


为了使得通用的预训练大模型能够满足专业领域的需求,我们往往会对通用的大模型进行微调。实际上通过微调框架或技术对大模型进行微调之后可能会发现,微调之后的模型其实并没有达到预定的效果。当然这个原因是多方面的,有时候取决于微调的数据集,微调时对模型进行的一些列优化处理等等,但是另外一个不容忽视的问题则是需要在微调之前向预训练 LLM 的分词器增加一些专业领域的 token,以帮助 LLM 在微调过程中提高对数据集的理解能力。
本文的主要目的是介绍往 LLM 分词器中新增 token 的原因和基本方法,同时也会介绍在云原生的场景下如何将该操作集成到 LLM 微调的流程当中。
在对预训练 LLM 进行微调之前,通常会在预训练 LLM 分词器中添加额外的新 token。这样做有以下几个目的:
1. 引入领域特定词汇
如果需要在特定领域(例如医学、法律、金融)进行微调,则需要引入一些基础模型无法识别的新术语、缩写或技术术语。添加新 token 有助于模型更好地理解和生成与该领域相关的文本。
2. 处理词汇表之外的单词
预训练 LLM 使用分词算法(如 BPE 或 WordPiece),然而有些词可能会被分解为低效的子词。因此添加额外的标记可以提高文本生成的效率和准确性。例如,`ChatGPT` 可能会拆分为 Chat 和 GPT,从而导致语义碎片化。
3. 适应多语言扩展
如果针对原始训练数据中没有很好覆盖的新语言进行微调,则为唯一的单词或字符添加额外的标记可以提高 LLM 的微调性能。
4. 引入自定义格式标记、指令调整和提示词工程
如果需要在微调数据中引入特定结构(例如,markdown 格式、XML 标签或对话角色的占位符),新 token 可以帮助预训练 LLM 更有效地学习所需的结构。除此之外,一些预训练 LLM 使用特殊标记(如
综上所述,添加额外的 token 有助于预训练的 LLM 在微调过程中更有效地适应特定领域的要求,从而减少对大量训练数据的需求。这也是平衡微调效果和计算成本的关键技术。
基本上,通过 transformers 包实现额外 token 的添加有如下 4 个步骤:
1. 修改分词器
a) 加载分词器 (例如从 Hugging Face’s transformers 库中加载);
b) 添加新的 token 到分词器的词汇表中;
有关向分词器添加新 token 的更多详细信息,请参阅 new_tokens 和 special_tokens;
c) 调整模型中嵌入层的大小以适应新的 token。
需要调用 resize_token_embeddings 来调整模型的嵌入矩阵的大小以匹配其分词器。此外,请参阅此处了解更多详细信息。
2. 在模型的嵌入层中正确初始化新 token 的嵌入权重
新的 token 被添加到分词器中,其索引从当前词汇表的长度开始,并且在应用分词算法之前将被隔离,因此这些新的 token 和来自分词算法词汇表的 token 不会以相同的方式处理。除此以外,默认情况下,模型嵌入层中新 token 的嵌入权重是随机初始化的,这可能会导致最初的训练不稳定或性能不佳。因此,一般在每加入一个新的 token 之前,事先计算当前模型嵌入层中所有 token 的平均嵌入权重(average embedding weight),以此作为当前新加入 token 的嵌入权重。
3. 保存并重新加载更新后的分词器和模型
添加新 token 后,保存更新的分词器和模型以供将来使用。当然,后面需要加载分词器和模型的时候需要与保存时候的路径相对应地加载。
4. 使用添加的 token 对预训练 LLM 进行微调
如果新 token 代表专业领域的概念,则在相关数据集上微调模型至关重要。使用包含这些新 token 实例的数据集并训练模型以正确理解其用法。
根据以上描述,我完成在 GitHub 完成了一个示例程序 AddExtraTokens2LLM。读者克隆该例子后可直接在您的设备上启动运行,欢迎尝试并提出宝贵意见。
