


近期,随着大型自回归模型在自然语言处理、图像生成和语音合成等领域的广泛应用,实时性和效率问题逐渐成为制约其发展的关键瓶颈。
在这一背景下,如何在保持高质量输出的同时,显著提升模型的推理速度,以满足实时应用的需求,成为了一个亟待解决的挑战。传统的优化方法,如剪枝和量化,往往会在加速模型的同时牺牲输出质量,因此需要探索一种既能提升速度又能保持质量的高效解码策略。
这一挑战催生了生成-精炼框架(Generation-Refinement Frameworks)的快速发展,其中最具代表性的技术是 Speculative Decoding(SD)。
SD 通过引入草稿模型并行生成 Token,并利用目标模型进行验证,打破了传统自回归模型的序列依赖性,显著降低了推理延迟,同时保持了高质量的输出。这种技术让自回归模型在实时应用中变得更加高效和灵活,不再被“速度枷锁”所束缚。
为了全面总结 Speculative Decoding 及相关技术的发展历程,并及时跟进最新的研究进展,纽约大学、宾夕法尼亚大学、富兰克林·马歇尔学院等机构的研究者们发布了一篇深度综述论文《Speculative Decoding and Beyond: An In-Depth Survey of Techniques》。
全文 8 页,涵盖了近 120 篇最新文献,系统性地分析了生成-精炼框架的算法创新和系统级实现,并探讨了其在文本、图像、语音等多模态领域的应用。

论文地址:
https://arxiv.org/abs/2502.19732

现代语言模型的加速之道:打破顺序依赖
在当今人工智能领域,语言模型(LLMs)的发展日新月异。从 Llama 系列到 GPT 系列,这些强大的模型都基于一种名为 “Transformer” 的架构,由多层解码器模块堆叠而成。每一层解码器都包含两个核心组件:自注意力(Self-Attention,SA)模块和前馈网络(Feed-Forward Network,FFN)。
