维度,因为它已被默认包含在内。
完整的架构由以下层组成,对它们的详细描述见原文附录:
-
-
-
4 组:多张量通信层(向上)、Softmax 层、方向 Cummax 层、方向移位层、方向通信层、非线性层、多张量通信层(向下)、归一化层
-
首先来看训练集正确率(Pass@2):34.75%。
该团队也详细分析了 CompressARC 能够和无法解决的问题。
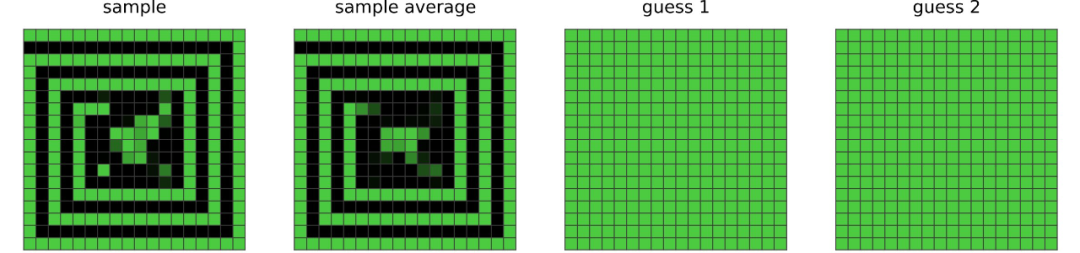
例如,训练集中的谜题 28e73c20 需要从边缘向中间扩展图案:
考虑到其网络中的层,CompressARC 通常能够扩展短距离的图案,但不能扩展长距离的图案。因此,它尽力正确地将图案延伸一小段距离,之后就开始猜测中间是什么:
这里通过一个案例来展示 CompressARC 的执行情况,更多案例请见附录。
在训练过程中,重建误差下降得非常快。它的平均水平保持在较低水平,但隔一段时间就会急剧上升,导致来自 z 的 KL 在这些时刻上升。
那么,CompressARC 如何学会了解答这个问题呢?为了找到答案,我们先看看 z 中存储的表示。
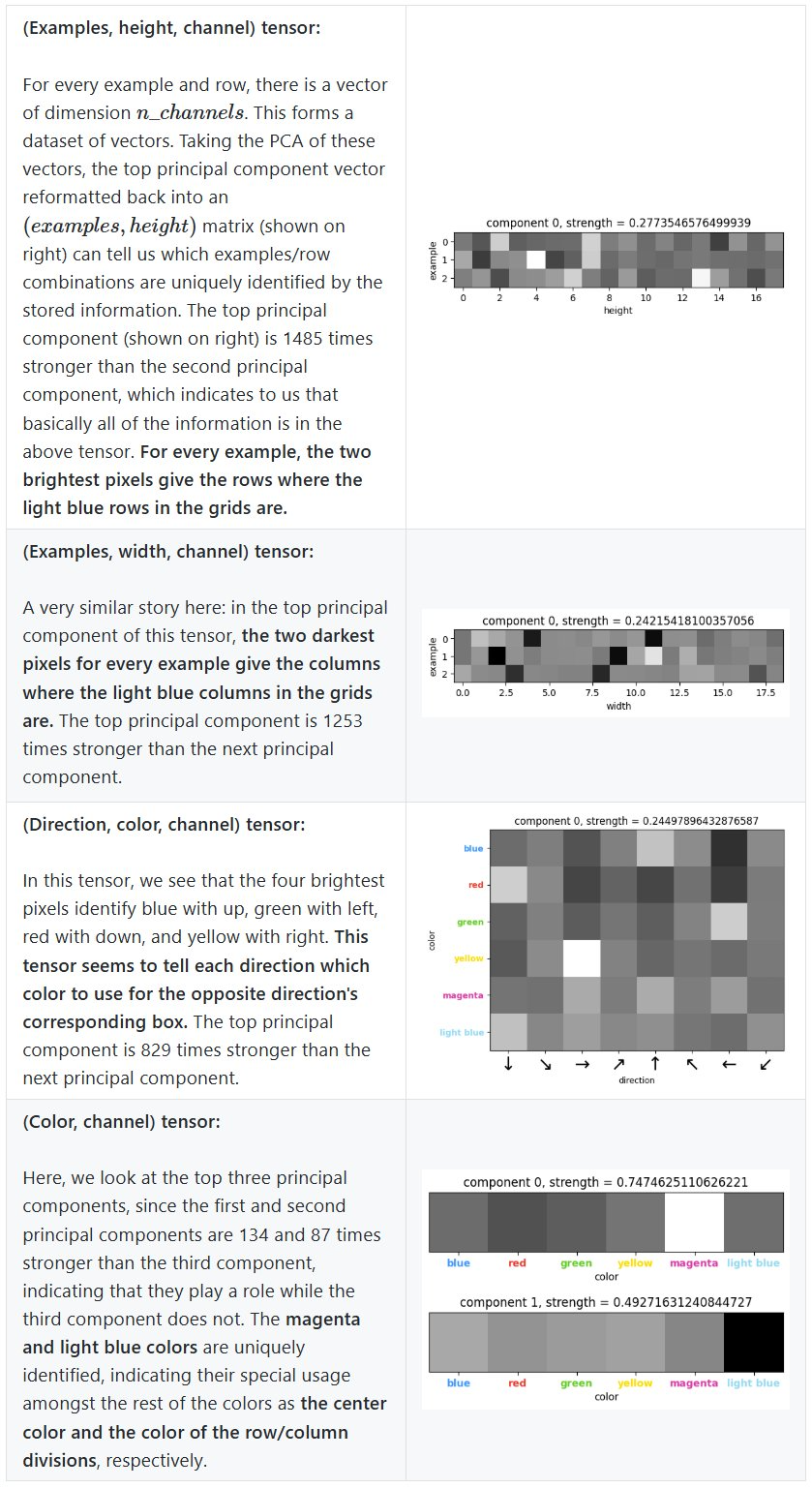
由于 z 是一个多张量,它包含的每个张量都会对 z 的总 KL 产生贡献。通过查看每个张量的贡献,可以确定 z 中的哪些张量编码了用于表示谜题的信息。下图展示了存储在 z 的每个张量中的信息量,即解码层使用的 KL 贡献。
除了四个张量外,所有张量在训练期间都降至零信息内容。在该实验的一些重复实验中,该团队发现这四个必要张量中的一个降至了零信息内容,并且 CompressARC 通常不会在那之后给出正确答案。
这里展示了一次幸运的运行,其中 (color,direction,channel) 张量几乎要没了但在 200 步时被拉起来了,这时模型中的样本开始在正确的方框中显示正确的颜色。
为了了解 z 中存储了哪些信息,可以查看与 z 的各个张量相对应的解码层的平均输出。每个张量包含一个维度为 n_channels 的向量,用于该张量的各种索引。对这些向量进行主成分分析(PCA)可以揭示一些激活分量,能让我们知道该张量编码了多少信息。
该团队还在原文中分享了更多细节,并给出了进一步的提升空间,感兴趣的读者请访问原文。
对于这项「压缩即智能」的实验研究成果,你有什么看法呢?
(文:机器之心)