无论我们选择何总微调技术或者框架,预训练 LLM 微调的流程大致如下图所示。红色虚线框的内容包含的就是特定领域的 token 表,我们均需要在正式微调模型前将其加入到模型的分词器词库和模型的 embedding 层中,并且该操作应该在微调模型加载前,更靠前于导入 LLM 微调的数据集。
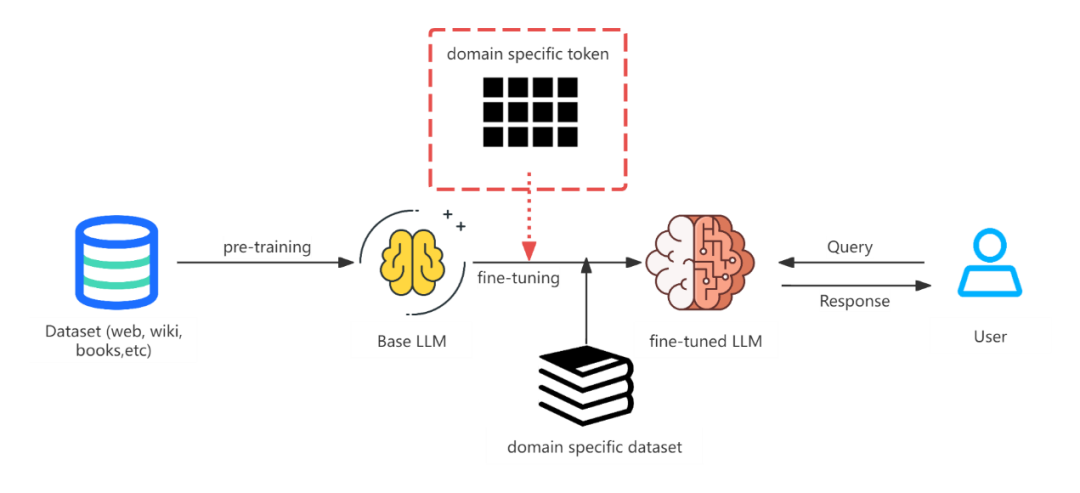
结合云原生的场景下,在预训练 LLM 微调前该如何为其模型添加新的 token?对于这个问题其答案取决于多个方面的考量,比如用什么技术框架对模型进行微调,微调的集群是单集群还是多集群等。笔者综合遇到的大部分场景,将这此集成过程抽象成如下三种情况:Pod Level 的模型微调,Node Level 的模型微调和 Cluster Level 的模型微调。
对于 Pod Level 的模型微调,这是所有情况中最简单的场景,一般情况下其微调的时间不会太长,技术也不会太复杂。笔者对此的解决方案是可以将微调的任务放到 Pod 的常规 containers 中去实现,然后将添加新的 token 的任务放入 Pod 的 Init Containers 中。熟悉 Kubernetes Init Containers 机制的读者应该明白,Init Containers 可以保证其任务在所有常规的 containers 启动之前完成。
对于 Node Level 的模型微调,这种场景通常情况下会涉及各种分布式微调框架技术的使用,比如基于 Ray 的大语言模型微调。除此以外,Node Level 也可以出现多集群微调的场景,为了简单起见,笔者只考虑单集群的 Node Level 的模型微调。而对此的解决方案基本上会定义微调模型的流程,此目的自然是为了实现对微调过程的控制干预。对于使用 Ray 等框架来说可能相对比较简单,因为用户只需要将给模型添加 token 的工作封装成 Ray script (Driver),然后再微调之前通过 Ray Job API 事先提交一个 Ray Job 即可。如果想要做得更通用灵活,笔者的建议则是为模型的微调实现一个 Kubernetes Operator,通过定义 Kubernetes CRD 来实现模型微调流程的扭转。这些流程节点笔者总结如下:1. 从模型下载。2. 为模型添加新 token 并保存模型。3. 重新加载处理后的模型。4. 导入微调数据集(可能包含微调数据集的处理,可以添加子流程)。5. 模型微调(需要包含调度,自动扩缩容和断点续训等处理机制)。6. 微调后模型保存。
对于 Cluster Level 的模型微调,这种场景基本上属于很大规模的模型微调,需要多集群的协作是不可避免的,因此多集群的解决方案是必不可少的。事实上笔者到目前为止并没有遇到这种场景,所以也只能提出一些理论的解决方案。首先需要选择合适的多集群解决方案方。其次要实现多集群 Task Discovery(任务发现)的能力。此能力应该是实现各种关键任务的基础,包括本文主要提及的为模型添加 token 的任务。最后,需要把各种任务及其输出串联起来,形成完整的流程拓扑。鉴于笔者没有实践过,因此不再赘述。
虽然写本文的主要目的是为了介绍“如何为预训练 LLM 添加新 token?”,但是笔者抛砖引玉,也相信读者能从这一隅之地出发,为基于云原生场景下,解决大语言模型服务推理部署,微调,训练等场景提出更加通用优秀的解决方案,为业界分享更多的实践经验。
关于作者
张怀龙,曾就职于阿尔卡特朗讯、百度、IBM、英特尔等知名公司担任高级开发职位,拥有 16 年的技术研发经验。作为 Istio 社区的维护者,他专注于云原生微服务,并在云原生与 LLM 技术的交叉领域进行创新。他为 OpenVINO、Kserve 等社区做出贡献,致力于云原生场景下的 LLM 推理,是 OPEA(企业 AI 开放平台)社区的开发者和维护者。作者还曾在 KubeCon、ServiceMeshCon、IstioCon、GOTC、InfoQ/Qcon 和 GOSIM 等会议上发表演讲。
(文:AI前线)