在模型运行时,输入数据首先通过权重矩阵计算出查询(Query)、键(Key)和值(Value)向量,随后通过矩阵运算和归一化处理,生成加权求和的结果,并通过残差连接传递给前馈网络,最终输出结果。
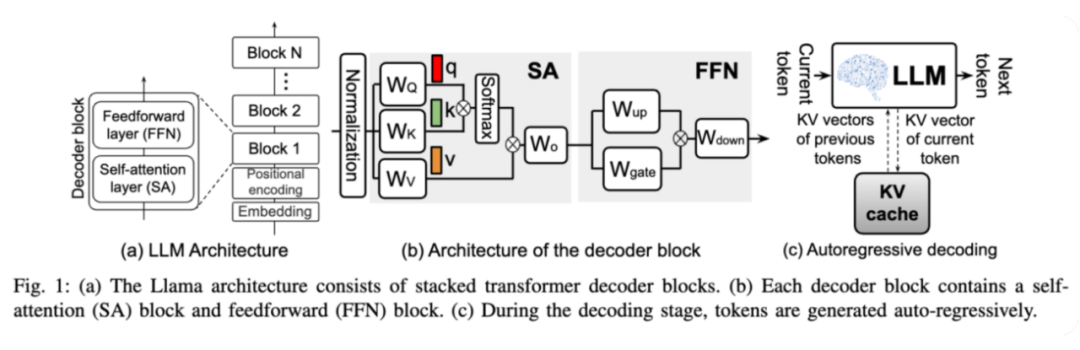
然而,当我们试图将这些模型应用于实际场景时,问题逐渐浮现。
推理过程分为两个阶段:预填充(prefill)和解码(decoding)。预填充阶段可以并行处理输入序列,但解码阶段却成了瓶颈。模型必须按顺序逐个预测每个 Token,依赖于当前和之前的 Token 信息。随着序列长度的增加,这种顺序依赖导致的内存访问延迟愈发显著,严重影响了模型的响应速度。
为了解决这一难题,研究者们提出了多种方法。传统的思路是通过模型压缩、知识蒸馏和架构优化来降低计算成本,但这些方法大多只是在计算层面做文章,未能从根本上解决顺序依赖的问题。
直到“推测式解码”(Speculative Decoding,SD)的出现,才真正打破了这一僵局。
推测式解码是一种创新的两阶段处理方法。它引入了一个小型、快速的草稿模型,先并行生成多个 Token,然后通过目标模型进行验证。草稿模型负责快速生成 Token,摆脱了逐个生成的限制;而目标模型则通过接受或拒绝预测结果来确保输出质量。
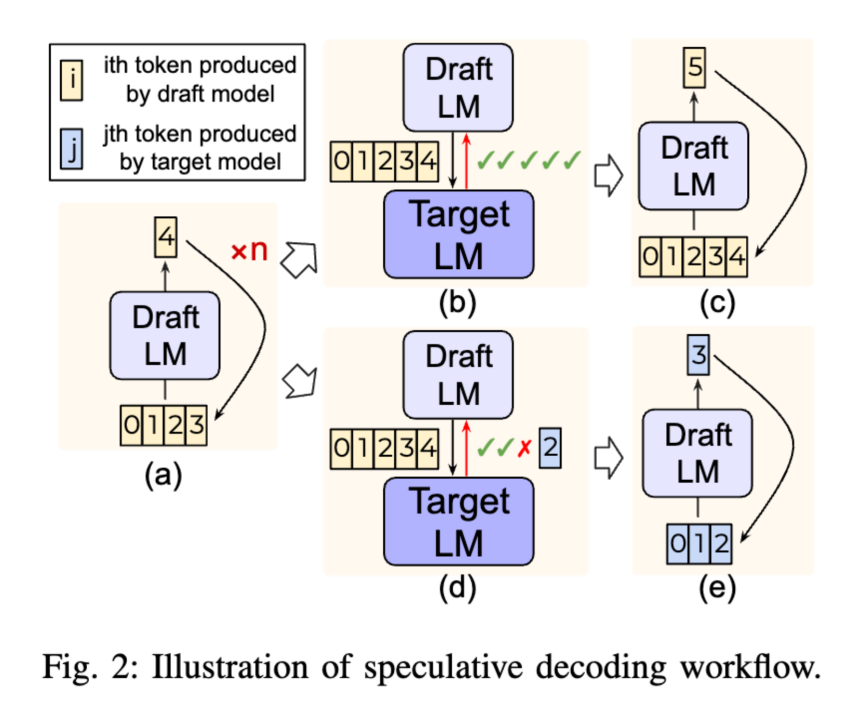
推测式解码是打破自回归模型顺序依赖的一种成功尝试。事实上它属于一个更广泛的生成-精炼方法框架。论文在接下来的章节深入探讨这些方法的分类,如下图所示,分析它们如何在并行生成和输出质量之间权衡,为语言模型的高效应用开辟新的道路。

打破顺序依赖:生成与精炼框架的系统分类
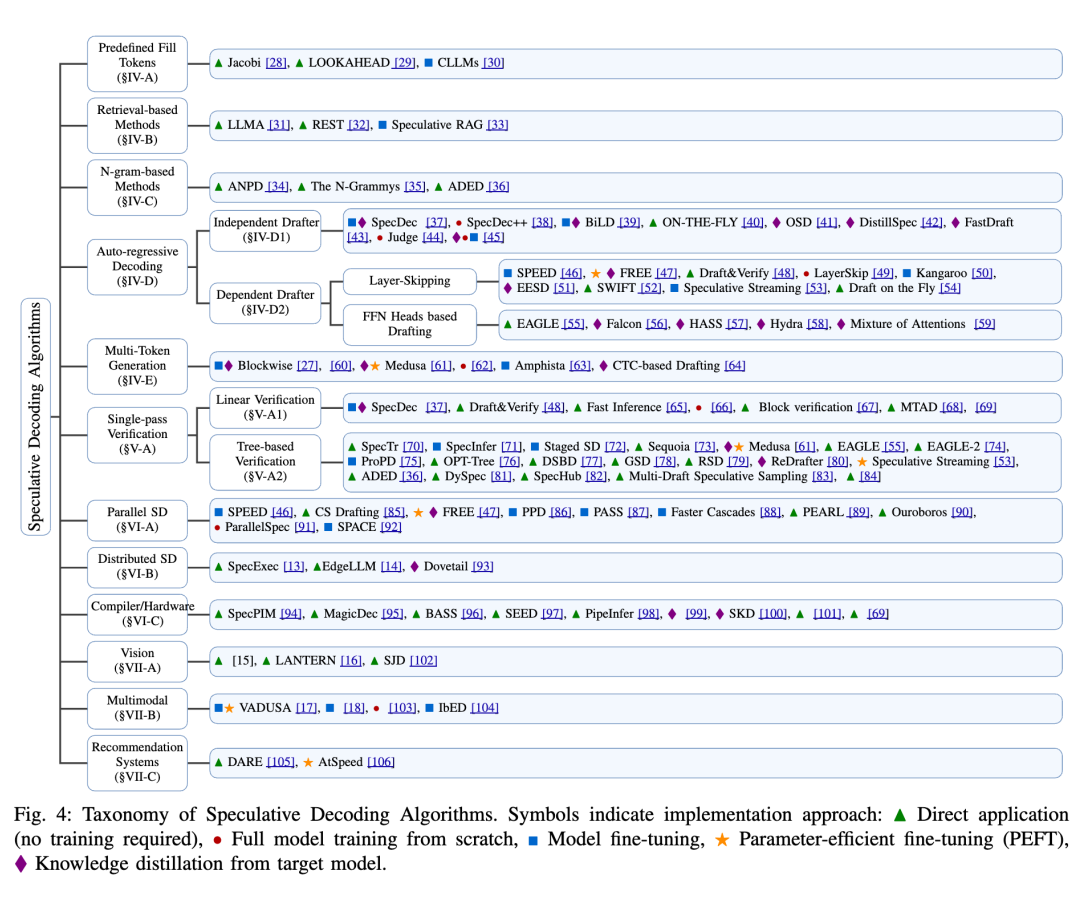
