北京时间3月19日凌晨,英伟达年度GTC大会在美国圣何塞揭幕,CEO黄仁勋身穿标志性黑色皮衣再次登台,进行了两个多小时激情解说。
从全新旗舰芯片架构、数据中心超算到AI智能体软件、物理AI、机器人、自动驾驶等,再次描绘和展望了英伟达的超级AI版图。
老黄表示,今年GTC大会就如同“AI界的超级碗”,每个人都是胜利者,因为在英伟达的算力和开发工具加持下,AI能为更多行业和公司解决问题。
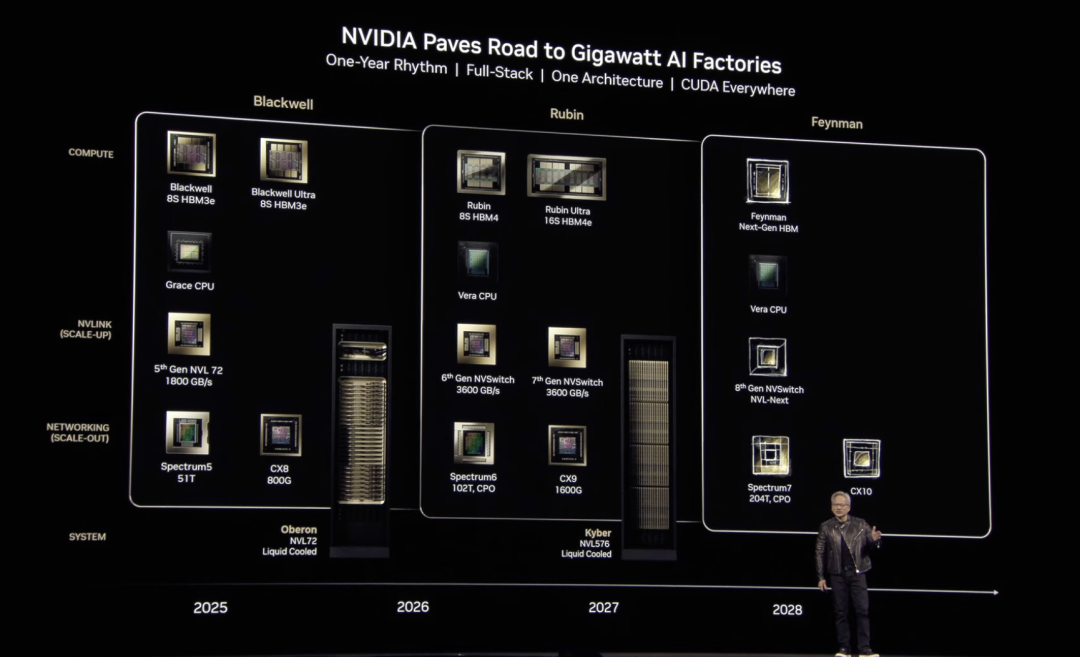
大家最关心的GPU产品,黄仁勋表示升级版的Blackwell Ultra在2025 年下半年就能上市。
而且英伟达未来三代全新GPU架构都在开发中,命名为Rubin、Rubin Ultra、Feynman,Rubin架构性能可达到Hopper的900倍以上,关键性能比最新发布的Blackwell Ultra还要再翻两倍以上,继续独霸全球顶尖AI算力市场。
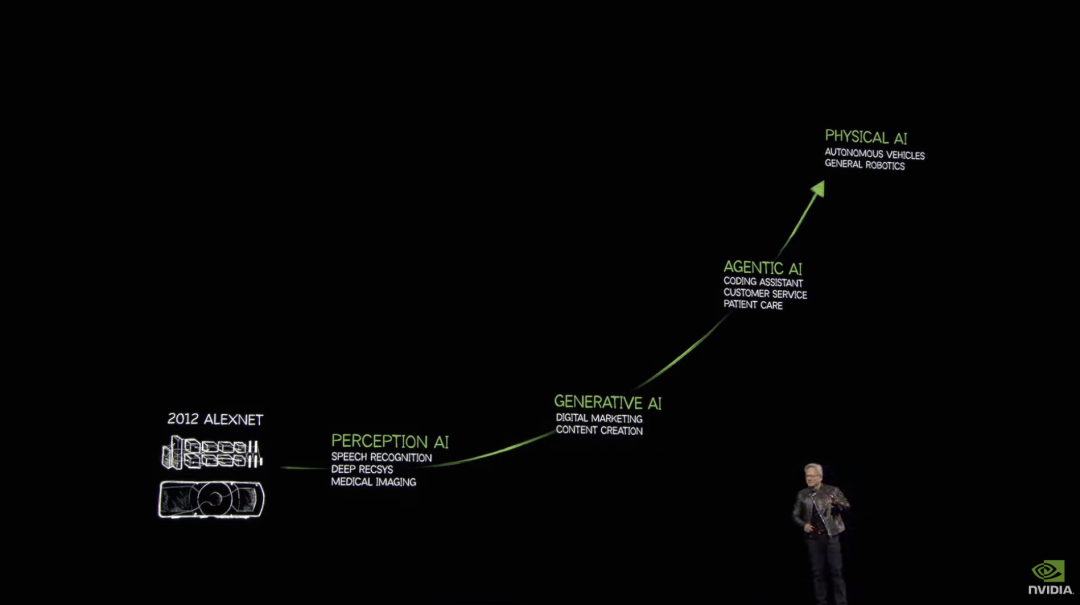
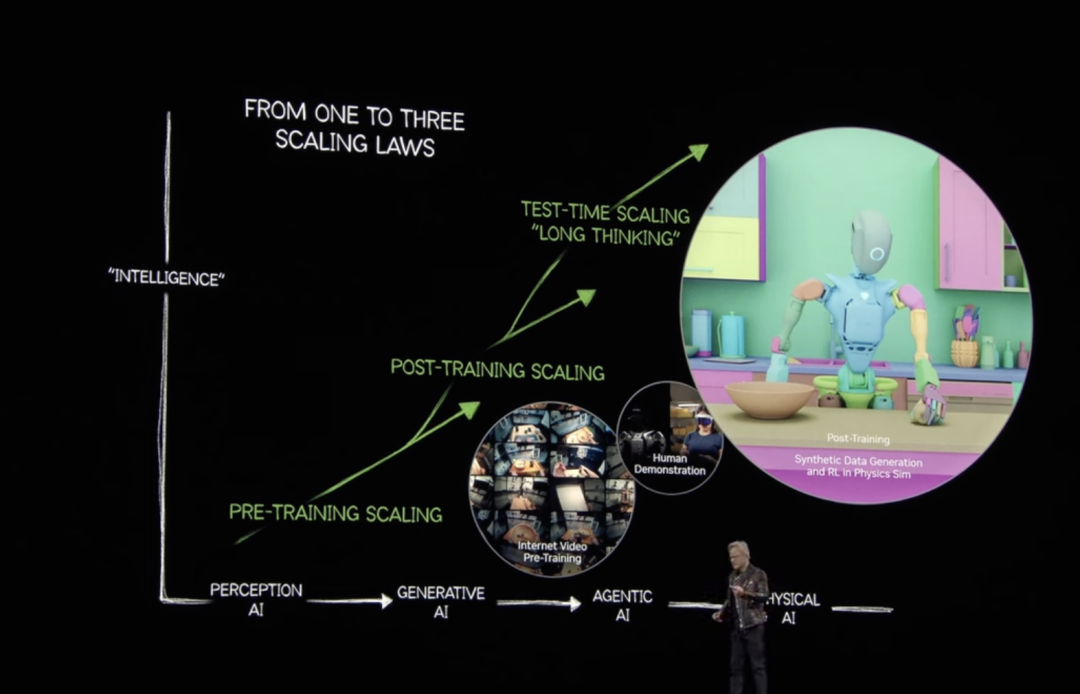
老黄开场再次展示了自己对AI技术发展趋势的预判,技术将经历感知AI-生成式AI-AI代理-物理人工智能,因此超强的AI算力那是少不了的。
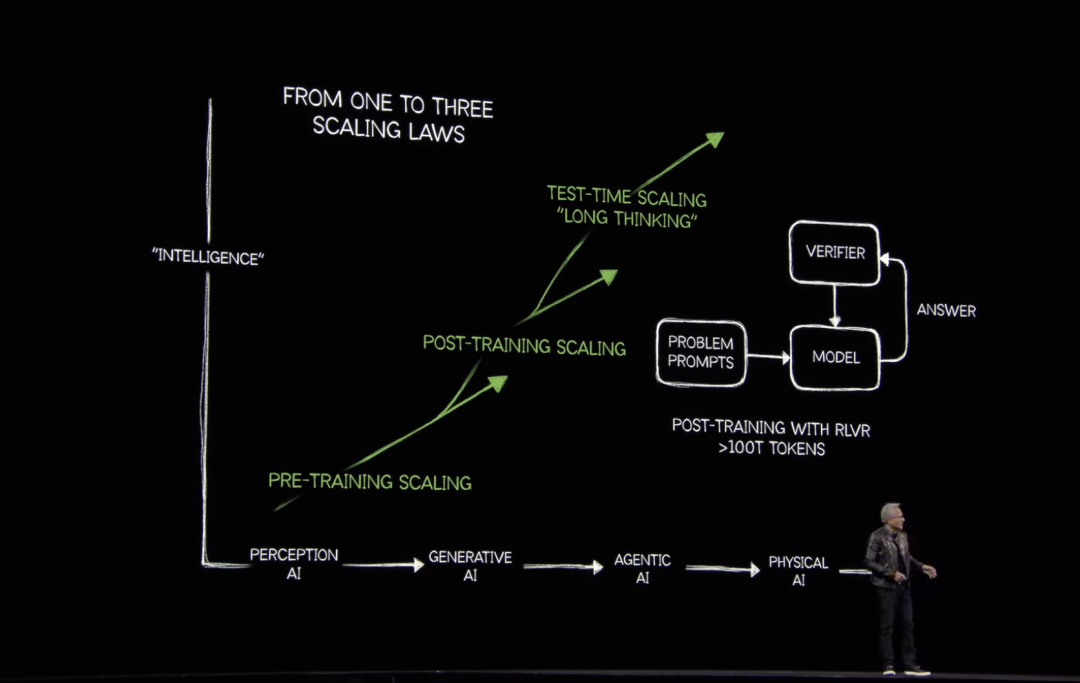
尽管今年DeepSeek模型展现出对算力的需求没那么顶尖也可以,但广泛应用后却激发了AI推理需求,同时业内头部AI公司也在追求更大规模的模型训练,Scaling Law并未失效,无论怎么看对算力的需求都是越来越高、越来越强。
老黄透露,全球前四大云服务商去年采购了超130万片Hopper架构GPU,今年或将增至360万片Blackwell架构GPU,数据中心投资将上万亿美元规模。
升级版Blackwell Ultra GPU架构更擅长满足AI推理需求。
