

Reliable-RAG 方法在传统的 RAG 方法上进行了改进:通过增加验证和优化步骤,确保了检索信息的准确性和相关性。该系统旨在处理和查询基于网络的文档,将其内容编码到向量存储中,并检索最相关的片段,以生成精准且可靠的答案。该方法包含文档相关性检查、幻觉预防机制,并突出显示用于生成最终答案的具体片段。在法律、学术研究等对事实准确性和透明度要求极高的领域尤为适用。
总的来说,Reliable-RAG 通过以下方法确保生成的答案既准确又可靠。
-
文档相关性过滤:通过语言模型生成的二元相关性评分,仅将最相关的文档传递至答案生成阶段,从而减少噪声并提升最终答案的质量。
-
幻觉检查:在最终确定答案之前,系统会对生成内容进行验证,确保其完全基于检索到的文档支持,从而防止幻觉信息的产生。
-
片段高亮:该功能增强了透明度,通过显示检索文档中用于生成最终答案的具体片段,使答案来源清晰可追溯。
但是 Reliable-RAG 系统的性能依赖于嵌入模型的质量以及幻觉检测机制的有效性。可以采用更先进的相关性检查和幻觉检测模型,可以进一步提升系统的可靠性。
实现步骤
-
文档加载与切分。加载基于网络的文档,并将其拆分为较小且易管理的片段,以便高效进行向量编码和检索。
-
创建向量存储。使用 Qdran 和 bge-m3 嵌入对文档片段进行编码,并存入向量存储,以支持基于相似度的高效检索。
-
文档相关性检查。采用 LLM 进行相关性检查,在生成答案前过滤掉无关的文档。
-
生成答案。利用 LLM 基于检索到的相关文档生成简明准确的答案。
-
幻觉检测。设置专门的幻觉检测步骤,确保生成的答案基于检索到的文档,从而避免包含不支持或错误的信息。
-
文档片段高亮。识别并高亮显示直接用于生成答案的文档片段,提高透明度和可追溯性。
1. 文档加载与切分
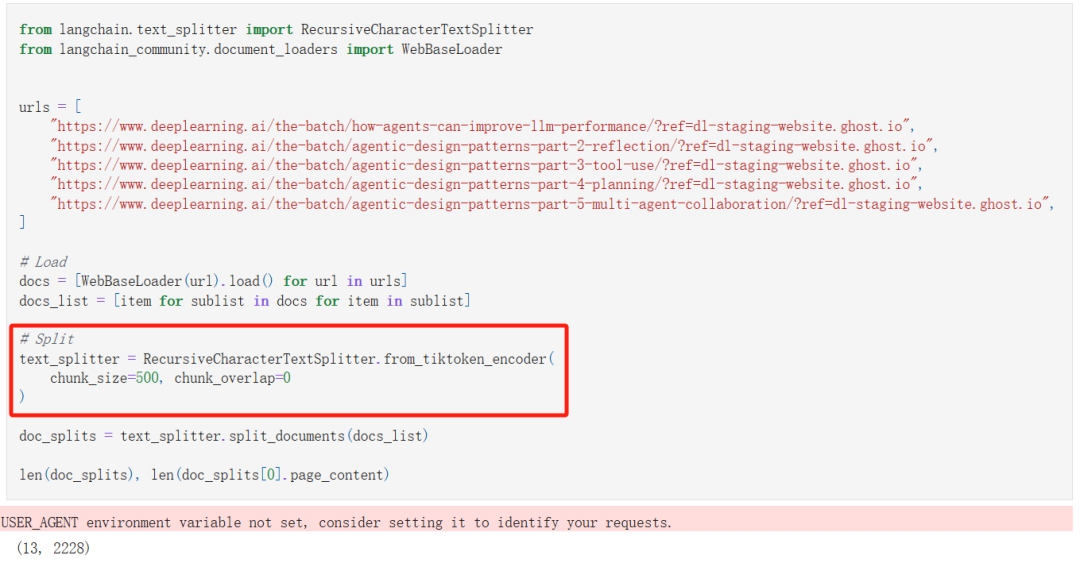
首先,我直接从网页上加载了网页内容。
其次,在这里我没有选择之前一直按照字符长度切分的普通切分方法,我使用了基于 tiktoken encoder(编码器)的拆分方法(即按 token 数量进行切分),这个方法具有以下优势:
-