在探索如何打破大型语言模型顺序依赖的过程中,论文提出了一个统一的分类体系,系统地分析了各种方法。这一分类体系基于生成和精炼策略,将相关方法划分为两大核心阶段:序列生成和序列精炼,如下图所示。
这种分类不仅涵盖了传统的推测式解码(Speculative Decoding, SD)方法,还纳入了更多新兴技术,这些技术在并行生成和输出质量之间进行了不同的权衡。
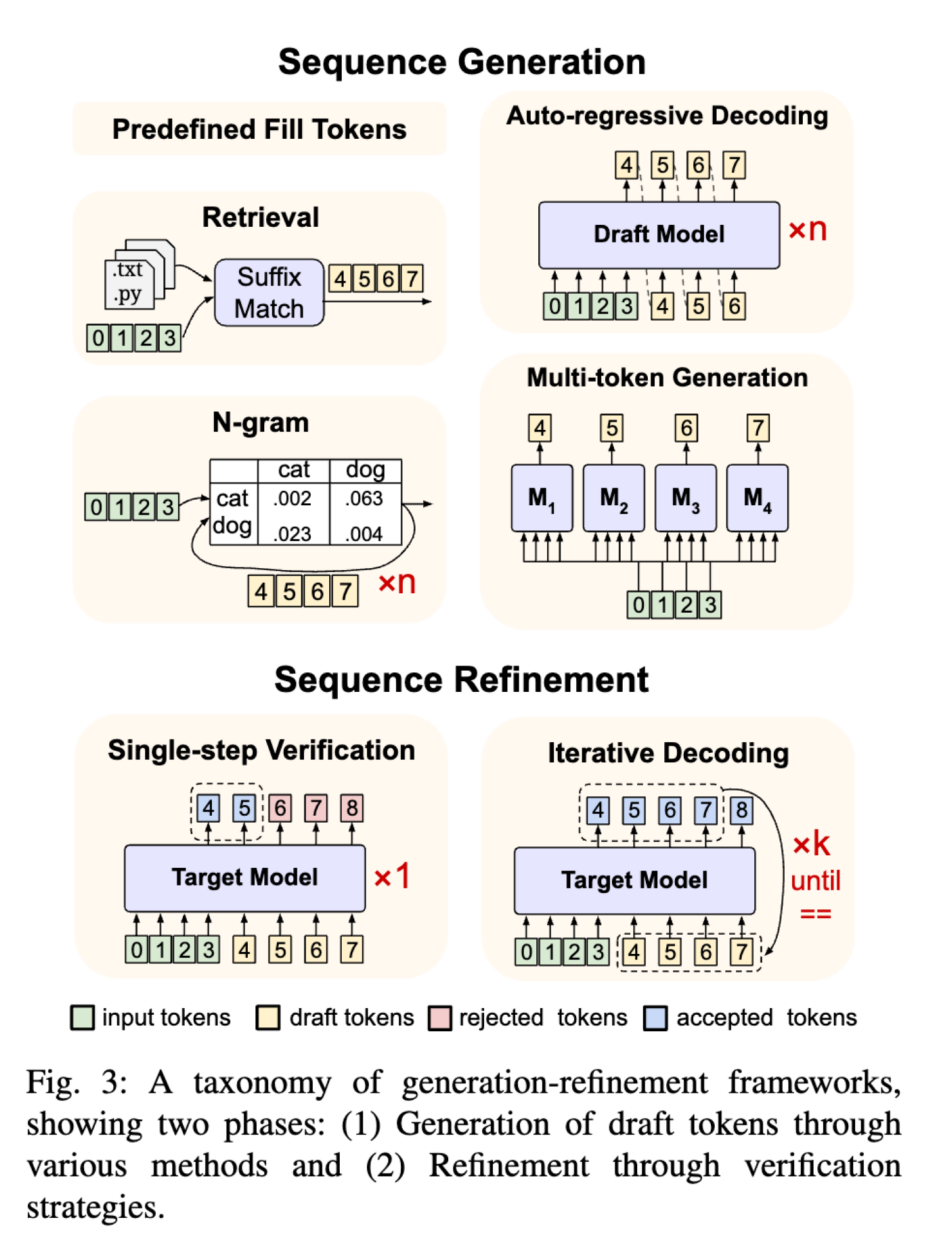
在序列生成阶段,目标是通过不同的策略更高效地生成草稿 Token,而不是依赖于传统自回归解码中单一的大模型。这些策略从简单的随机 Token 采样(结合迭代解码使用)到更复杂的检索式生成和草稿模型预测不等。每种生成方法在计算成本和预测质量之间都有不同的权衡。
随后进入序列精炼阶段,这一阶段决定了如何处理生成的候选 Token。具体来说,可以选择直接接受这些候选 Token(可能会牺牲一些质量),在单次验证中检查部分 Token,或者通过多次迭代逐步优化草稿 Token,直至结果收敛。
这种分类可以清晰地看到不同方法在并行生成和输出质量之间的平衡策略,不仅有助于更好地理解现有技术,还能为未来的研究提供方向,推动语言模型在效率和质量上的双重提升。

序列生成方法:加速语言模型的新思路
在探索如何高效生成语言模型输出的过程中,研究者们提出了多种创新方法。这些方法的核心目标是通过不同的策略快速生成草稿 Token,从而打破传统自回归解码的顺序依赖瓶颈。以下是对这些序列生成方法的详细介绍:
A. 预定义填充 Token
最简单的方法是使用随机初始化或预定义的 Token(例如 PAD)。这种方法虽然计算成本极低,但由于缺乏对上下文的适应性,通常需要后续的精炼迭代来优化结果。
B. 基于检索的方法