该架构增强了训练和测试时间扩展推理(在推理过程中应用更多计算以提高准确性的艺术),使开发者能够加速AI推理、代理AI和物理AI等应用。
Blackwell Ultra以一年前推出的Blackwell架构为基础,包括NVIDIA GB300 NVL72机架级解决方案和NVIDIA HGX B300 NVL16系统。GB300 NVL72的AI性能比NVIDIA GB200 NVL72高出1.5倍,与使用NVIDIA Hopper构建的相比,Blackwell性能增加了50倍。
与Hopper一代相比,NVIDIA HGX B300 NVL16在大型语言模型上的推理速度提高了11倍,计算能力提高了7倍,内存增加了4倍。
基于Blackwell Ultra的产品将从2025年下半年开始提供。预计思科、戴尔科技、惠普、联想和超微等将提供基于Blackwell Ultra产品的各种服务器。
NVIDIA Dynamo开源推理框架今天也宣布扩展了推理AI服务,通过提供最有效的测试时间计算扩展解决方案,实现了吞吐量的飞跃,同时缩短响应时间和模型服务成本。
英伟达预计将于2026年下半年开始发售其下一代GPU产品,以天文学家Vera Rubin的名字命名,将比去年的Grace Blackwell芯片中使用的CPU快两倍。
Rubin可以在进行推理时实现每秒50千万亿次浮点运算,比该公司目前的Blackwell芯片每秒20千万亿次浮点运算的速度高出一倍多,Rubin还可以支持高达288 GB的快速内存,这是AI开发人员关注的核心规格之一。
以物理学家理查德·费曼命名的Feynman架构,预计会在2028年问世,目前并未有太多细节。
除了GPU架构展望,今年GTC推出的核心组件产品瞄准了数据中心AI超算和个人AI超算,以及基于英伟达硬件的一系列AI推理、AI智能体软件支撑。
黄仁勋介绍了目前全球最先进的企业级AI基础设施—搭载NVIDIA Blackwell Ultra GPU的NVIDIA DGX SuperPOD™,旨在为各行各业的企业提供AI超级计算,实现最先进的代理AI推理,该超级计算机可提供FP4精度和更快的AI推理能力,从而为AI应用程序增强令牌生成能力。