与模型输入对齐
LLM 处理的是 token 而非单纯的字符。基于 token 的切分确保每个文本块的大小符合模型的上下文窗口限制,避免因字符计数与 token 数量不匹配而导致超出限制或浪费上下文空间。 -
避免破坏 token 结构
普通的字符切分可能会在 token 边界中间截断,导致生成的文本块包含不完整的 token,从而影响后续的语义理解和生成。使用 tiktoken encoder 则可以确保拆分后的文本块都由完整的 token 组成,保持语言的一致性和完整性。 -
更适合多语言场景
对于包含多字节字符(如中文、日文等)的语言,单纯按照字符数切分可能无法正确反映实际的 token 数量。而基于 tiktoken 的拆分能够更精确地处理这些情况,确保每个文本块符合预期的 token 数量。
总的来说,这种方法更贴近语言模型的实际处理方式,可以提高模型生成的准确性和可靠性。
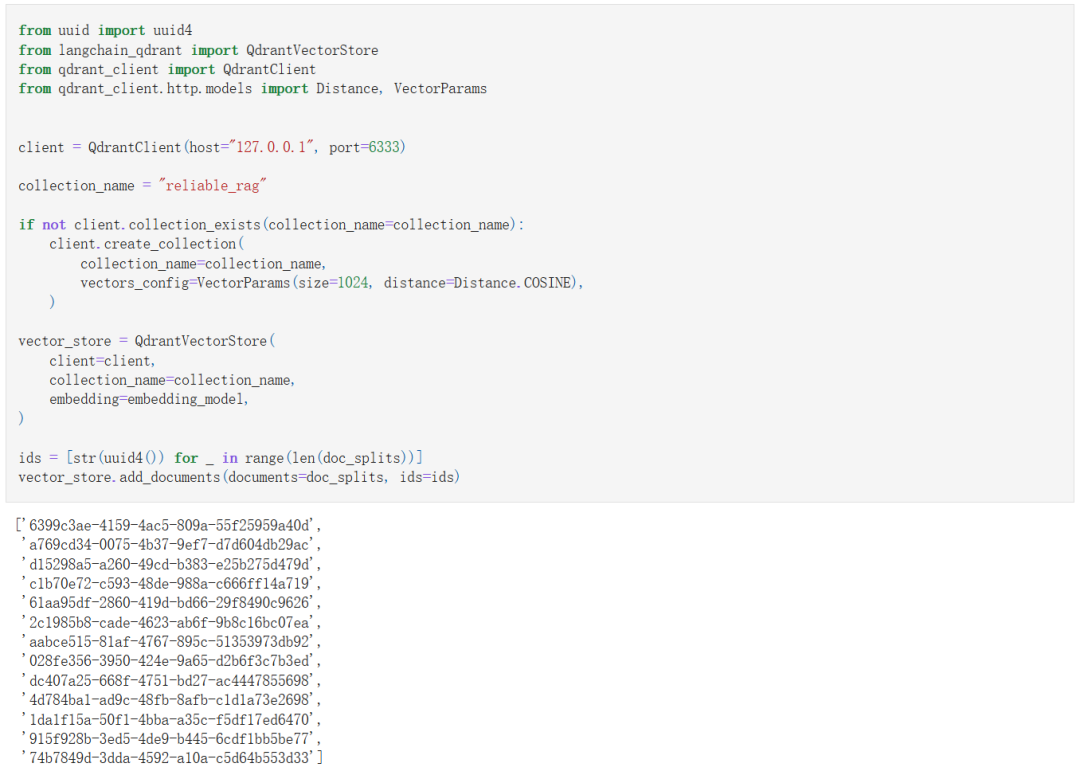
2. 创建向量存储
3. 文档相关性检查
