
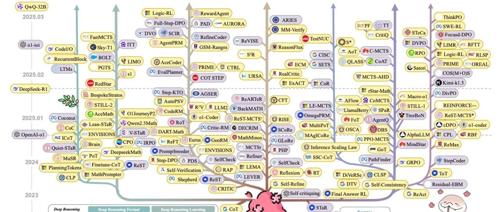
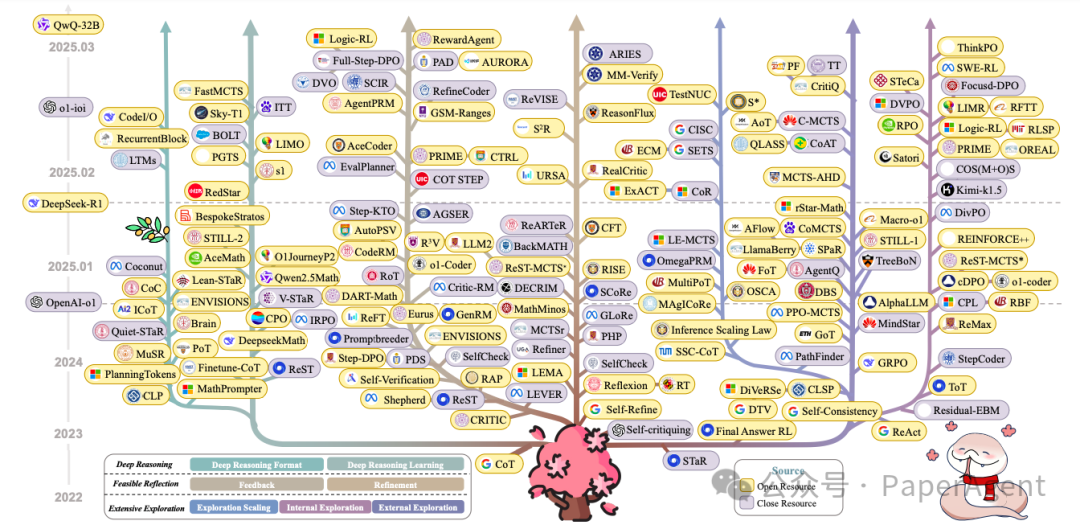

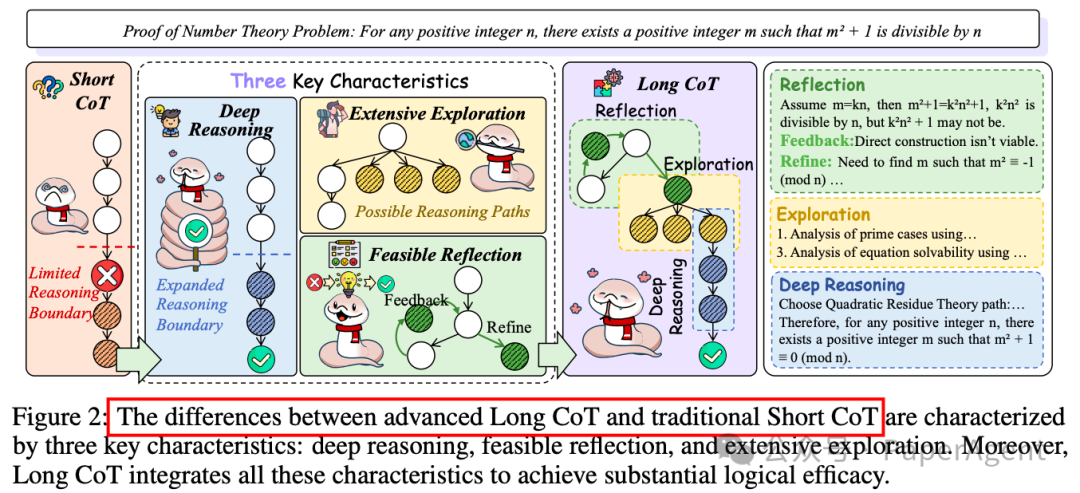
1. Short CoT 的特点
-
定义:Short CoT 是一种较为浅层的推理方式,通常涉及较少的逻辑节点(logical nodes),推理过程较为直接,逻辑链条较短。
-
推理深度:Short CoT 通常仅涉及简单的逻辑推理,难以处理复杂的多步骤问题。
-
效率:Short CoT 的推理过程快速且高效,适合处理简单或结构化的问题。
-
局限性:由于逻辑链条较短,Short CoT 在处理复杂问题时容易出现错误或无法得出正确结论,尤其是在需要深度逻辑分析的任务中。
2. Long CoT 的特点
-
定义:Long CoT 是一种深度推理方式,涉及更多的逻辑节点和更复杂的推理路径,能够处理复杂的多步骤问题。
-
推理深度:Long CoT 能够处理更复杂的逻辑结构,支持更深入的推理过程,适合解决需要多步骤分析的问题。
-
探索性:Long CoT 包含广泛的探索能力,能够通过生成并行的不确定节点来扩展推理边界,从而探索更多可能的解决方案。
-
反思性:Long CoT 强调对推理过程的反思和修正,能够通过反馈机制优化推理路径,减少错误。
-