其中的DGX GB300系统可提供比使用NVIDIA Hopper™系统和38TB快速内存构建的AI工厂高达70倍的AI性能,为代理AI和推理应用程序上的多步推理提供无与伦比的大规模性能。
每个DGX GB300系统中的72个Grace Blackwell Ultra GPU通过第五代NVLink技术连接,可提供高达800Gb/s的加速网络速度,与Hopper一代相比,DGX B300系统可提供11倍的AI推理性能和4倍的训练速度。
英伟达也展示了把AI部署到每个开发者身边的野心,实现算力从数据中心到桌面端的延伸,推出AI超级算力台式机:DGX Spark和DGX Station。
这是搭载NVIDIA Grace Blackwell平台的桌面超级计算机,也号称是世界上最小的AI超级计算机,可以让AI开发人员、研究人员、数据科学家和学生能够在桌面上对大型模型进行原型设计、微调和推理,用户可以在本地运行这些模型,也可以将其部署在NVIDIA DGX Cloud或任何其他加速云或数据中心基础设施上。
DGX Spark的核心是NVIDIA GB10 Grace Blackwell芯片,配备第五代 Tensor Core和FP4支持,每秒可进行高达1000万亿次AI计算。
DGX Station则为桌面带来接近数据中心级性能,核心使用了NVIDIA GB300 Grace Blackwell Ultra最新芯片,具有784GB连贯内存空间,支持高达800Gb/s网络传输,以处理比DGX Spark更大的工作负载。
硬件之外,值得关注的是,英伟达今天还推出了NVIDIA Dynamo,这是一款开源推理软件,用于以最低的成本和最高的效率加速和扩展AI推理模型。