首先,我们初始化一个检索器并验证:
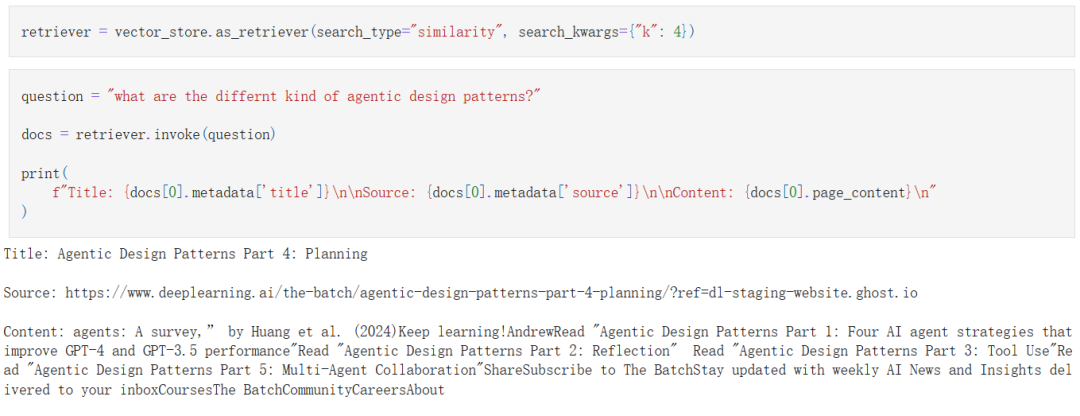
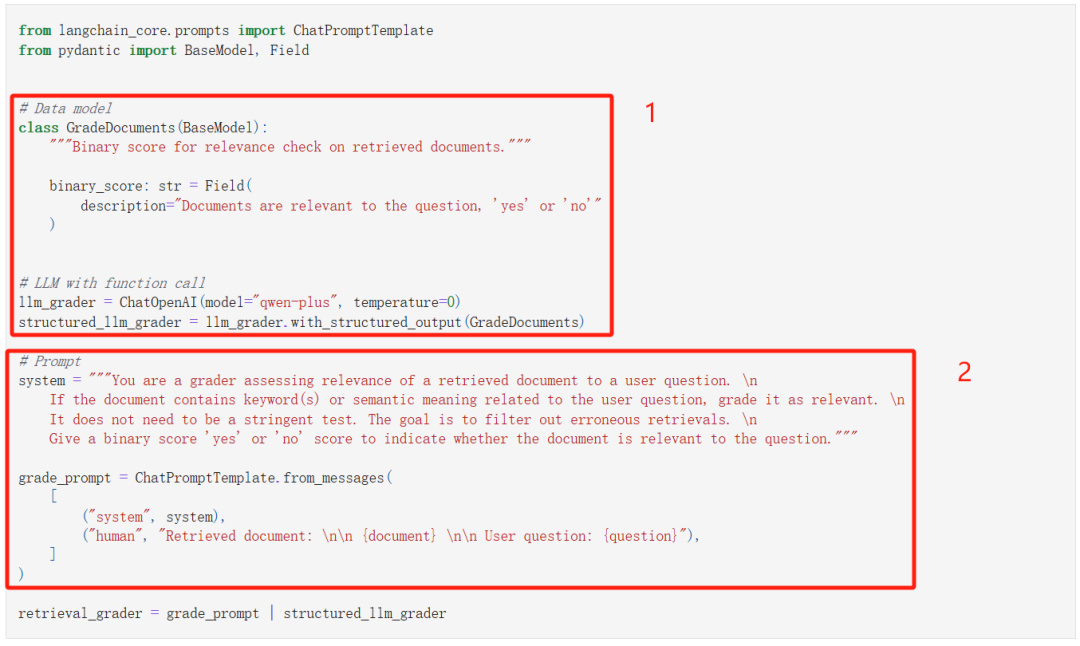
接下来使用 LLM 检查检索到的文档和问题的相关性:
-
让 LLM 按照我们指定的 JSON 格式输出;
-
通过提示工程让 LLM 检查相关性。
接下来仅将相关的(binary_score == “yes”)的文档挑选出来。

我们这里检测到的 4 篇文档都是相关的。
4. 生成答案
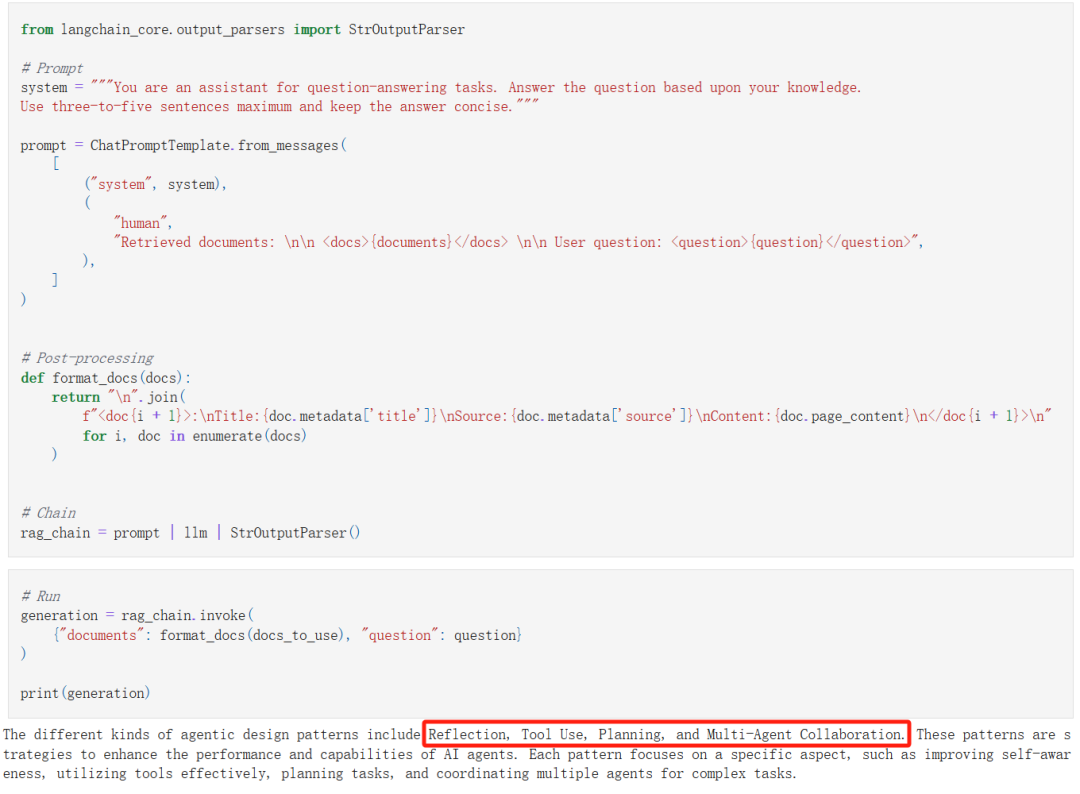
问题是:
what are the differnt kind of agentic design patterns?
(有哪些不同类型的智能体设计模式?)
RAG 系统给出的答案是:
-
Reflection(反思)
-
Tool Use(使用工具)
-
Planning(规划)
-
Multi-Agent Collaboration(多智能体协作)
那么这些答案靠谱吗?