适用性:Long CoT 在数学、编程、科学推理等需要深度逻辑分析的领域表现出色,能够显著提升模型的推理能力和准确性。
对长链推理进行了深入分析和评估,探讨了其在推理大型语言模型中的作用、现象、机制以及面临的挑战:
2.1 Long CoT的外部行为分析(External Behavior Analysis)
Long CoT的六种外部行为现象分析
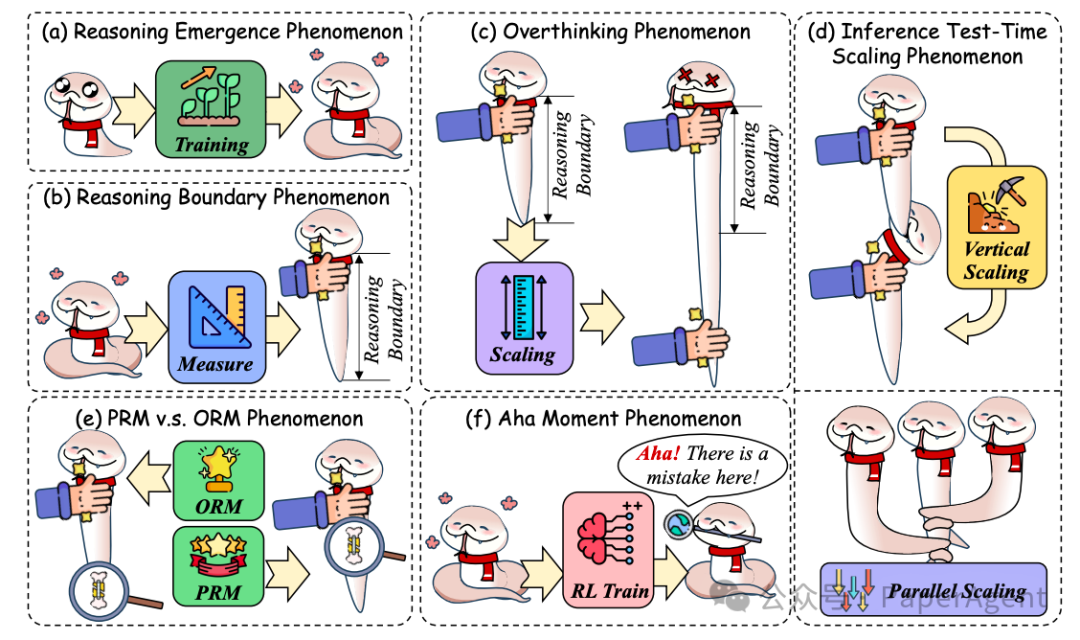
-
Long CoT的出现现象:研究表明,上下文示例能够引导模型生成推理链,标准化推理链的生成过程。通过实验发现,仅保留逻辑结构的上下文示例也能实现与完整示例相似的性能,强调了Long CoT在推理中对逻辑结构的模仿能力。
-
推理边界的限制:研究指出,RLLMs在推理任务中存在性能上限,当任务复杂度超过模型的推理边界时,性能会下降。例如,在代码生成任务中,模型在处理复杂逻辑时会遇到困难。此外,模型的输入长度也会影响其推理能力。
-
过度思考现象(Overthinking Phenomenon):研究表明,随着推理链长度的增加,模型性能会先上升后下降。这表明,推理链长度与逻辑复杂性之间存在一个最优平衡点。当推理链超出模型的推理边界时,会导致性能下降,甚至可能出现“幻觉”或错误累积。
-
推理测试时扩展(Inference Test-Time Scaling Phenomenon):研究探讨了推理测试时扩展算法,包括垂直扩展(增加推理路径长度)和平行扩展(增加推理尝试次数)。虽然这些方法可以在一定程度上提高性能,但超出模型推理边界后,性能提升会受限。