NVIDIA Dynamo是NVIDIA Triton Inference Server™的后继产品,它能协调和加速数千个GPU之间的推理通信,并使用分解服务将大型语言模型 (LLM) 的处理和生成阶段分离在不同GPU上,确保最大程度地利用GPU资源。
黄仁勋介绍,在GB200 NVL72机架的大型集群上运行DeepSeek-R1模型时,NVIDIA Dynamo的智能推理优化将每个GPU生成的token数量提高了30倍以上。其中包含了四个创新点:
GPU规划器:一种规划引擎,可动态添加和删除GPU,以适应不断变化的用户需求,避免GPU过度或不足;
智能路由器:LLM感知路由器,可在大型 GPU 队列之间引导请求,以最大限度地减少重复或重叠请求的昂贵GPU重新计算-释放GPU以响应新的传入请求;
低延迟通信库:一个推理优化的库,支持最先进的 GPU 到 GPU 通信,并抽象跨异构设备的数据交换的复杂性,从而加速数据传输;
内存管理器:一种引擎,可在不影响用户体验的情况下,智能地从低成本内存和存储设备卸载和重新加载推理数据。
除了AI还有一些关于设计市场的新品推出。NVIDIA RTX PRO™ Blackwell系列工作站和服务器GPU,不仅能用于加速计算、AI 推理,在光线追踪和神经渲染技术方面也跟AI融汇贯通,支持技术开发、创意、工程和设计专业人士的工作流程。
以及使用硅光子的百亿亿次级数据中心的Spectrum-X Photonics和Quantum-X Photonics网络交换机平台,新的网络交换机平台将数据传输速度提高到每端口1.6 Tb/s,总计400 Tb/s,使数百万个GPU能够无缝协作。
最后,黄仁勋还宣布了NVIDIA加速量子研究中心(NVAQC),以及支持量子计算研究的NVIDIA GB200 NVL72系统和NVIDIA Quantum-2 InfiniBand网络平台,英伟达将于当地时间3月20日举办首个“量子日”活动,探索量子计算应用之路。
可以说,只要在地球上涉及AI计算和研究,英伟达算力已经无孔不入进行了全栈布局渗透。