5. 幻觉检测
我们首先检测一下答案是不是从检索到的文档中获取的。
和前面检测文档相关性一样,我们也是:
-
让 LLM 以 JSON 格式输出结果;
-
通过提示工程完成幻觉检测。
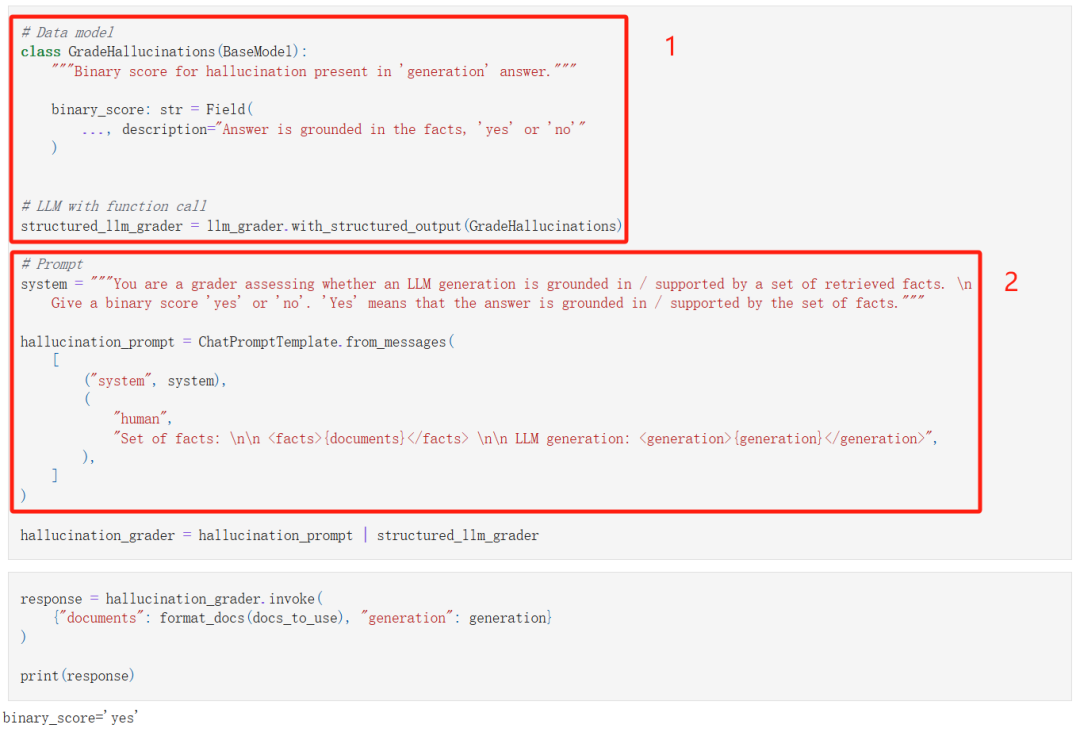
最终的结果是答案是基于检索到的文档生成的。
那么答案具体是从检索到的文档中的哪些段落生成的呢?
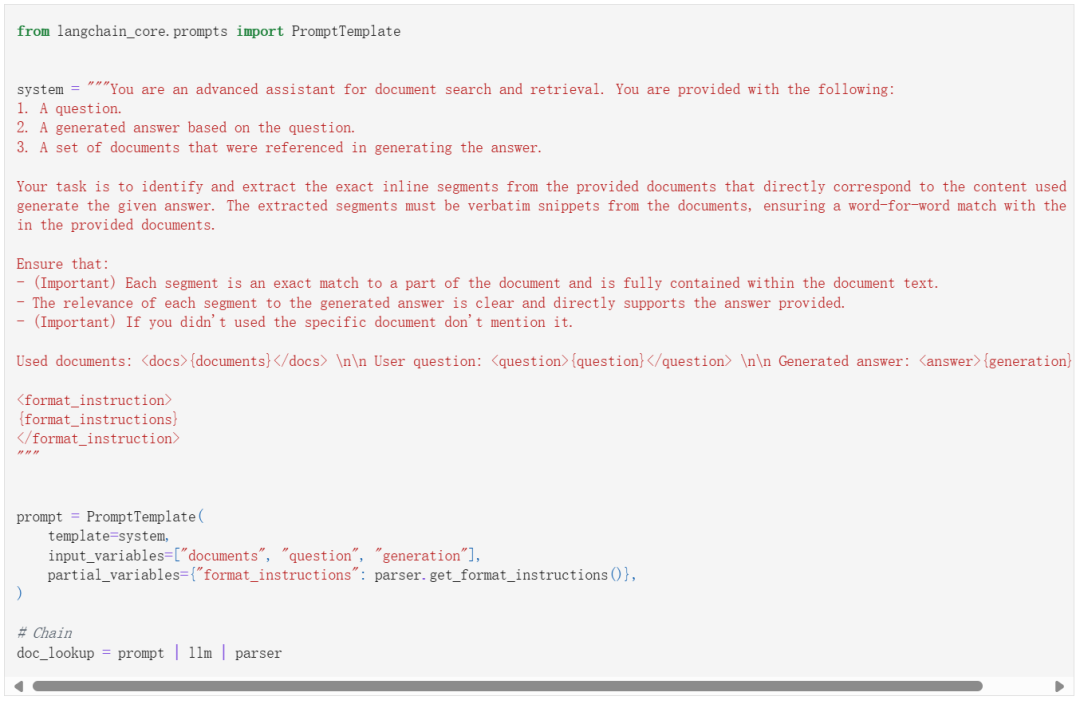
6. 文档片段高亮
我们还是首先让 LLM 按照指定的结构输出结果:

-
id:我们自定义的文档 ID;
-
title:文档标题
-