-
ORM与PRM现象:研究分析了结果奖励模型(Outcome Reward Model, ORM)和过程奖励模型(Process Reward Model, PRM)在推理中的应用。ORM在数学和逻辑任务中表现出色,但PRM在某些情况下可能更有效。此外,研究还探讨了ORM和PRM之间的关系,以及如何通过奖励模型优化推理过程。
-
“顿悟时刻”(Aha Moment Phenomenon):部分研究表明,通过强化学习训练的模型可能会出现“顿悟时刻”,即模型能够自然地进行自我反思和改进。然而,也有研究指出,在某些情况下,模型可能无法实现真正的自我反思,而是表现出表面的自我反思行为。
2.2 Long CoT的内部机制分析(Internal Mechanism Analysis)
-
注意力机制(Attention Mechanism):研究发现,Long CoT的生成与模型的注意力机制密切相关。例如,System 2 Attention(S2A)能够通过选择性关注相关信息来生成Long CoT。此外,研究还探讨了模型内部梯度分布对推理稳定性的影响。
-
知识整合机制(Knowledge Incorporation Mechanism):研究分析了如何将领域特定的知识整合到Long CoT中。例如,通过概率混合模型(Probabilistic Mixture Model, PMM)可以将模型输出分类为推理、记忆和猜测,并通过信息论一致性(Information-Theoretic Consistency, ITC)分析来量化模型置信度与策略选择之间的关系。
-
推理深度与知识深度(Concept Depth):研究探讨了模型在推理过程中对复杂概念的理解深度,发现不同模型在不同层次上整合知识的能力存在差异。此外,研究还通过知识循环演化分析了模型知识的内化过程。
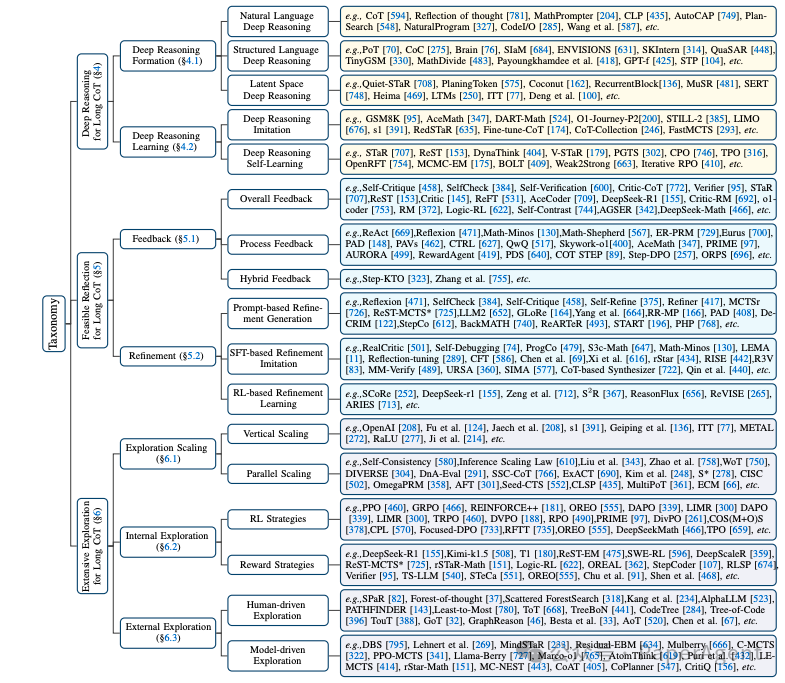
3.1 深度推理分类
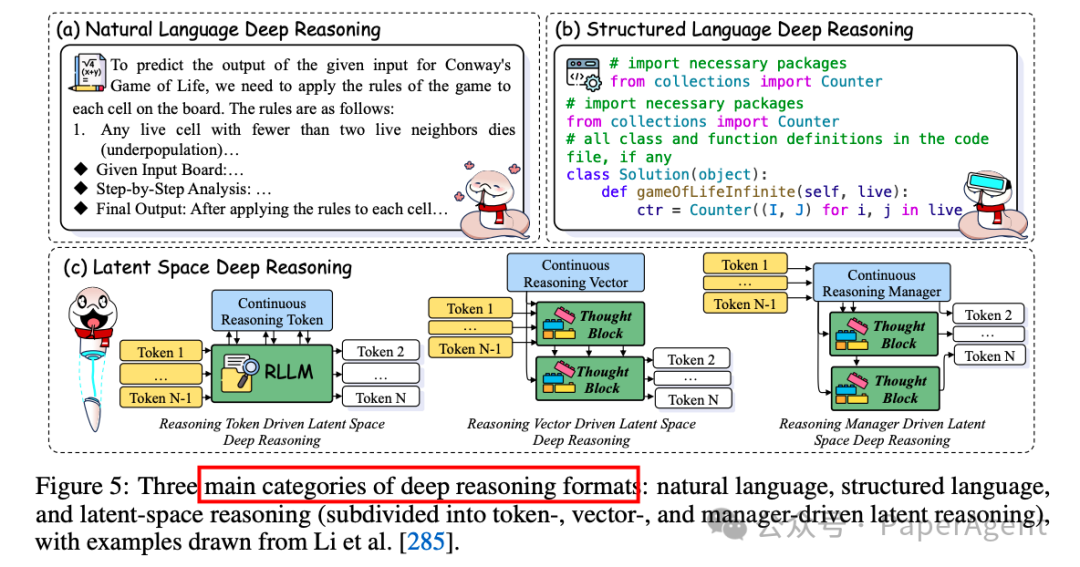
-
自然语言深度推理(Natural Language Deep Reasoning):早期研究者如Wei et al. [594] 发现,使用自然语言的长链推理(CoT)显著增强了RLLMs的推理能力。CodeI/O [285] 进一步将代码推理模式重组为自然语言格式,提升了模型的推理潜力。
-
结构化语言深度推理(Structured Language Deep Reasoning):包括程序语言或符号语言推理,如PoT [70] 和Brain [76] 等,通过环境引导的神经符号自训练框架,解决了符号数据稀缺和符号处理限制的问题。
-