在GTC现场,英伟达与谷歌DeepMind、迪士尼研究中心合作开发的机器人星战机器人BDX成为全场最靓的仔,背后的技术支撑是三方合作开发的开源物理引擎Newton,用于模拟现实环境中的机器人运动。
在机器人领域,模拟往往与现实不符,这一问题被称为“模拟与现实”差距,机器人开发人员需要一个统一、可扩展且可定制的解决方案来模拟现实世界的物理现象。
Newton基于NVIDIA Warp构建,这是一个NVIDIA CUDA-X加速库,可帮助机器人学习如何更精确地处理复杂任务,同时还兼容MuJoCo Playground或NVIDIA Isaac Lab等学习框架(另一种用于机器人学习的开源统一框架),聚焦为娱乐型机器人提供动力。
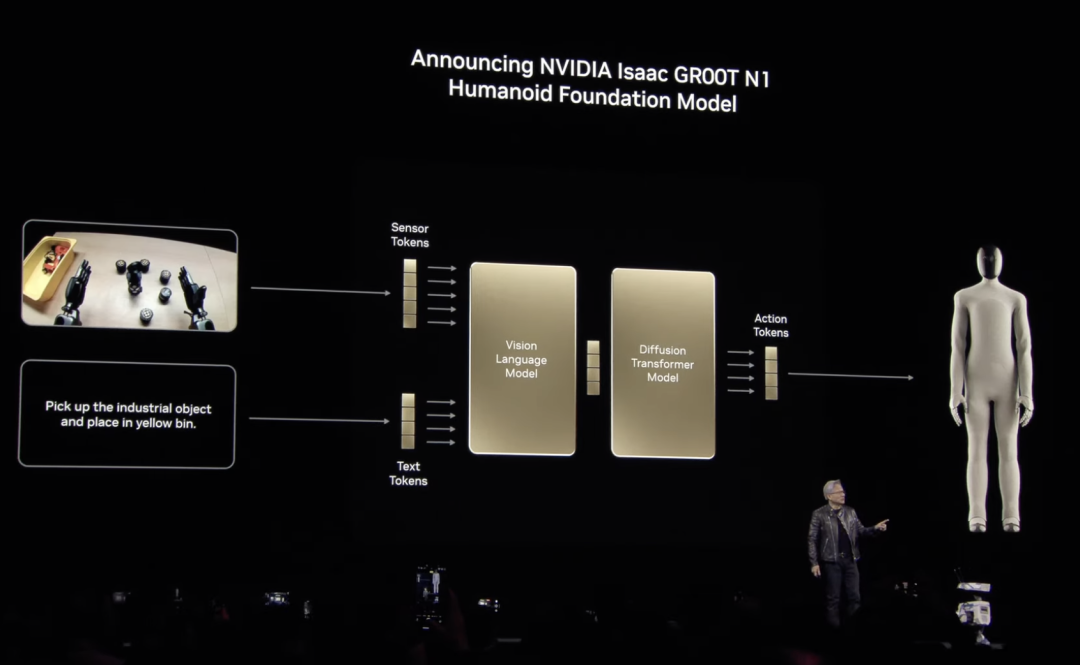
此外,英伟达还宣布了一系列用于增强人形机器人开发的技术,其中包括NVIDIA Isaac GR00T N1,这是世界上第一个开放、完全可定制的通用人形推理和技能基础模型。
GR00T N1可以轻松实现常见任务(例如抓取、用一只或两只手臂移动物体以及将物品从一只手臂转移到另一只手臂),或者执行需要长时间上下文和一般技能组合的多步骤任务,这些功能可应用于物料搬运、包装和检查等用例。
最后是关于机器热的全新Omniverse蓝图,该蓝图基于Omniverse和NVIDIA Cosmos Transfer世界基础模型构建,可让开发人员通过少量人类演示生成指数级的大量合成动作数据,用于操作任务。
利用蓝图可用的第一批组件,NVIDIA在短短11小时内生成了780000条合成轨迹,相当于6500小时或连续9个月的人类演示数据。
老黄表示:“通用机器人时代已经到来。借助NVIDIA Isaac GR00T N1以及新的数据生成和机器人学习框架,世界各地的机器人开发人员将开拓AI时代的下一个前沿。每个人都应该关注机器人领域,它很可能会成为最大的产业。”
总之一句话,不管AI产业和机器人行业如何飞速变化,现在稳坐算力王座的英伟达要赢麻了。
(文:头部科技)