source:文档来源,这里就是 5 个网页地址;
-
segment:文档片段。
接下来到了重头戏,还是依赖于提示工程让 LLM 根据答案从文档中找到具体的答案来源:
看一下结果:
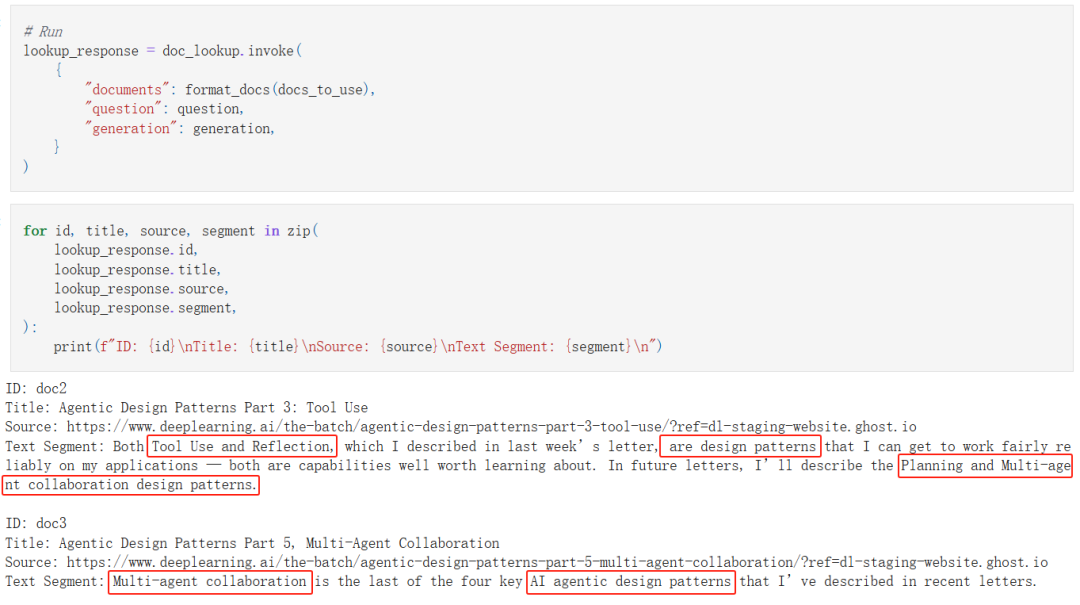
结果相当具有说服力。
本文源码:
https://github.com/realyinchen/RAG/blob/main/RAG101/003-Reliable_RAG.ipynb
查阅此前文章:
《RAG101第二课:一个简单的CSV文件RAG工作流》
《RAG101第一课:一个简单的RAG工作流》
文章来源:PyTorch研习社
(文:PyTorch研习社)