潜在空间深度推理(Latent Space Deep Reasoning):将推理过程嵌入到连续的潜在空间中,分为基于推理令牌(Token-driven)、向量(Vector-driven)和管理器(Manager-driven)的推理方式。例如,Coconut [162] 通过维护多个推理路径,提高了推理效率。
3.2 深度推理学习
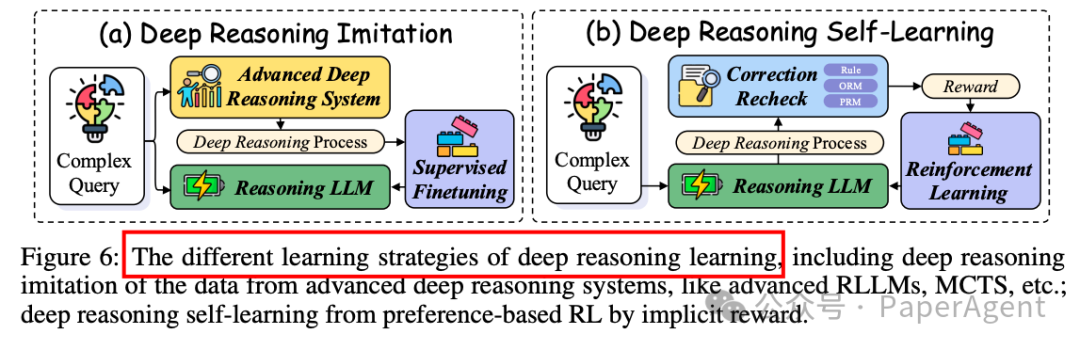
-
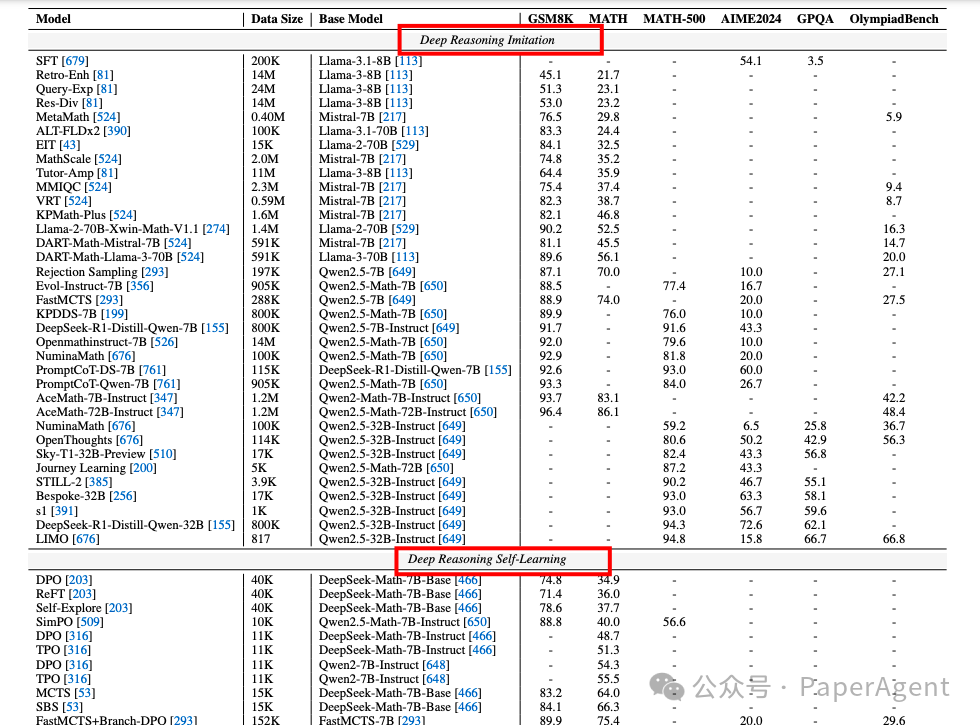
深度推理模仿(Deep Reasoning Imitation):通过模仿高级推理系统(如人类推理、先进RLLMs或通过扩展训练的RLLMs)来学习推理能力。例如,AceMath [347] 使用少量样本通过多阶段质量引导的微调来增强性能。
-
深度推理自学习(Deep Reasoning Self-Learning):通过偏好强化学习(RL)实现自学习,以增强推理能力。例如,STaR [707] 使用蒙特卡洛树搜索(MCTS)引导的自训练,通过奖励机制优化推理路径。
https://arxiv.org/pdf/2503.09567Towards Reasoning Era: A Survey of Long Chain-of-Thought for Reasoning Large Language Modelshttps://long-cot.github.io/
(文:PaperAgent)