基于检索的方法通过利用语言模型输出与参考文档之间的重叠来加速推理,同时保持生成结果的一致性。
例如,LLMA 首次提出了这种思路,通过并行验证 Token 来加速推理。REST 方法则通过从数据存储中检索精确的后缀匹配来生成草稿 Token,并构建前缀树(Trie),其中节点权重反映了 Token 序列的频率。Speculative RAG 则通过微调的专家语言模型生成完整的答案草稿,并通过聚类检索到的文档生成多样化的草稿,使用自一致性评分和自反思评分代替逐词验证,从而提高生成效率。
C. 基于 N-gram 的方法
一些方法利用 N-gram 模式高效生成 Token。例如,ANPD 用自适应 N-gram 系统取代传统草稿模型,根据上下文动态更新预测结果。LOOKAHEAD 通过收集和利用前一次迭代中的 N-gram 作为草稿 Token 进行验证。N-Grammys 进一步发展了这一思路,创建了一个专门的基于 N-gram 的预测系统,无需单独的草稿模型即可运行。
D. 自回归生成
大多数序列生成方法采用自回归草稿生成,即通过较小的模型生成草稿 Token,然后由较大的目标模型进行验证。这种草稿生成范式衍生出多种技术,这些技术在草稿模型与目标模型的交互方式上有所不同。
1)独立草稿生成器
独立草稿生成器是指较小的模型逐个生成 Token,而较大的目标模型随后并行验证这些草稿 Token。例如,SpecDec 首次提出了这种方法,通过为掩码位置设计独立的注意力查询来生成草稿。SpecDec++ 通过在草稿模型上训练一个预测头来估计目标模型接受 Token 的概率,从而动态决定何时停止生成并触发验证。
最近的研究集中在动态适应和置信度监控上,例如 BiLD 在草稿置信度低于阈值时触发目标模型验证,而 ON-THE-FLY 根据预测准确性动态调整窗口大小。
2)依赖草稿生成器
独立草稿生成器的主要缺点是:1)生成草稿 Token 的计算量是固定的,这意味着对于许多“简单”的 Token 来说,计算资源被过度分配;2)目标模型无法复用草稿生成过程中的特征,从而增加了计算量。为解决这些问题,自推测解码方法通过依赖目标模型的子集(层跳过)或扩展(依赖头)来生成草稿 Token。
a)层跳过
Draft&Verify、SWIFT 和 Draft-on-the-Fly 通过在草稿生成过程中选择性跳过一些中间层,快速生成草稿 Token,然后使用完整的语言模型进行验证。
为了提高草稿的准确性,这些方法还设计了基于贝叶斯优化的中间层选择算法。LayerSkip 通过早期退出机制动态输出不同深度的目标模型 Token,而 Kangaroo 则通过浅层子网络生成草稿,并使用轻量级适配器模块弥合与完整模型的性能差距。
b)依赖头
依赖头方法通过在目标模型的隐藏状态上添加轻量级前馈预测头,直接生成后续 Token,无需再次通过整个目标模型。例如,EAGLE 使用训练好的头,从目标模型的隐藏状态中生成后续草稿 Token。Hydra 则为每个草稿 Token 位置使用多个解码器。
最近的改进集中在提高并行 Token 生成和注意力机制上,例如 Falcon 引入了半自回归框架,结合 LSTM 层和放松的因果掩码自注意力,每个前向传播生成多个 Token。
E. 多 Token 预测
多 Token 预测方法通过在模型上添加多个解码头,同时预测多个未来 Token。
例如,Medusa 提出了一种参数高效的方案,在预训练语言模型上微调轻量级解码头,每个头专门预测序列中特定的未来位置。Amphista 使用双向自注意力机制,同时考虑过去和未来的预测,而 CTC Drafting 则采用连接时序分类(CTC)和空白 Token 来优化生成过程。

系统级优化和应用扩展
为了将 Speculative Decoding 技术应用于不同的计算环境,研究者们还提出了多种系统级优化策略。这些策略包括:
1)并行化:通过同时运行草稿模型和目标模型,实现 Token 生成和验证的并行化。例如,CS Drafting 和 PaSS 等方法通过优化草稿模型和目标模型的交互,显著提高了推理速度;
2)分布式计算:针对边缘设备等资源受限的环境,研究者们设计了如 SpecExec 和 EdgeLLM 等方法,通过在多个设备上分配计算任务,实现高效的模型推理;
3)硬件加速:通过利用 GPU、PIM 等硬件资源,研究者们开发了如 SpecPIM 和 MagicDec 等方法,进一步提高了 Speculative Decoding 的效率。
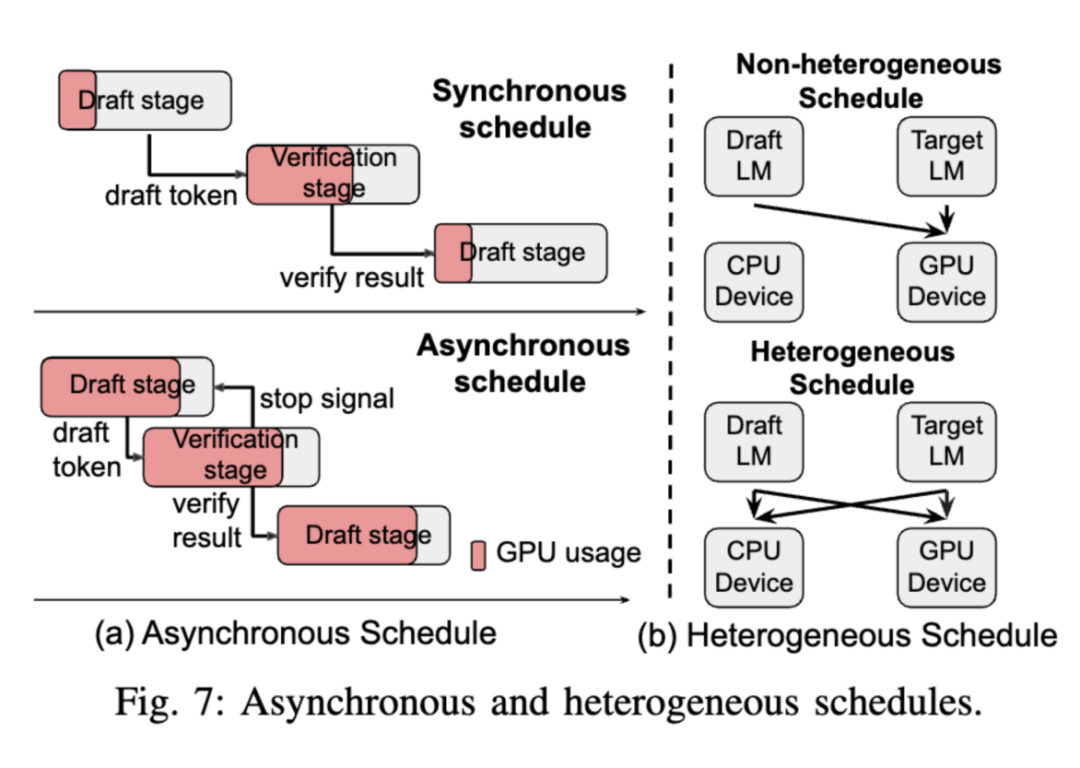

SD 的跨领域应用
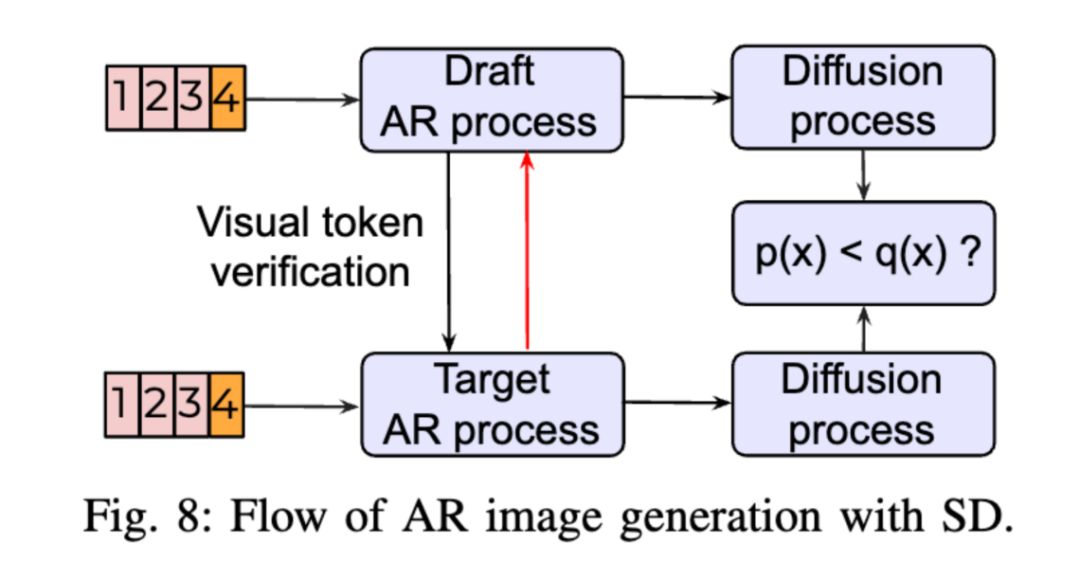
除了文本生成领域,Speculative Decoding 技术还被应用于图像生成、语音合成和多模态模型中。例如,在图像生成中,通过减少生成视觉 Token 所需的推理步骤,显著提高了自回归图像生成的效率。在语音合成中,VADUSA 等方法利用 Speculative Decoding 加速了自回归文本到语音系统的推理过程。

未来研究方向
作者认为,尽管 Speculative Decoding 技术已经在多个领域取得了显著进展,但仍面临一些挑战。例如,如何在不同的模态之间构建统一的理论框架,以更好地平衡并行性和输出质量;如何优化系统级实现,以适应不断增长的模型规模和复杂性。
此外,随着多模态模型和生成式人工智能的快速发展,Speculative Decoding 技术的应用场景也在不断拓展。例如,在多模态生成任务中,如何通过高效的解码策略实现高质量的图像、语音和文本生成,将是未来研究的重要方向。
(文:PaperWeekly)